[ 版权申明:本文系作者原创,转载请注明出处]
文章出处: http://blog.csdn.net/sdksdk0/article/details/52424578
作者:朱培 ID:sdksdk0 邮箱: zhupei@tianfang1314.cn
--------------------------------------------------------------------------------------------
struts2和hibernate分别都是框架是JavaEE中的三大框架之一,同时也是非常“老”的两个框架,现在很多已经转换为springMVC和mybatis来开发javaee应用了,既然sturts2和hibernate可以成为经典,那肯定还是有其存在的必要的,对于一些老的项目来说,如果我们要对其进行维护什么的,我们还是需要了解struts2和hibernate的用法什么的。从使用角度上面来说的话hibernate对于数据库的查询什么的还是有一定的不足之处的,虽然说写HQL语句更为简洁一点,但是其依然有瓶颈的。虽然慢慢的在一些新的项目中struts2和hibernate可能会用的很少或者被替换为其他的,但是其框架的思想还是对我们很有借鉴意义的!使用框架比以前直接用MVC模式的话,解耦合了很多,让程序更为健壮,从这个角度来说还是非常好的。一个设计良好的框架一般分为三层:(1)接口层,这一层要尽量使用interface,在这一层中你要考虑到你现在的、将来的可能支持的功能,但不需要去实现它,只定义到接口层次就可以了。如Struts中的插件接口PlugIn。(2)抽象层,这一层要针对你当前的需求做定制,对你的需求中的通用逻辑做实现。这一层应该出现大量的抽象类。如Struts中的ActionServlet、Action和ActionForm等类。(3)实现层,不用说了,把前面两层没有做掉的事情在这一层都做了吧。如Struts中后台实现的各种功能。
以下内容是struts2和hibernate的精华知识点,如果有哪个地方的知识还很模糊的话建议再去复习一下吧!
struts2篇
简介
Struts 是 Apache 软件基金会(Apache Software Foundation)资助的一个为开发基于MVC模式应用架构的开源框架,是利用Java Servlet和JSP、XML等方面的技术来实现构建Web应用的一项非常有用的技术,它也是基于MVC模式的Web应用最经典框架。
struts和struts2只是名字相似,没有其他关系。
给予spring AOP思想的拦截器机制,更易扩展。
<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>struts2</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
执行过程
动作类就是一个POJO,
实现Action接口,可以使用接口中定义的常量:
SUCCESS:一切ok,不返回任何的结果视图。
ERROR:出错了,服务器忙等。
INPUT:数据回显。
LOGIN:要求登陆。
动作类一般选择继承com.opensymphony.xwork2.ActionSupport。
可以使用Action接口中的常量,提供用户输入验证功能,消息国际化。
Action:定义一个动作, name:动作名称,对应用户的请求名称 class:框架要实例化的动作名称,全名称。 method:执行的动作类的方法,默认是execute。
动作类的动作方法调用。
DMI动态方法调用。 国际化、用户输入数据的校验。
常用常量 default.properties属性。
在动作类中使用servlrt。
ServletActionContext
通配符:适合有规律的。 多个struts.xml中用包含进来。 在动作类中访问servlet的API: ServletActionContext的静态方法、动作类实现ServletRequestAware接口,注入的方式传递进来的,由一个叫servletConfig的拦截器完成的。
结果视图: /success.jsp
dispatcher:转发到一个页面。默认
redirect:重定向到一个页面
chain:转发到另外一个动作
redirectAction:重定向到另外一个动作
结果视图
局部逻辑视图:服务于当前的动作。
<action name="action1" >
局部逻辑视图
<result name="success">/success.jsp</result>
<result name="error">/error.jsp</result>
</action>
全局逻辑视图
<global-results>
<result name="success">/success.jsp</result>
<result name="error">/error.jsp</result>
</global-results>
自定义结果类型
封装参数
静态参数注入
原理:由一个叫做staticParams拦截器完成的。
动态参数注入
动作类作为模型对象,动作类中存储着用户输入的数据。
动作类处理用户请求,模型封装数据。
模型驱动
1、动作类和模型分开
由一个ModelDriven的拦截器完成的。
批量添加数据:
用户注册
封装数据的类型转换
用户输入的数据是字符串类型的,而实体bean有其他类型。 读数据。 DefaultTypeConverter
注册类型转换器: 局部类型转换器注册:针对属性 全局类型转换器:针对转换类型。
<s:fieldError /> 或者<s:actionError />
在属性所属类的包中,user.properties。
invalid.fieldvalue.birthday=The birthday must be yyyy-MM-dd
用户输入的校验
客户端校验,服务端校验。
动作类继承ActionSupport.
