
10月14日,2017杭州云栖大会·阿里云大数据计算服务(MaxCompute)专场,阿里巴巴计算平台架构师林伟分享了主题《MaxCompute2.0 NewSQL演进之路》,介绍阿里云大数据计算服务MaxCompute 2.0在NewSQL上所做的优化和实践工作。
DT时代,越来越多的企业应用数据步入云端,NewSQL也成为业内越来越热的话题,它可以帮助用户通过编程接口良好地访问和存储数据。本文将介绍阿里云MaxCompute应用NewSQL的背景、关键技术解读等内容。

背景
提到NewSQL就会不可避免地谈到SQL。上世纪80、90年代,大家会提到的数据处理、数据库一般就是指DataBase应用。DataBase是一个关系型数据库,有很强的结构和语义,任何人在写查询语言时都可以做快速交互式查询。但是随着互联网的快速发展,大量数据的产生,传统DataBase逐渐面临着一系列的挑战。
首先是横向扩展性较差;互联网环境下,传统DataBase对于结构化、非结构化数据,语音、视频数据的支持比较落后,造成不够灵活;容错能力弱,分布式环境下要求建立数据中心来负载大量数据,这就需要强容错的能力。因此,SQL的大数据能力难以满足潮流的发展,也就带来了NoSQL的诞生,用于处理非结构化数据。
NoSQL是非关系型数据库,弱语义,很灵活,并且支持非结构、半结构和结构数据,横向扩展性较强,能够很好地Scale。此外,NoSQL提供强大的UDF,在map和reduce处理数据时,UDF能够定义key、value,而且接口可以很好地支持非关系型运算,灵活性很高。并且所有的计算节点都是独立的,所以容错能力也很强。可以看出NoSQL的大数据能力明显强于SQL,也因此诞生了谷歌BigTable,MapReduce等大数据系统。
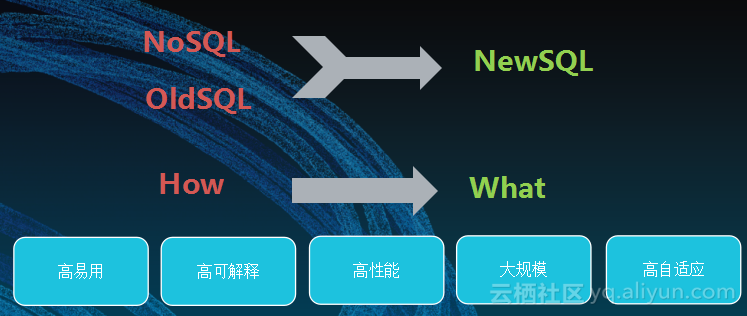
阿里云推出的NewSQL,就是想要结合SQL和NoSQL的优势。
NewSQL
NewSQL的原则是想要回归关系型数据库。做NoSQL时,程序员需要分别写map、reduce、value等等是什么,因此难以阐述清晰自己所做的工作,只有给到所有的coding细节才能了解。回归关系型,就是希望工程师描述的不是怎么去做(即How),而是在做什么(即What),别人读到NewSQL时就能明确工作内容。
NewSQL需要依赖强大的系统优化能力,通过强大的优化器能够整合多个功能,从而使得系统自适应生产高效物理执行计划。在这个过程中,我们需要同时保留NoSQL的特性,包括非结构化、强大的UDF集合、分布式支持等等。
我们的用户通过NoSQL手写高效的执行计划,具有以下问题:一方面,程序员不可能及时感受到数据和环境的变化,很容易造成数据倾斜的问题;另一方面,计算越来越复杂,上下游的壁垒下程序员不可能很快地分析出全局最优的执行计划;同时,计算需要能够分享知识,缺乏高层次强语义的语言则会阻碍这种分享;而且共享的资源环境下,单个程序员是缺乏系统全局观的。所以我们需要回归到NewSQL,让程序员描述他需要做什么,而由系统来优化得到高效的执行计划。
