
Lucene是一个高性能、可伸缩的信息搜索(IR)库。它可以为你的应用程序添加索引和搜索能力。Lucene是用Java实现的、成熟的开源项目,是著名的Apache Jakarta大家庭的一员,并且基于Apache软件许可。
Lucene的检索算法属于索引检索,即用空间来换取时间,对需要检索的文件、字符流进行全文索引,在检索的时候对索引进行快速的检索,得到检索位置,这个位置记录检索词出现的文件路径或者某个关键词。Lucene的索引是用文件存储,Lucene中的文件操作都是通过Directory来实现,下面来介绍一下Lucene有关文件存储和读取的有关技术。
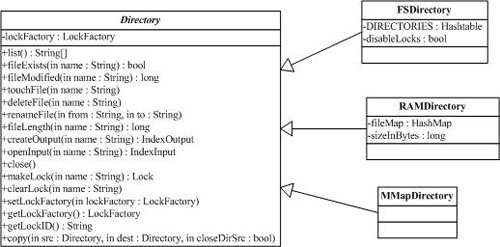
1 数据存储类Directory(org.apache.lucene.store.Directory)
一个Directory对象是一系列统一的文件列表(a flat list of files)。文件可以在它们被创建的时候一次写入,一旦文件被创建,它再次打开后只能用于读取(read)或者删除(delete)操作,并且同时在读取和写入的时候允许随机访问(random access)。
在这里并不直接使用Java I/O API,但是更确切地说,所有I/O操作都是通过这个API处理的。这使得读写操作方式更统一,如基于内存的索引(RAM-based indices)的实现(即RAMDirectory)、通过JDBC存储在数据库中的索引、将一个索引存储为一个文件的实现(即FSDirectory)。
Directory的锁机制是一个LockFactory的实例实现的,可以通过调用Directory实例的setLockFactory()方法来更改。
如下图是org.apache.lucene.store.Directory类以及它的一些子类的类图:
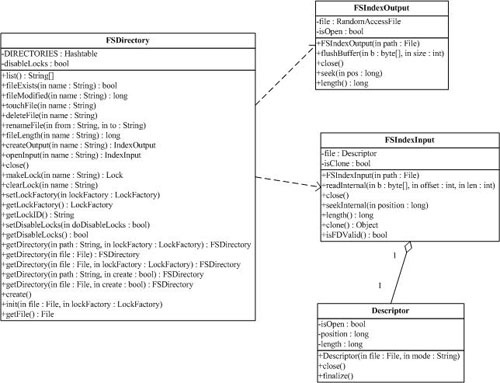
(1) org.apache.lucene.store.FSDirectory
FSDirectory类直接实现Directory抽象类为一个包含文件的目录。目录锁的实现使用缺省的SimpleFSLockFactory,但是可以通过两种方式修改,即给getLockFactory()传入一个LockFactory实例,或者通过调用setLockFactory()方法明确制定LockFactory类。
目录将被缓存(cache)起来,对一个指定的符合规定的路径(canonical path)来说,同样的FSDirectory实例通常通过getDirectory()方法返回。这使得同步机制(synchronization)能对目录起作用。
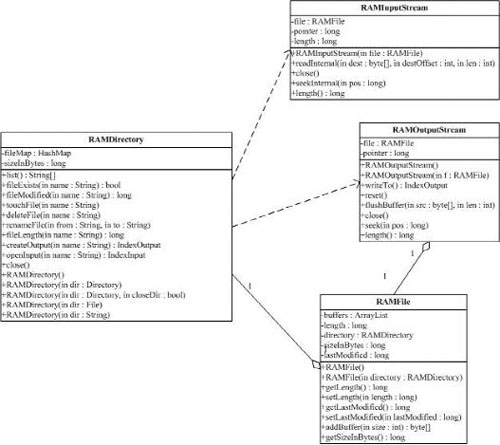
(2) org.apache.lucene.store.RAMDirectory
RAMDirectory类是一个驻留内存的(memory-resident)Directory抽象类的实现。目录锁的实现使用缺省的SingleInstanceLockFactory,但是可以通过setLockFactory()方法修改。
(3) org.apache.lucene.store.MMapDirectory