编程式校验:
针对动作类中的方法校验。 StringUtils.isBlank(user.getName()){
} 转换失败都会转向一个name=input的视图。
声明式校验:可插入式的校验。
针对所有方法:
针对某个动作进行校验:
<%@ taglib uri="/struts-tags" prefix="s"%>
<s:form action="regist"><!-- 自动加应用名称,method默认是post。自动加动作的扩展名。自动数据回显。写起来很方便 -->
<s:textfield name="username" label="用户名" requiredLabel="true" requiredPosition="left"></s:textfield>
<s:password name="password" label="密码"></s:password>
<s:radio list="#{'0':'女','1':'男'}" name="gender" label="性别"></s:radio>
<s:textfield name="birthday" label="生日"></s:textfield>
<s:textfield name="email" label="邮箱"></s:textfield>
<s:submit value="注册"></s:submit>
</s:form>
OGNL表达式
对象图导航语言,struts2使用OGNL表达式做为默认的表达式语言。 支持普通对象的方法调用。
<s:property value="'abcdf'.length()"/> <br />
<s:property value="'abcdf'.charAt(2)"/> <br />
<s:property value="@java.lang.Integer@MAX_VALUE"/> <br />
<s:property value="@java.lang.Math@abs(-100)"/> <br />
<!-- 创建List或者Map对象 -->
<s:radio list="{'男','女'}" name="gender" label="性别" /><br />
<s:radio list="#{0:'女',1:'男' }" name="姓名"></s:radio>
OGNL上下文
就是一个Map<String,Object>数据的中心,每次动作的请求,struts2框架都会为每个线程创建一个OGNL上下文对象,存放了所有的有关数据.
根中的数据: <s:property value="username" />username是一个OGNL表达式,搜索根中所有对象的username属性,直到找到为止。
其他contextMap中的数据, <s:property value="#session" />
用户发出一次动作请求时,Struts2框架每次都会产生ActionContext对象(引用了contextMap),ValueStack对象,同时还会实例化动作类。
ActionContext和ValueStack
互相引用。
private Map<String, Object> context:contextMap
public Map<String, Object> getApplication():获取ServletContext中的所有Attributes
public Map<String, Object> getContextMap():获取contextMap的引用
public Map<String, Object> getParameters():获取请求参数的Map
public Map<String, Object> getSession():获取HttpSession中的所有Attributes
public ValueStack getValueStack():获得ValueStack对象的引用
public Object get(String key):从contextMap中根据key获得对象
public void put(String key, Object value):向contextMap中存放数据
ValueStack
setValue:以#存在contextMap中,不以#开头,相当于设置栈中对象的属性(从栈顶到栈底).
Struts2中的EL表达式
org.apache.struts2.dispatcher.StrutsRequestWrapper
<s:property value="#session.p"/><br/>
${p}<br/>
<hr/>
<s:property value="username"/><br/>
${username}
标签库
循环遍历,类似于<c:forEach >
<s:iterator value=""></s:iterator>
取属性值: <s:property value="#status.index"/>
value:ognl表达式。要遍历的数据 var:引用当前遍历的元素,放到了contextMap中。不是ognl表达式,是一个字符串. 如果不指定var,是把当前遍历的元素放到了根的栈顶。 status:引用一个对象,该对象记录着当前遍历的元素的一些信息.放在了contextMap中 int getIndex(); int getCount(); boolean isLast(); boolean isFirst(); boolean isOdd(); boolean isEven();
点击跳转:
<s:a action="action1" >点我啊!</s:a>
动态包含
<s:action name="action1" executeResult="false"></s:action>
1、把OGNL当作普通字符串对待,要加单引号。 2、把字符串当作ONGL表达式,加上%{} 3、在xml配置文件和properties文件中,使用ONGL表达式,要加上${表达式}
UI标签和主题
在struts2中的jsp编写时尽量使用struts2的标签。
标签调查常用属性: 引入css类选择器. <s:textfield cssClass="odd" cssStyle="" name="" />
<s:form action="" >
<s:textfield name="username" label="用户名" requiredLabel="true"></s:textfield>
<s:password name="password" label="密码" requiredLabel="true"></s:password>
<!-- 多选框 -->
<s:checkboxlist name="hobby" list="{'吃饭','睡觉','逗你玩'}"></s:checkboxlist>
<s:radio name="gender" list="#{1:'男',0:'女' }" value="1" label="性别"></s:radio>
