
在2017年的下半年谈论大数据似乎已经没有什么新意,甚至有些令人生厌了,毕竟这个词在中国已经流行太久,形形色色的产品、平台和公司早已贴满了大数据标签,而真正有价值的创新永远都是少数。
行业对于大数据的认知开始变得更加理性和客观,这是一种成熟的表现。但如果因此就认为大数据时代已经进入风平浪静的“发展期”,那么我们很可能会错过一场更加波澜壮阔的变革。
被忽视的非结构化数据
在过去几年,大数据产业更多关注的是如何处理海量、多源和异构的数据,并从中获得价值,而其中绝大多数都是结构化数据。不可否认,这些数据的体量足够巨大,然而我们今天必须承认这些只是冰山一角——行业公认的数据是,结构化数据仅占到全部数据量的20%,其余80%都是以文件形式存在的非结构化和半结构化数据,包括各种办公文档、图片、视频、音频、设计文档、日志文件、机器数据等,这些数据如同“暗网”一般地沉默着。可以想象,如果我们只阅读了一本书的五分之一,又如何正确理解这本书的含义呢?
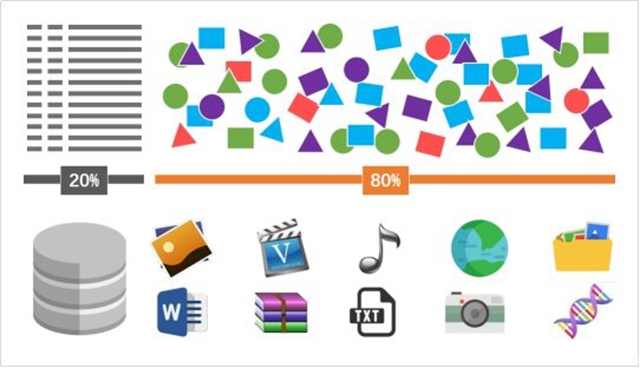
非结构化数据占数据总量的80%以上
事实上,过去大家并非有意忽视非结构化数据,而是受到一些条件的制约和影响,不得不策略性地“放弃”这部分数据:
1、存储资源受限,大量数据被抛弃
非结构化数据体量巨大并且产生速度非常快,需要占用大量的存储资源,而存储成本降低也只是最近几年的事情,大量数据还没有加以分析和利用就被早早抛弃,以便为新产生的数据腾出空间;
2、数据体量大,获取和流转困难
对于已经保留下来的非结构化数据,真要去使用和处理它,依然是一项不讨好的“体力活儿”。由于体量、距离和网速的原因,非结构化数据并不容易获得,更不要说被灵活地放入业务分析和处理流程之中了;
3、缺乏处理分析的技术手段
非结构化数据的价值密度相对较低,缺乏有效的技术对非结构化数据进行处理和分析,面对海量文件数据束手无策。相比之下,结构化数据更容易入手,优先处理结构化数据也是非常合情合理的。
结构化数据的局限性
然而在对结构化数据进行分析和挖掘的过程中,我们越来越多地发现一些新的问题,甚至已经造成很大困扰:
1、结构化数据可能在“说谎”
结构化数据的优点在于便于统计和处理,包括结构化数据的形成本身就可能来自于统计。而统计并不能代表全部信息,必然存在一定程度的损耗,并带来误导。这也是为什么有些时候明明看似得出了合理的结论,却不能有效改进我们的业务。
相比之下,非结构化数据则“诚实”得多,通常包含了完整而连续的信息,其中充满了大量微小但却非常关键的细节,而这些数据将成为我们信息来源的重要组成部分,甚至会起到决定性的作用。
2、仅有结构化数据的世界简直太乏味了
人类先天是感性的生物,我们都喜欢丰富多彩的世界,它应该是立体而全方位的,包含了多种感官的信息和刺激,而不仅仅是枯燥的数字。很多时候我们发现,无论是从受众的接受程度还是所传递的信息量来看,即便是再酷炫的统计图表,也抵不过一分钟生动的视频。这一点从各大企业官方网站的变化中,就能明显地感受到。
