没有SCALA的东东,玩不起哈。
./spark-shell
从文件生成一个DRIVER?
val logFile = sc.textFile("hdfs://192.168.14.51:9000/usr/root/spark-root-org.apache.spark.deploy.master.Master-1-hs51.out")

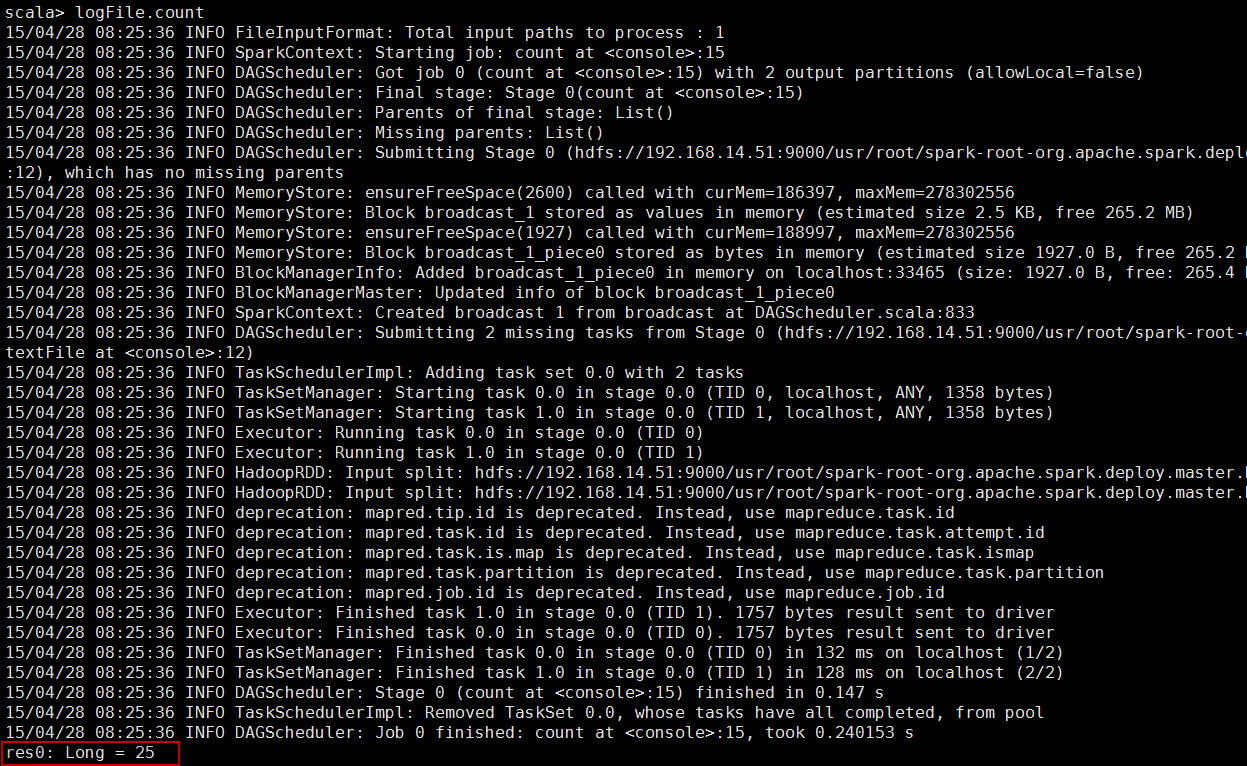
看看这个东东里包含条数据?
logFile.count
来来来,作个过滤,再显示有多少条:
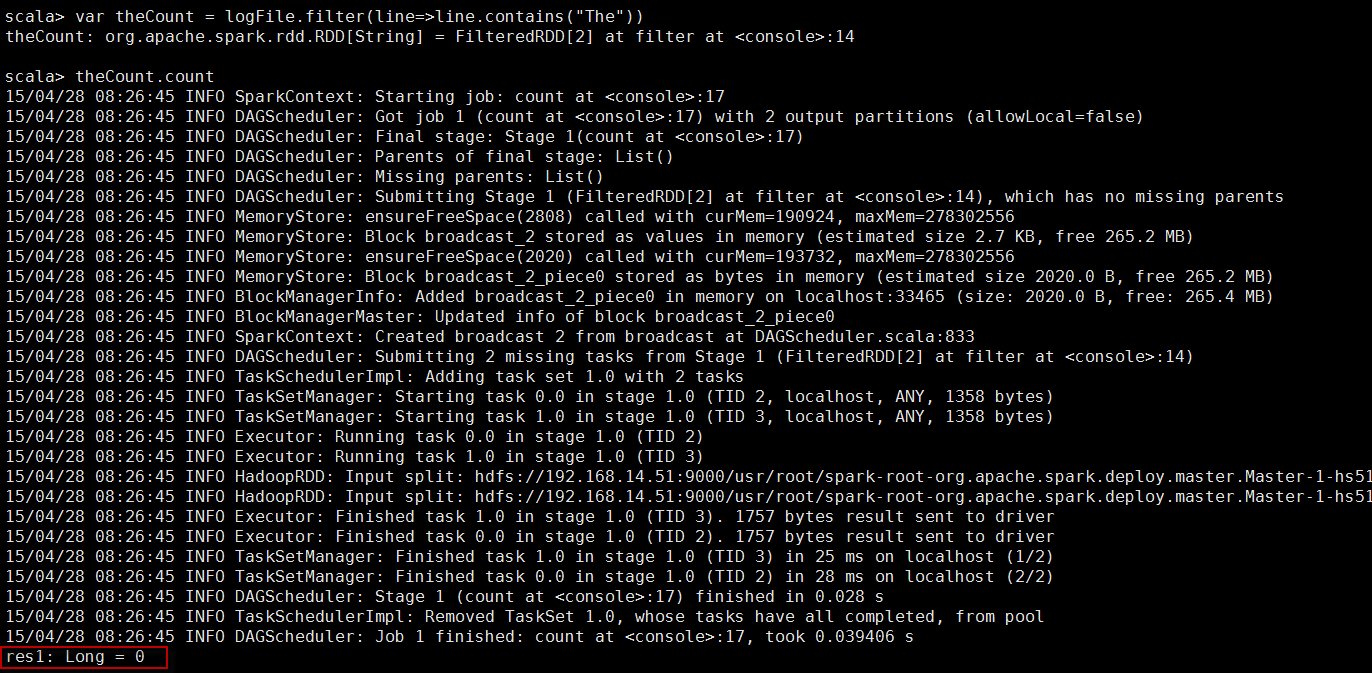
var theCount = logFile.filter(line=>line.contains("The"))
theCount.count