<s:select name="city" label="城市" list="#{'HY':'衡阳','CS':'长沙' }" value="'HY'" headerKey="-1"headerValue="--请选择--" ></s:select>
<s:textarea name="des" label="描述"></s:textarea>
<s:submit value="保存" ></s:submit>
<s:reset value="重置"></s:reset>
</s:form>
主题默认使用的是xhtml. 支持: struts.ui.theme=xhtml struts.ui.templateDir=template
覆盖主题只需要在职介的项目中建立对应的目录结构,freemarker的语法。
更改默认主题: 添加theme="simple"
<s:submit value="保存" theme="simple"></s:submit>
在form标签中制定主题
统一主题:
<constant name="struts.ui.theme" value="simple"></constant>
防止表单重复提交
1、尽量使用提交后重定向 2、令牌机制, 在表单中加入 <s:token></s:token>
配置token拦截器。
<interceptor-ref name="defaultStack"></interceptor-ref>
<interceptor-ref name="token"></interceptor-ref>
<interceptor-ref name="defaultStack"></interceptor-ref>
<interceptor-ref name="tokenSession"></intercepHibernate篇
简介
hibernate是轻量级的JAVAEE应用的持久层解决方案,是一个关系型数据库ORM框架。 ORM:对象关系映射,对象:java中一切皆对象javaBean,关系:数据库中的表(二维表),映射:配置文件。
编写步骤
- 创建java项目
- 导入jar包
- 核心配置文件(hibernate.cfg.xml)
- javaBean +映射文件( bena名称.hbm.xml),必须将映射文件加入到核心配置文件。
核心配置文件:
驱动、url、username、password、规范
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<!-- 相当于连接池 -->
<session-factory>
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/day15</property>
<property name="hibernate.connection.username">zp</property>
<property name="hibernate.connection.password">a</property>
<property name="hibernate.dialect">org.hibernate.dialect.MySQL5Dialect.class</property>
</session-factory>
</hibernate-configuration>
映射文件: User.hbm.xml,和javabean同包。
配置javabena属性和表中字段的对应关系.
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd">
<hibernate-mapping>
<class name="cn.tf.domain.User" table="t_user">
<!-- 给表配置主键 -->
<id name="uid">
<!-- 主键生成策略 -->
<generator class="native"></generator>
</id>
<!-- 其他属性 -->
<property name="username"></property>
<property name="password"></property>
</class>
</hibernate-mapping>
API详解
SessionFactory,单例的,线程安全的,不同的线程可以获得不同的session。
configuration。buildSessionFactory():获得实例
openSseeion(),创建一个会话,每执行一次,session都是新的。
Configuration:提供用于去加载配置文件的。
核心配置文件的种类:hibernate.properties(只能配置基本信息) 和hibernate.cfg.xml(可以配置基本信息,映射文件等)
构造方法:new Configuration().configure(); 去加载hibernate.cfg.xml配置文件。
通过configure(string ),指定自定义的cfg.xml文件。
config.addResource("cn/tf/domain/User.hbm.xml");
或者:
config.addClass(User.class);
Session:
每个用户必须独享自己的session, save,update,delete,createQuery(list/setFirstResult/setMaxResults)
事务操作
- 开启事务:beginTransaction()
- 提交事务: commit()
- 回滚:rollback()
主配置文件
hibernate.cfg.xml 位置:src(classpath) ,在WEN-INF/classes目录下
<!-- 显示生产sql语句 -->
<property name="hibernate.show_sql">true</property>
<!-- 格式化方式显示sql -->
<property name="hibernate.format_sql">true</property>
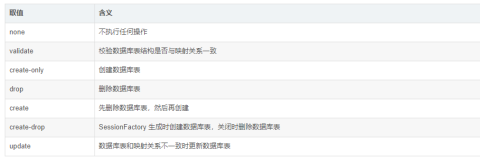
<!-- 表的创建 ,先有表,再有映射,实际开发中通过表自动生成hbm.xml映射文件
取值:validate:程序运行时,将校验映射文件和表的对应关系,如果一一对应程序正常运行,如果不正常则抛异常。
create :每一次都将创建表,如果表已经存在了就删除,程序结束之后表还在
create-drop:每一次都将创建表,如果表已经存在了就删除,程序结束之后表也删除了, 必须执行factory.close()
update:如果表不存在就创建,如果存在,将维护映射到表的关系。只负责添加,但不进行删除。
-->
<property name="hibernate.hbm2ddl.auto">update</property>
<!-- 取消bena校验 -->
<property name="javax.persistence.validation.mode">none</property>