Lucene和Solr开始在64位的Windows和Solaris系统中默认使用MMapDirectory。简单说MMapDirectory就是把Lucene的索引当作swap file来处理。mmap()系统调用让OS把整个索引文件映射到虚拟地址空间,这样Lucene就会觉得索引在内存中。然后Lucene就可以像访问一个超大的byte[]数据(在Java中这个数据被封装在ByteBuffer接口里)一样访问磁盘上的索引文件。
Lucene在访问虚拟空间中的索引时,不需要任何的系统调用,CPU里的MMU和TLB会处理所有的映射工作。如果数据还在磁盘上,那么MMU会发起一个中断,OS将会把数据加载进文件系统Cache。如果数据已经在cache里了,MMU/TLB会直接把数据映射到内存,这只需要访问内存,速度很快。
程序员不需要关心paging in/out,所有的这些都交给OS。而且,这种情况下没有并发的干扰,唯一的问题就是Java的ByteBuffer封装后的byte[]稍微慢一些,但是Java里要想用mmap就只能用这个接口。还有一个很大的优点就是所有的内存issue都由OS来负责,这样没有GC的问题。因此在64位平台上的Lucene,尽量使用MMapDirectory。
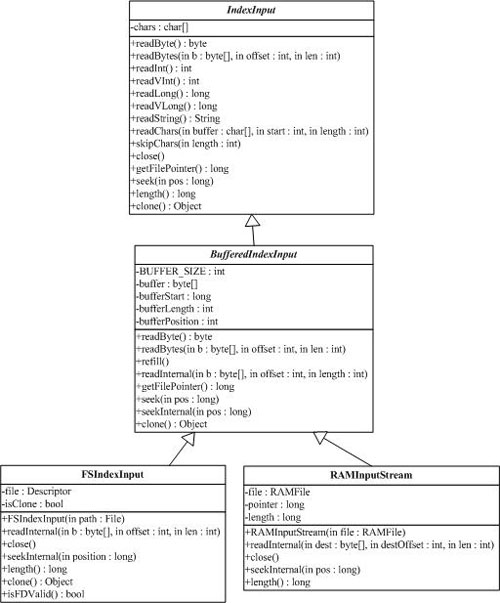
2 文件读取类 IndexInput(org.apache.lucene.store.IndexInput)
IndexInput类是一个为了从一个目录(Directory)中读取文件的抽象基类,是一个随机访问(random-access)的输入流(input stream),用于所有Lucene读取Index的操作。BufferedIndexInput是一个实现了带缓冲的IndexInput的基础实现。
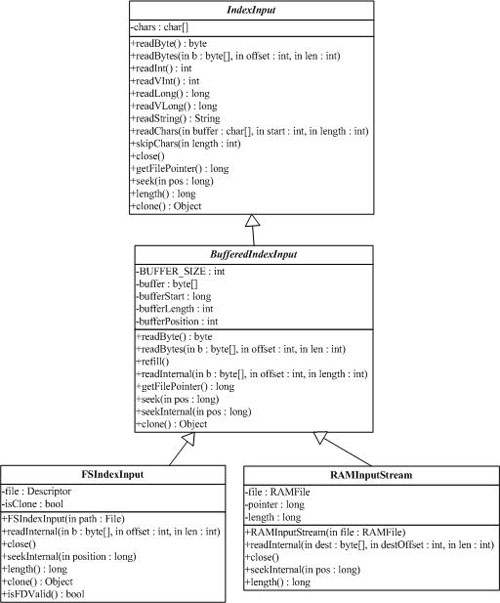
3 文件写入类IndexOutput(org.apache.lucene.store.IndexOutput)
IndexOutput类是一个为了写入文件到一个目录(Directory)中的抽象基类,是一个随机访问(random-access)的输出流(output stream),用于所有Lucene写入Index的操作。BufferedIndexOutput是一个实现了带缓冲的IndexOutput的基础实现。RAMOuputStream是一个内存驻留(memory-resident)的IndexOutput的实现类。
作为一种检索系统框架,Lucene并不直接提供系统的实现,而仅仅是系统框架而已。因此,为了构建一个真正可用的全文检索系统,开发人员必须熟悉Lucene的基本框架以及API,这样才能进行高效的开发。
这一需求要求了Lucene具备一种简明、方便的构架与函数接口来方便用户(即开发人员)的使用。这体现了Lucene需要很高的易用性(usability)。 不仅如此,开源是Lucene的一个重大属性。相比Google的pagerank搜索方案,Lucene必须不断改进其算法以及各种辅助措施来使得其运行更加高效,并支持多种语言等。因此,Lucene必须具备很好的可修改性(modifiability)。
本文作者:刘光敏
来源:51CTO





