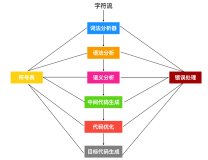
有时候感觉很无助,迷茫的时候,没有精神支柱的时候。【自暴自弃】
进入人生低谷的时候,找不到方向的时候, 总会出现一些让我兴奋和受到鼓舞的东西。
在一次次的脱变中,发现自己需要学习的东西还很多,很多... ..
我感觉不经历一些事情,就不会学会一些事情,不怕你做错事情,就怕你不肯改错。
我又接触词法分析的另一种词法分析算法[转换表],书中如此描述“理解了此算法思想,也就理解了词法分析器的核心”.
仔细看了30分钟,反复琢磨,终于理解了此算法的真谛,让我狠高兴,很兴奋,在编程的学习道路又燃起了一点星星之火.
下面是我学习一本编译原理书籍做的笔记,我感觉这本书籍比龙书和编译原理及实践要通俗很多,适合我这样智商不高的人看。
单词存储三元组【单词ID,单词备注,单词行号】
单词行号:单词所在的源程序文件名,单词在源程序文件中得行号。
单词可分为三类:标识符,常量,系统单词。
标识符(标识符的ID,用户标识符名,单词行号):所有用户标识符使用同一ID,
而在“单词备注”域中存储用户标识符的实际名字。
常量(常量的ID,在常量表中的位置,单词行号):常量ID是根据常量类型确定的,
即相同数据类型的常量的ID是相同的。在词法分析阶段,只将常量分为整型,实型,字符串
等类型,无须详细区别是哪种详细类型(例如:integer, shortint等)。常量ID可用于指示常量数据类
型。在词法分析时,对识别所得到的常量还必须登录入常量表,便于语法分析使用。在常量
的三元组中必须记录该常量在常量表的位置。
系统单词“即关键字,运算符,界符”(ID,不使用,单词行号):每一个系统单词都
拥有一个唯一的ID编号。语法分析器只需根据ID就可以区别是哪个系统单词了。而系统单词的
单词存储三元组中“单词备注”域是不使用的。不难发现,词法分析器对于关键字,运算符,
界符单词的处理是完全相同的。因此,这三类合并为系统单词类。
词法分析【一个独立阶段,独立的一遍】:
一个独立阶段:就是指将词法分析器作为一个函数,由语法分析器调用。
每次调用语法分析器只识别一个单词,然后将单词直接传递给语法给语法
分析器。整个过程由语法分析器控制,在语法分析过程中,进行单词识别。
独立的一遍:词法分析器将整个源程序文件扫描一次,识别出所有的单词,然后将源程序
以单词流的方式传递给语法分析器处理。
词法分析器主要包括:构造转换图与转换表,设计词法分析器算法,
词法分析器的核心就是依据转换图识别单词。
数据结构: 转换表,关键字表,常量表及其单词流。
1.转换表:是词法分析器的核心。通常用二维数组表示,数组元素可以
根据实际情况而定。
2.关键字表:词法定义识别单词。完成标识符后再查找关键字表,确定该标识符是否为关键字。
关键字表一般包含两个字段:关键字名,ID。由于每次都要查找关键字表,所以查找的效率至关重要,
常用的查找算法比较多【顺序,折半,哈希表,B-树,B+树等】,MAP是内核中得一种红黑树结构,
查找效率近似于哈希表,属于比较高校的。
3.单词流:
struct Token
{
int ... //单词类型,ID。
string .... //单词备注
LineInfo ... //单词行号信息
}
struct LineInfo
{
int .... //单词所在行号
string ... //单词所在的源程序文件名
}