<!-- 将session绑定到本地线程中
当在cfg.xml配置了thread,SessionFactory提供的getCurrentSession()将可以使用
get():相当于map.get(Thread)
set(value): 相当于map.put(Thread,value)
remove() :map.remove(Thread)
-->
<property name="hibernate.current_session_context_class">thread</property>
映射文件基本配置
<class name="cn.tf.domain.Person" table="t_person">
<!-- 给表配置主键 -->
<id name="pid">
<!-- 主键生成策略 -->
<generator class="native"></generator>
</id>
<!-- 其他属性
name:默认用于配置javabean属性名称
length:配置长度,默认255
column:当前属性对应表中字段名称,默认和name值相同
column的属性: <property column="" ></property>
<column name=""></column>
type: 数据字段类型
hibernate类型:例如:string(都是小写)
java类型:例如java.lang.String
mysql类型:例如varchar(50) , <column name="name" sql-type="varchar(50)" />
日期时间类型:
date:日期,java.util.Date
time:java.util.Date
timestamp:java.util.Date,时间戳随时间变化而变化
项目中使用datetime表示日期时间
-->
<!-- 其他配置
access ,用于确定当前属性如何进行数据封装
property : 默认值,hibernate采用javabean属性 与 表字段进行对应。在javabean必须提供 getter/setter方法
field : hibernate采用 javabean 字段 与 表字段进行对应。 可以没有getter/setter方法
例如:private String username;
noop : 提供给hibernate hql使用,数据库没有对应字段。一般不使用。
precision 和 scale 给 oracle配置,在mysql没有作用。
precision 配置数字位数
scale 配置小数位数
例如:numeric(precision,scale) , 12.34 numeric(4,2)
-->
<property name="name" length="50" column="name" type="string" access="property"> </property>
<property name="gender" ></property>
<property name="age" type="integer"></property>
<property name="photo" type="binary" length="200000"></property>
<property name="birthday" >
<column name="birthday" sql-type="datetime"></column>
</property>
<property name="desc" column="`desc`"></property>
</class>
insert="false" 表示生成insert语句没有当前字段 update="false" 表示生成update语句没有当前字段
在class中设置动态的添加和修改,默认是false,如果属性内容为空,则生成的sql中就没有该字段。
dynamic-insert="false" dynamic-update="false" 如果使用动态更新,数据必须是查询获得的。
派生属性
从数据库另一张表查询获得。 聚合函数:count(),max(),min(),avg(),sum()等。
sql语句:如果使用字段,默认从当前表中获得字段的,如果要获得B表字段,必须使用表的别名。
<property name="orderCount" formula="(SELECT COUNT(*) FROM t_order o WHERE o.book_id=bid)"></property>
生成的sql语句:
select
book0_.bid as bid1_0_,
book0_.title as title1_0_,
book0_.price as price1_0_,
(SELECT
COUNT(*)
FROM
t_order o
WHERE
o.book_id=book0_.bid) as formula0_0_
from
t_book book0_
where
book0_.bid=?
OID映射
hibernate通过OID确定系统,及OID相同,对象就相同,OID取值为数据库主键的值。
<id name="cid" >
<generator class="identity"></generator>
</id>
id属性配置,
name:OID属性名称
column:表字段列名
length:表字段长度
type:表字段类型
unsaved-value:save或update方法使用依据
String,默认是null,如果使用unsaved-value="abc" ,当执行save方法,设置“abc”相当之前null
generator:主键生成策略
increment:类型必须是整型,自己维护表的数据自动增长,在执行insert语句执行之前,先查询,查询最大值,加1,但是在高并发或集群中会有一定的问题。
identity:使用数据库底层的自动增长,auto_increment
sequence:oracle序列
hilo:采用高低位算法,不支持自动增长,也不支持序列
table ,设置数据库中,另一个表A的表名。
column,表A的列名
max_lo,一次操作多少条记录。100表示可以允许一次操作100条记录。
算法:max_lo * next_value + next_value
例如:
<generator class="hilo">
<param name="table">hi_value</param>
<param name="column">next_value</param>
<param name="max_lo">100</param>
</generator>
非整型:
uuid:随机字符串32长度
assigned:自然主键,手动设置
持久对象状态
状态分类:
- transient:瞬时态,session中没有缓存数据,数据库没有对应的数据。
- persistent:持久态,session中有缓存数据,数据库中最终会有该数据,例如save(user).
