在QCon2017的基础设施专场,笔者以表格存储为基础分享了分布式系统设计的几点考虑,主要是扩展性、可用性和性能。每个点都举了一个具体的例子来阐述。这里对这次分享做一次简单的总结。

首先,说到了表格存储产生的背景,大规模、弱关系数据,对灵活schema变动的需求,传统数据库无法很好的满足,NOSQL的出现是一个很好的补充。NOSQL不是为了取代SQL,也无法取代SQL,是已有数据库生态的很好补充。我认为未来会出现更多种类的数据库,面向不同的业务,使用不同的硬件,数据库市场将迎来更多的成员。

然后介绍了表格存储的功能、生态、架构以及数据模型,有了这些基础才能更好的理解后面的内容。
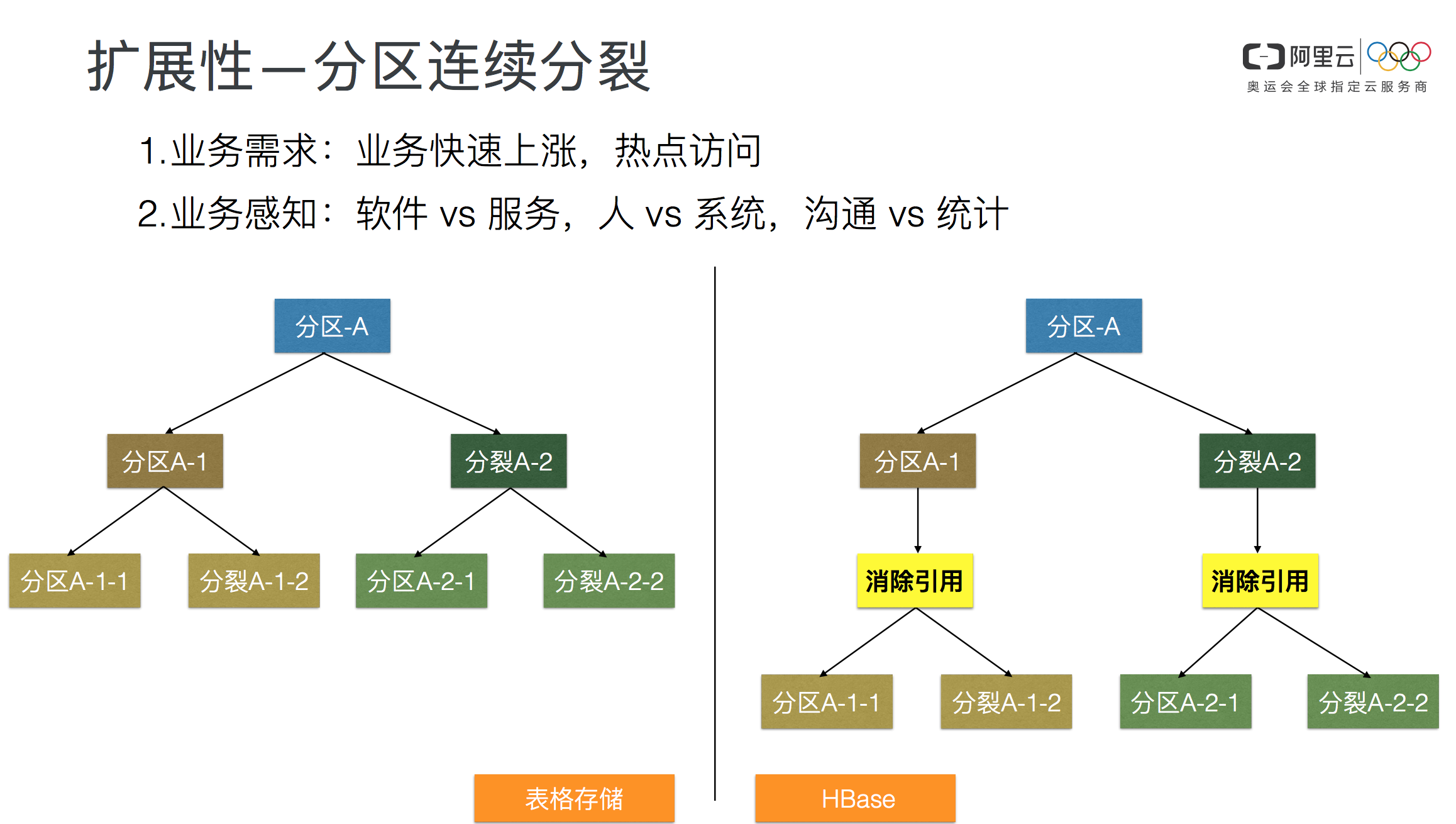
在论述扩展能力的时候,笔者举了个例子。HBase在一次分裂之后,需要做Compaction才能继续分裂,Compaction时间可能数个小时,而表格存储支持连续分裂。那么,为什么表格存储要支持连续分裂呢?主要原因在于多租户服务和企业内产品的不同。对于表格存储而言,用户点点鼠标就可以开通,业务访问随时可能大幅上涨,用户不会提前告诉我们,即使告诉了也人力也没那么多。而访问量上涨有很大的可能导致分区内访问热点,这些热点需要系统能够快速的处理,1个分裂成2个,2个分裂成4个...。