另外,值得注意的是,人类对于结构化数据的运用由来已久。比如在企业级市场,包括ERP、CRM、MRP等管理软件一向都属于这一范畴,而所谓的大数据应用只是一个更高级的阶段而已。因此,从实际的技术发展和应用水平的角度来看,结构化数据市场是相当成熟的,也会愈发平稳。比如赛迪在今年5月发布的一份报告就显示,以ERP和CRM为代表的结构化数据市场增速放缓,相比之下非结构化数据市场的代表ECM(企业内容管理)则表现出强劲的增长动力。我想这也在一定程度上反映了市场的看法和整体的趋势。
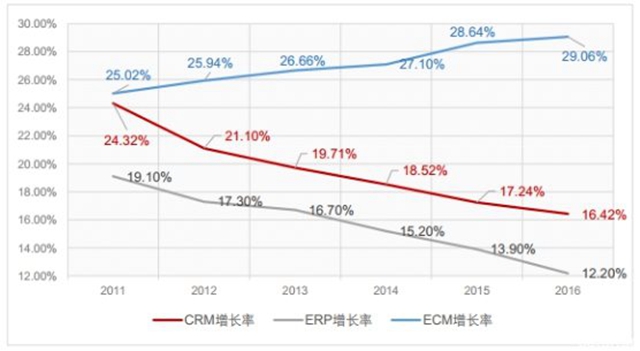
2011-2016年CRM软件、ERP软件和ECM软件市场规模增速对比
未来世界将是非结构化的
世界随时都在发生变化,时至今日,对非结构化数据的管理和应用走到了一个重要关口。
一方面得益于存储成本的下降。随着存储技术和公有云平台的不断发展和成熟,用户可以拥有充足并且弹性可扩展的存储资源,用于存放更大量的非结构化数据,从而使得非结构化数据的积累和应用成为可能。
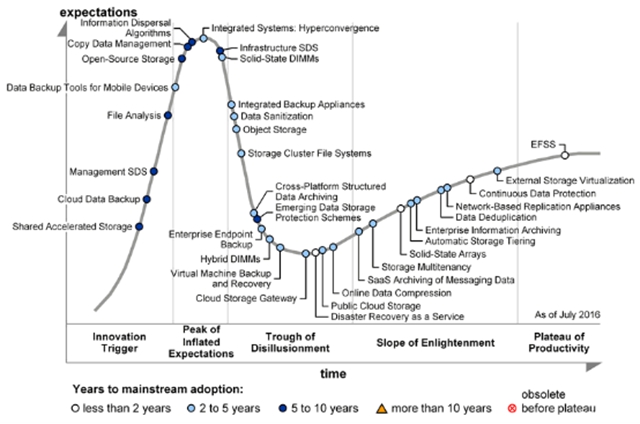
Hype Cycle for Storage Technologies,2016,Gartner
另一方面,新兴技术的快速发展也提高了行业对非结构化数据的重视程度。比如物联网、工业4.0、视频直播等领域的发展产生了更多的非结构化数据,而人工智能、机器学习、语义分析、图像识别等技术方向则需要大量的非结构化数据来开展工作,包括数据库系统也在不断向非结构化延伸。一推一拉之间,都要求我们以新的视角和方法去面对非结构化数据。
因此,未来对大数据的分析和应用将从结构化数据向非结构化数据转移,无论是消费级市场还是企业级市场,都会试图生产和采集更多的非结构化数据,并从中发掘商业价值。谁能够最先积累更多的数据,谁能够最先从中学到知识,谁就会领先一步,率先占领未知的空间。
非结构化数据带来的新机会
作为大数据产业的重要组成部分,甚至应该是产业的主体,非结构化数据一旦受到重视,注定将带来前所未有的发展机遇,吹响大数据时代下半场比赛的哨音。
在结构化数据为主导的阶段,大量的企业通过围绕结构化数据提供产品和服务,最终成长为行业巨头,并建立了稳固的竞争壁垒。而新兴的非结构化数据市场将给更多企业,尤其是创新型企业,带来百年一遇的弯道超车的机会。想一想特斯拉的电动汽车,你一定会理解我说的意思。
同时,由于非结构化数据的自身特征与结构化数据有着本质的差异,导致这场变革将是全链条的——从数据的生产、存储、流转、加工、处理,到最终的分析、应用和输出,无不和传统模式有着天壤之别。而在其中任何一个环节,都可能出现颠覆性的技术和模式,甚至形成独立的规模化赛道。因此,这一过程中所产生的机会和市场空间将是巨大的,我们甚至已经能够预见到一个百花齐放的新时代。
可以想象,当我们对非结构化数据有了足够的控制力,并能够充分利用的时候,我们得到的将是一个更加完整和富有生命力的世界。这个世界,事实上已经并不遥远。
本文作者:朱旭光
来源:51CTO