- detached:脱管态,session没有缓存,但是数据库中有该数据,
瞬时态->持久态 :执行save()和saveOrUpdate()
瞬时态->脱管态 :手动设置OID,如果OID对应的记录不存在,之后操作将抛出异常
持久态->瞬时态 :当执行delete(),(删除态)
持久态->脱管态 :close()关闭,clear()清除所有缓存,session.evict(PO)将指定的对象从缓存中移除
脱管态->瞬时态 :手动删除OID
脱管态->持久态 :执行update,执行了saveOrUpdate()
所有查询结果,对象都是持久态,查询结果保存在session中。
一级缓存
session级别的缓存,及将数据保存在session中。 一级缓存内置,不能删除,必须使用的。
目的:提高性能,减少数据库的访问。
一级缓存操作
session提供map容器,用于执行一些指定的操作时,进行相应PO对象缓存。
save方法
当OID类型为:代理主键,执行save方法时,将触发insert语句,确定OID的值。直到commit数据才进入数据库。
当OID类型为:自然主键,执行save方法时,此时不触发insert语句,直到commit才触发insert语句,数据进入数据库。
如果OID在数据库中已经存在记录将抛异常。
saveOrUpdate方法
对象时瞬时态,执行saveOrUpdate,底层执行save方法。如果对象时脱管态,执行saveOrUpdate,底层执行update方法。
OID 代理主键,OID如果没有值,执行save方法;如果有值(setUid(,,)),执行update方法。
如果设置oid,但数据库中没有对应记录,将抛异常。
oid自然主键,先执行select查询来获得主键的值,若OID不存在,则save,OID存在,则update。
update方法
当执行update时,都会执行update,即使数据没有变更。
可以通过映射文件配置:select-before-update,在更新前先查询,如果数据系统,将不进行update,适用于更新不频繁的应用。
一级缓存内容的操作
清空缓存
session.clear();
或者
session.evict(user);
一级缓存快照(备份)
提交时要确定一级缓存的数据是否进行了修改,如果没有修改,就不进行任何操作,如果修改了,就执行update,将一级缓存的数据同步到数据库。是否修改的依据就是一级缓存的数据与快照的数据是否一致。
默认提交时,一级缓存的数据将进行刷新,执行update语句,使一级缓存的数据同步到数据库。刷新时机是可以修改的:在hibernate中提供了FlushMode进行设置。
刷新时机:1、查询前,2,提交时,3,执行flush进行手动刷新,4,默认进行commit时,可以理解为依据进行了flush了。
关联关系映射
一对多、多对多、一对一
实体关系
采用ER图(关系实体图),开发时进行表之间的描述。
一对多
<!-- 一个客户拥有多个订单,一对多
Set:set
List:list
Map:map
Array:array
key:用来确定从表的
-->
<set name="orderSet" >
<key column="customer_id"></key>
<one-to-many class="cn.tf.domain.Order" />
</set>
--
<!-- 多个订单属于一个客户
每一个映射文件都可以完整的描述对象之间的关系
column,确定从表外键
-->
<many-to-one name="customer" class="cn.tf.domain.Customer" column="customer_id">
</many-to-one>
一对多: 多方必须维护外键信息,如果一方没有OID值,将触发update语句, 一方默认对外键信息进行维护,一方将放弃对外键的维护 在Customer.hbm.xml中,加入
inverse="true"
级联操作
级联保存或更新
save-update:A关联瞬时态B,当保存A时,自动将瞬时态的B转换成持久态B
cascade="save-update"
级联删除:
<set name="orderSet" cascade="delete" >
删除客户的时候删除订单: 删除后台执行的语句:
Hibernate:
select
customer0_.cid as cid1_0_,
customer0_.cname as cname1_0_
from
t_customer customer0_
where
customer0_.cid=?
Hibernate:
select
orderset0_.customer_id as customer3_1_1_,
orderset0_.oid as oid1_,
orderset0_.oid as oid2_0_,
orderset0_.price as price2_0_,
orderset0_.customer_id as customer3_2_0_
from
t_order orderset0_
where
orderset0_.customer_id=?
Hibernate:
update
t_order
set
customer_id=null
where
customer_id=?
Hibernate:
delete
from
t_order
where
oid=?
Hibernate:
delete
from
t_customer
where
cid=?
孤儿删除
<set name="orderSet" cascade="delete-orphan" >
解除关系之后,那个表外键设置null,从表记录就是孤儿,一并进行删除,解除关系时,一并删除订单,但是客户还是存在的。
多对多
<!-- 多对多
确定中间表的表名
当前表在中间表对应的名称
确定容器中另一个对象,class来确定另一个对象的类型,column确定的是另一个表对应的外键名称
-->
<set name="studentSet" table="t_student_course" >
<key column="course_id"></key>
<many-to-many class="cn.tf.domain2.Student" column="student_id"></many-to-many>
</set>
--
<set name="courseSet" table="t_student_course">
<key column="student_id"></key>
<many-to-many class="cn.tf.domain2.Course" column="course_id"></many-to-many>
</set>
操作
两个对象不用同时对中间表进行维护,所以需要在多对多中有一方配置放权。
inverse="true"
级联保存 直接保存即可。
双向级联删除
Student.hbm.xml
* <set name="courseSet" table="m_student_course" cascade="delete">
* Course.hbm.xml
* <set name="studentSet" table="m_student_course" cascade="delete" inverse="true">
集成log4j
hibernate使用的是slf4j日志框架。
组件映射
通过面向对象角度,使用设计模式,将数据都抽取到一个对象中,将多个对象组合在一起,达到重复利用的目的。
必须确定组合javabean类型,每一个对象属性必须在表中都存在独有列名。
<class name="cn.tf.component.Person" table="t_person">