而在企业内部,业务一般可以预期的,很难出现运维不期望的巨量上升,所以对于HBase而言,连续分裂的必要性就降低了。这个不同,看似技术的不同,实际则是用户不同、产品形态不同带来的的不同选择。

在论述可用性的时候,特别讲了一个例子,就是谷歌BigTable和开源HBase都采用的在worker层聚合日志以提高性能。这个思路很好理解,就是将多个分区的日志聚合在一起,写入文件系统中,这样就能减少文件系统的IOPS,提高性能。但是,这对可用性是个很大的伤害,因为一旦机器发生failover,意味着日志文件需要被读出来按照分区进行分割,这些分割完的日志文件再被相应的分区replay,然后相应分区才能提供服务。显然,上面这个过程会使得机器failover时候分区不可用的时间变长(想想看谁来分割日志呢?这是否会成为瓶颈?)。如果考虑到全集群重启,或者交换机down导致较多机器失联,那么其对可用性的影响将十分可观。这里是一个可用性和性能的权衡,表格存储在设计之初,是选择了可用性的,也就是每个分区有独立的日志文件,以降低在机器failover场景下不可服务时间。但是这是否意味着性能的下降?是的,但是我们相信可用性优先级更高,而性能总会被解决,后来我们也找到了非常不错的办法,见下。

