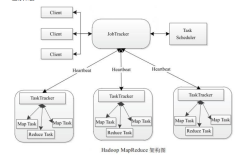
jstorm 是阿里巴巴开源的基于storm采用Java重写的一套分布式实时流计算框架,使用简单,特点如下:
开发非常迅速: 接口简单,容易上手,只要遵守Topology,Spout, Bolt的编程规范即可开发出一个扩展性极好的应用,底层rpc,worker之间冗余,数据分流之类的动作完全不用考虑。
扩展性极好:当一级处理单元速度,直接配置一下并发数,即可线性扩展性能
健壮:当worker失效或机器出现故障时, 自动分配新的worker替换失效worker
数据准确性: 可以采用Acker机制,保证数据不丢失。 如果对精度有更多一步要求,采用事务机制,保证数据准确。
优点:
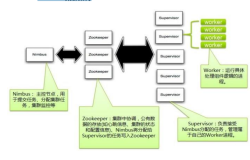
Nimbus 实现HA
彻底解决Storm雪崩问题:底层RPC采用netty + disruptor保证发送速度和接受速度是匹配的
新增supervisor、Supervisor shutdown时、提交新任务,worker数不够时,均不自动触发任务rebalance
新topology不影响现有任务,新任务无需去抢占老任务的cpu,memory,disk和net
减少对ZK的访问量:去掉大量无用的watch;task的心跳时间延长一倍;Task心跳检测无需全ZK扫描
Worker 内部全流水线模式:Spout nextTuple和ack/fail运行在不同线程
性能:采用ZeroMq, 比storm快30%;采用netty时, 和storm快10%,并且稳定非常多
任务
jstorm使用起来很简单,遵循Topology,Spout, Bolt的编程规范就可以,在下面的例子中将一步步完成这些。例子也很简单,在spout中不断产生自增的int数组,bolt接受到数值后打印出日志,并插入到hbase中。
安装:
参考另一篇博客
public class TestSpout extends BaseRichSpout {
private static final Logger LOGGER = LoggerFactory.getLogger(TestSpout.class);
static AtomicInteger sAtomicInteger = new AtomicInteger(0);
static AtomicInteger pendNum = new AtomicInteger(0);
private int sqnum;
SpoutOutputCollector collector;
@Override
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
sqnum = sAtomicInteger.incrementAndGet();
this.collector = collector;
}
@Override
public void nextTuple() {
while (true) {
int a = pendNum.incrementAndGet();
LOGGER.info(String.format("spount %d,pendNum %d", sqnum, a));
this.collector.emit(new Values("xxxxx:"+a));
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("log"));
}
/**
* 启用 ack 机制,详情参考:https://github.com/alibaba/jstorm/wiki/Ack-%E6%9C%BA%E5%88%B6
* @param msgId
*/
@Override
public void ack(Object msgId) {
super.ack(msgId);
}
/**
* 消息处理失败后需要自己处理
* @param msgId
*/
@Override
public void fail(Object msgId) {
super.fail(msgId);
LOGGER.info("ack fail,msgId"+msgId);
}
}public class TestBolt extends BaseRichBolt {
private static final Logger LOGGER = CustomerLoggerFactory.LOGGER(TestBolt.class);
OutputCollector collector;
@Override
public void prepare(Map stormConf, TopologyContext context,
OutputCollector collector) {
this.collector = collector;
}
@Override
public void execute(Tuple input) {
String xx = input.getString(0);
LOGGER.info(String.format("receive from spout ,num is : %d", xx));
// 发送ack信息告知spout 完成处理的消息 ,如果下面的hbase的注释代码打开了,则必须等到插入hbase完毕后才能发送ack信息,这段代码需要删除
this.collector.ack(input);
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}public class TestTopology implements ILogTopology {
@Override
public void start(Properties properties) throws AlreadyAliveException, InvalidTopologyException, InterruptedException, IOException {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("testspout", new TestSpout(), 1);
builder.setBolt("testbolt", new TestBolt(), 2).shuffleGrouping("testspout");
Config conf = ConfigUtils.getStormConfig(properties);
conf.setNumAckers(1);
StormSubmitter.submitTopology("testtopology", conf, builder.createTopology());
System.out.println("storm cluster will start");
}
}经过上面的三个步骤,一个最简单的jstorm应用就开发完成了,接下来通过编译、打包完后,生成jar文件 jstorm-hbase-demo-0.1.jar ,将此jar文件在jstorm集群的nimbus机器上提交即可: jstorm jar jstorm-hbase-demo-0.1.jar com.xirong.demo.BootStrap config.properties