<id name="pid">
<generator class="native"></generator>
</id>
<property name="name"></property>
<component name="homeAddress" class="cn.tf.component.Address">
<property name="addr" column="homeAddr"></property>
<property name="tel" column="homeTel"></property>
</component>
<component name="companyAddress" class="cn.tf.component.Address">
<property name="addr" column="companyAddr"></property>
<property name="tel" column="companyTel"></property>
</component>
继承映射
继承方式1:sub-class 所有内容保存一张表,给表提供标识字段,每一个子类都具有独有的字段。
继承方式1:
<class name="cn.tf.inherit.subclass.Employee" table="t_employee" discriminator-value="员工">
<id name="eid">
<generator class="native"></generator>
</id>
<discriminator column="etemp"></discriminator>
<property name="name"></property>
<subclass name="cn.tf.inherit.subclass.SalaryEmployee" discriminator-value="正式员工">
<property name="salary"></property>
</subclass>
<subclass name="cn.tf.inherit.subclass.HourEmployee" discriminator-value="小时工">
<property name="rate"></property>
</subclass>
继承方式2:
<joined-subclass name="cn.tf.inherit.joinedclass.HourEmployee" table="j_hour">
<key column="hid"></key>
<property name="rate"></property>
</joined-subclass>
<joined-subclass name="cn.tf.inherit.joinedclass.SalaryEmployee" table="j_salary">
<key column="sid"></key>
<property name="salary"></property>
</joined-subclass>
继承方式3: 将生成多张表,彼此之间没有关系,但主键值逐渐增强,需要hiberate自动维护三张表之间的主键唯一,存在并发问题。
<union-subclass name="cn.tf.inherit.unionclass.HourEmployee" table="u_hour">
<property name="rate"></property>
</union-subclass>
<union-subclass name="cn.tf.inherit.unionclass.SalaryEmployee" table="u_salary">
<property name="salary"></property>
</union-subclass>
抓取策略
检索方式
立即检索:在执行查询之后,立即执行select语句进行查询
延迟检索:在执行查询方法之后,没有进行查询,底层生成代理对象呢,直到需要相应的数据,在进行查询。 除OID之外的值,关联的数据
检索类型
类别级检索:当前对象所有属性值。,查询当前类的所有内容,只查询一次,优化指查询时机优化。
关联级检索:当前对象关联对象数据。
多对一,一对一:共同特点都拥有一方
一对多、多对多
<set name="orderSet" fetch="join" lazy="true">
fetch用来确定hibernate生成的sql的样式,lazy表示制定sql的时间。
fetch="join" ,lazy无效,hibernate 将使用“迫切左外连接”,底层执行sql语句就是“左外连接”,只执行一条select,将当前对象及关联对象数据一次性查询出来。
fetch="select" ,默认值,执行多条select语句
lazy="false" 立即执行,在执行get方法时,立即执行多条select语句。
lazy="true" 延迟执行,在执行get方法时先查询客户Customer,直到使用Order数据时才查询Order
lazy="extra" 极其懒惰,在执行get方法时先查询客户Customer(select tcustomer),如果需要order 订单数,将执行聚合函数只查询数量(select count() torder),如果需要详情再查询详情(select t_order))。 fetch="subselect" ,采用子查询
lazy 取值与 fetch="select" 相同。 注意:必须使用Query进行查询。
检索方式总结
1、通过OID检索:get()立即查询,如果没有就返回null;load()默认延迟检查,如果没有抛出异常。使用以上两个方法进行查询,结果都是持久态对象,持久态对象就在以及缓存中。
2、对象导航图:通过持久对象自动获得关联对象。例如customer.getOrderSet().size()
3、SQL,session.createSQLQuery("sql语句")
4,QBC,hibernate提供的纯面向对象查询语句。
5,HQL, 提供面向对象的查询语句。 HQL使用对象和对象属性,sql语句使用表名和字段名称,对象和属性区分大小写,表名和字段不区分大小写。
查询所有
//1、HQL //Query query=session.createQuery("from Customer");
//使用全限定名
//Query query=session.createQuery("from cn.tf.init.Customer");
//别名,不能使用*号
//Query query=session.createQuery("select c from Customer as c");
//sql,必须将查询结果封装到相应的对象中
SQLQuery sqlQuery=session.createSQLQuery("select * from t_customer");
sqlQuery.addEntity(Customer.class);
List<Customer> allCustomer=sqlQuery.list();
//QBC
Criteria criteria=session.createCriteria(Customer.class);
List<Customer> allCustomer=criteria.list();
//List<Customer> allCustomer=query.list();
//输出
for (Customer customer : allCustomer) {
System.out.println(customer);
}
根据ID查询
//hql