上面说到可用性和性能的权衡,表格存储选择了可用性,而放弃了性能。但是性能显然十分重要,于是我们重新思考了这个问题。BigTable和HBase的核心思想是聚合以减少IOPS,从而提高性能;那么聚合是否一定要做在table这一层呢?是否可以下推做到分布式文件系统层?结论当然是可以,而且效果更好,受益方更多。具体架构见附件里面的说明,我们通过将聚合下推到文件系统、RPC层小包聚合、Pipeline传输等大幅改进了性能,在可用性和性能之间取得了很好的平衡。
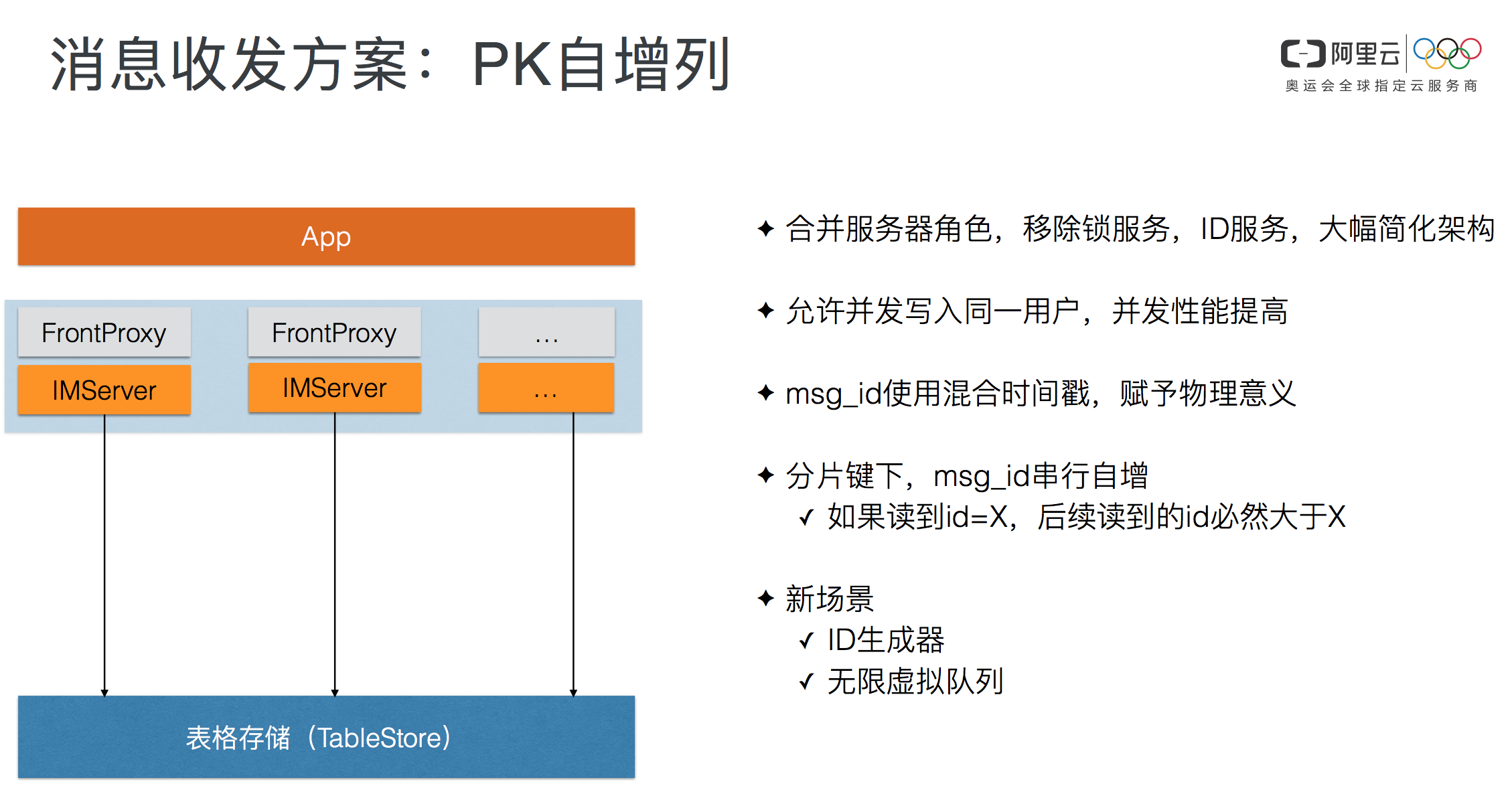
继续向下,我们说到了,作为一个平台,如何向用户学习。附件中给出了PK自增列用于消息推送系统的例子,这方面我们写过不少文章,见[2][3]。
[1]. QCon 2017资料: http://ppt.geekbang.org/qconsh2017
[2]. 高并发IM架构: https://yq.aliyun.com/articles/66461
[3]. 打造千万级Feed流系统: https://yq.aliyun.com/articles/224132
[4]. 演讲PPT下载: http://ppt.geekbang.org/slide/show/1122











