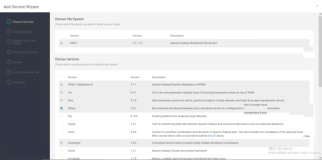
新建maven项目
导入依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.100</groupId>
<artifactId>MRHbasetest</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-client -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.2.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hbase/hbase-server -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.2.0</version>
</dependency>
</dependencies>
</project>
添加配置文件
(core-site.xml,hbase.site.xml,log4j.properties)
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/temp</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
<description>The directory shared by RegionServers.</description>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
</configuration>log4j.properties
# Global logging configuration
log4j.rootLogger=INFO, stdout
# MyBatis logging configuration...
log4j.logger.org
.mybatis.example.BlogMapper=TRACE
# Console output...
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
代码
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
//计算wordcount 把结果保存到hbase里面
//bd17:wc 列簇:c 列名称 count 用单词table
public class MRToHbase {
public static class MrToBaseMap extends Mapper<LongWritable, Text, Text, IntWritable> {
private static final IntWritable ONE = new IntWritable(1);
private String[] info;
private Text outputKey = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
info = value.toString().split("\\s");
for (String word : info) {
if(word.length()!=0){
outputKey.set(word);
context.write(outputKey, ONE);
}
}
}
}
// reducer 类需要继承自hbase api 中提供的tablereducer 类型
public static class MrToHBaseReduce extends TableReducer<Text, IntWritable, NullWritable> {
private int sum;
private NullWritable outputKey = NullWritable.get();
private Put outputValue;
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, NullWritable, Mutation>.Context context)
throws IOException, InterruptedException {
sum = 0;
for (IntWritable value : values) {
System.out.println(value.toString());
sum += value.get();
// 构建put对象 即往hbase里面插入一条数据的具体内容
}
// 构建put对象 即往hbase里面插入一条数据的具体内容
outputValue =new Put(Bytes.toBytes(key.toString()));
outputValue.addColumn(Bytes.toBytes("c"), Bytes.toBytes("count"), Bytes.toBytes(sum+""));
context.write(outputKey, outputValue);
}
}
//main 方法启动 并且设置hbase链接和输出格式
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//使用hbaseconfiguration 来创建job的配置对象
Configuration configuration =HBaseConfiguration.create();
Job job =Job.getInstance(configuration);
job.setJarByClass(MRToHbase.class);
job.setJobName("wordcount写入到hbase");
job.setMapperClass(MrToBaseMap.class);
job.setReducerClass(MrToHBaseReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Mutation.class);
//使用TableMapReduceUtil 工具类来做与hbase 交互的mr的初始化设置
TableMapReduceUtil.initTableReducerJob("bd17:wc", MrToHBaseReduce.class, job);
FileInputFormat.addInputPath(job, new Path("/reversetext/reverse1.txt"));
System.exit(job.waitForCompletion(true)?0:1);
}
}