//Customer customer=(Customer) session.createQuery("from Customer c where c.cid=1").uniqueResult();
//sql
//Customer customer=(Customer) session.createSQLQuery("select * from t_customer c where c.cid=1").addEntity(Customer.class).uniqueResult();
//QBC
Customer customer=(Customer) session.createCriteria(Customer.class)
.add(Restrictions.eq("cid", 1))
.uniqueResult();
排序
//hql
//List<Customer> allCustomer=(List<Customer>) session.createQuery("from Customer c order by c.cid ").list();
//sql
//List<Customer> allCustomer=(List<Customer>) session.createSQLQuery("select * from t_customer order by cid desc").addEntity(Customer.class).list();
//QBC
List<Customer> allCustomer=(List<Customer>) session.createCriteria(Customer.class).addOrder(org.hibernate.criterion.Order.asc("cid")).list();
for (Customer customer : allCustomer) {
System.out.println(customer);
}
查询部分内容(投影)
hql,默认查询部分将查询结果封装到object数组中,需要封装到指定的对象中,投影查询的结果是脱管态的。
List<Customer> allCustomer=(List<Customer>) session.createQuery(" select new Customer(cid,name) from Customer ").list();
//sql
//List<Customer> allCustomer=(List<Customer>) session.createSQLQuery("select cid,name from t_customer ").addEntity(Customer.class).list();
//QBC
List<Customer> allCustomer = session.createCriteria(Customer.class)
.setProjection(Projections.projectionList()
.add(Projections.alias(Projections.property("cid"), "cid"))
.add(Projections.alias(Projections.property("name"), "name"))
)
.setResultTransformer( new AliasToBeanResultTransformer(Customer.class))
.list();
分页查询
//1、HQL
//List<Customer> allCustomer=session.createQuery("from Customer").setFirstResult(0).setMaxResults(2).list();
//sql,必须将查询结果封装到相应的对象中
//List<Customer> allCustomer=session.createSQLQuery("select * from t_customer").addEntity(Customer.class).setFirstResult(0).setMaxResults(2).list();
//QBC
List<Customer> allCustomer=session.createCriteria(Customer.class).setFirstResult(0).setMaxResults(2).list();;
绑定
占位符: #属性=? 从0开始,setXXX(index,oid);第一个参数表述索引号,从0开始,第二个表示oid的值,也可以使用.setParameter(0, 1) 别名:
* 属性=:别名
* 第一个参数是别名,一般建议使用属性名称
Customer customer=(Customer) session.createQuery("from Customer c where c.cid= ? ")
//.setInteger(0, 1)
.setParameter(0, 1)
.uniqueResult();
Customer customer=(Customer) session.createQuery("from Customer c where c.cid=:cid")
.setInteger("cid", 1)
.uniqueResult();
聚合函数
//Object obj=session.createQuery("select count(*) from Customer").uniqueResult();
//Object obj=session.createQuery("select count(*) from Customer").uniqueResult();
Long numLong=(Long) session.createQuery("select count(*) from Customer").uniqueResult();
int num=numLong.intValue();
//输出
//2 sql
//BigInteger numObj = (BigInteger) session.createSQLQuery("select count(cid) from t_customer").uniqueResult();
//3 qbc
Long numObj = (Long)session.createCriteria(Customer.class)
.setProjection(
Projections.projectionList()
.add(Projections.rowCount())
)
.uniqueResult();
连接查询
- 内连接:[inner] join
- 左外连接: left [outer] join
- 右外连接: right [outer] join
- 迫切左外连接: left [outer] join fetch
- 迫切内连接: [inner]join fetch
左外连接,将每一条查询结果封装到Customer 和Order对象,然后创建 new Object[2]{c,o} 。将所有的数组 存放到另一个数组返回
List<Customer> allCustomer=session.createQuery("from Customer c left outer join c.orderSet ").list();
迫切左外连接,将所有的查询结果封装Customer和Order对象,然后将Order 添加到 Customer(customer.getOrderSet().add(order)) ,最后返回Customer对象集合
List<Customer> allCustomer=session.createQuery("select distinct c from Customer c left outer join fetch c.orderSet ").list();
命名查询
将HQL语句存放到配置文件中,之后不需要修改java源码,服务器tomcat重启即可。
全局:可以直接获得,在。hbm.xml文件中配置。与class同级之后
<!-- 配置全局hql -->
<class></class>
<query name="findAllCustomer">from Customer</query>
使用:
List<Customer> allCustomer=(List<Customer> )session.getNamedQuery("findAllCustomer").list();
局部:必须通过包名获得
<class><!-- 局部 -->
<query name="findAllCustomer2">from Customer</query></class>
使用:
List<Customer> allCustomer=(List<Customer> )session.getNamedQuery("cn.tf.init.Customer.findAllCustomer2").list();
常用配置
整合c3p0
<!-- 整合c3p0 -->
<property name="hibernate.connection.provider_class">org.hibernate.connection.C3P0ConnectionProvider</property>
事务
一组操作,要么全部成功,要么全部失败。 特性:ACID,原子性,一致性,隔离型,持久性
脏读,不可重复读,虚读
<property name="hibernate.connection.isolation">4</property>
丢失更新 lost update
两个人都在同时进行数据更新,后面讲前面的数据进行覆盖。
乐观锁:丢失更新肯定不发生:在表中提供一个字段(版本字段),如果版本一致可以提交,如果不一致不进行提交。
悲观锁:丢失更新肯定发生,采用mysql数据库的锁机制。读锁:共享锁,多个人可以一起读。 写锁:排它锁,
二级缓存
介于应用程序和永久性数据存储源之间,其作用是降低应用程序直接读写永久性存储源的频率,从而提高应用的运行性能,其物理介质是内存。
如果缓存不够用,可以将缓存写到文件中。
二级缓存
一级缓存,hibernate实现了,必须使用的。是用户自己共享数据。
二级缓存:SessionFactory级别的缓存,hibernate提供了规范(接口),如果需要使用必须有实现类,用户之间共享数据,
SessionFactory缓存: 内置缓存:自带的,不可卸载 外置缓存:二级缓存,需要配置
类缓存、集合缓存、时间戳、查询缓存。
并发访问策略:read-write、read-only
很少修改的,不重要的数据适合放入二级缓存中,允许偶尔的并发问题。
配置
1、导入jar包 2、开启二级缓存 3、确定提供商 4、确定需要缓存的内容 5、第三方配置文件
<!-- 开启二级缓存 -->
<property name="hibernate.cache.use_second_level_cache">true</property>
<!-- 提供商 -->
<property name="hibernate.cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
<!-- 开启查询缓存 -->
<property name="hibernate.cache.use_query_cache">true</property>
<!-- 二级缓存监测 -->
<property name="hibernate.generate_statistics">true</property>
<!-- 类缓存 -->
<class-cache usage="read-write" class="cn.tf.init.Customer"/>
<class-cache usage="read-write" class="cn.tf.init.Order"/>
<!--
-->
<!-- 集合缓存 -->
<collection-cache usage="read-write" collection="cn.tf.init.Customer.orderSet"/>
1、类缓存:数据为散装数据,一级缓存是对象,二级缓存是数据。
2、集合缓存,只缓存oid,如果需要数据就从类缓存获得。
3、时间戳:任何操作都会在时间戳中留下记录,但不要使用一级缓存特性,一级缓存同步数据库,同时一级缓存同步到二级缓存。保持二级缓存和数据库一致。
执行update语句,跳过一级缓存更新数据库,此时时间戳将记录修改的时间。
session1.createQuery("update Customer c set c.name = ? where c.cid = ?")
.setString(0, "王晓绿")
.setInteger(1, 1)
.executeUpdate();
4、查询缓存:默认情况查询缓存不能使用。 Query进行查询结果存放到二级缓存,但不从二级缓存获取。通过HQL语句和查询结果形成一一对应关系,之后通过HQL语句可以直接获得查询结果。
存放或获得数据, 查询所有 -- 将结果存放一级缓存,同时保存二级缓存
List<Customer> allCustomer = session1.createQuery("from Customer").setCacheable(true).list();
ehcache.xml配置
确定缓存内容的硬盘位置:
<diskStore path="D:\cache"/>
<defaultCache
maxElementsInMemory="5"
eternal="false"
timeToIdleSeconds="120"
timeToLiveSeconds="120"
overflowToDisk="true"
maxElementsOnDisk="10000000"
diskPersistent="false"
diskExpiryThreadIntervalSeconds="120"
memoryStoreEvictionPolicy="LRU"
/>
性能检测
二级缓存监测 ,先需要在配置文件中配置
<property name="hibernate.generate_statistics">true</property>
Statistics statistics = factory.getStatistics();
撞击数:
statistics.getSecondLevelCacheHitCount()
丢失:
statistics.getSecondLevelCacheMissCount()总结:软件系统发展到今天已经很复杂了,特别是服务器端软件,设计到的知识,内容,问题太多。在某些方面使用别人成熟的框架,就相当于让别人帮你完成一些基础工作,你只需要集中精力完成系统的业务逻辑设计。而且框架一般是成熟,稳健的,他可以处理系统很多细节问题,比如,事物处理,安全性,数据流控制等问题。还有框架一般都经过很多人使用,所以结构很好,所以扩展性也很好,而且它是不断升级的,你可以直接享受别人升级代码带来的好处。框架一般处在低层应用平台(如J2EE)和高层业务逻辑之间的中间层。
struts2案例: 员工信息管理系统:https://github.com/sdksdk0/PMSystem
整合案例:贴吧:https://github.com/sdksdk0/TieBa