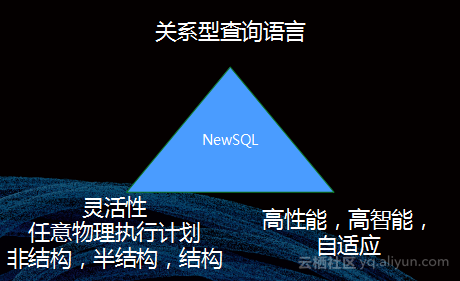
在图中的三个场景下,NewSQL其实都做到了很好地自适应。虽然希望程序员能够很好地描述自己所做的工作,但是因为缺乏灵活性,还是需要通过UDF在高层次语义上获取很好的平衡,使系统优化做到高性能、高智能、自适应的能力。
事实上,目前的整个行业都在朝着这个方向行进,比如微软提供Dryad引擎的同时,也提供Scope做优化工作;DataBricks在Spark之外也提供SparkSQL用于加快迭代;Hadoop更是经历了从MapReduce到Hive再到Hive2.0的升级;Google在MapReduce外也在力推具有SQL语义的Spanner。阿里云的MaxCompute1.0也在向MaxCompute2.0迈进,让系统帮助优化。
关键技术
为了实现SQL和NoSQL的平衡,一些关键技术需要了解。
支持非结构,半结构和结构化数据
互联网环境下,用户需要提供Serialize/Deserialize函数动态进行非结构到结构化的转换,从而提取出结构化的数据进行运算。由于传统DB的局限性,还需要支持用户自定义类型,丰富UDF功能,方便编程和语言的交互。用户还需要自定义分区,从而能够有效连接上下游,实现输入、输出与其他互联网应用相连。
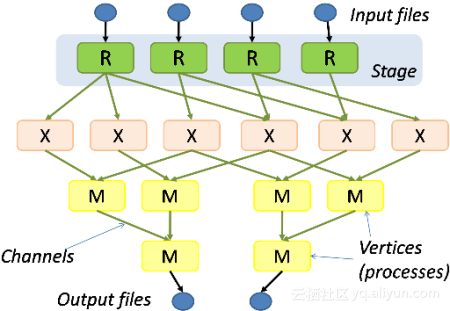
需要有强大的DAG执行图
这是为了突破MapReduce的束缚,从而进行循环迭代展开为DAG。而且需要有非对称图表达,从而支持复杂的物理执行计划。这样优化器才能产生高效Plan,使语言变得完整。
最重要的是完整的用户自定义函数体系
完整的UDF集合能使得关系型退化为函数型语言,可以构造任意的DAG执行计划,在语言上灵活互动,因此提供了:Serialize/Deserialize、多路Join函数、聚合处理函数、Processor完备分区函数(支持Hash/Range/Direct Hash)等等。
强大的优化器
强大的优化器可以提供存储过程的支持,从单一语句到成千上万的存储过程。NoSQL是函数型编程,能构建非常复杂的图,传统DB则是一条条语句提交上来,造成job分享效果较差。强大的优化器能够写出更加复杂的查询存储过程,从而使得逻辑执行计划非常庞大,优化空间更大,需要更先进的优化器,并且从RuleBased Opt慢慢演变成CostBased Opt。
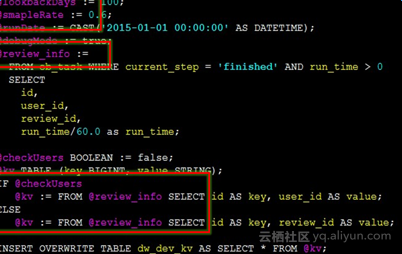
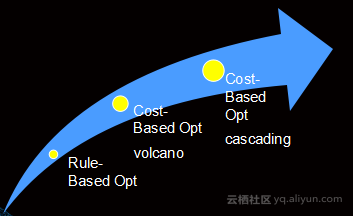
此外,想要优化器有别于单机场景,就需要考虑分布式。比如说Non-SQL场景下的众多UDF扩展,包括数据、用户、运算上的扩展,可以帮助用户生成非常好的Plan。

下图展示了一个有趣的例子,关于优化器与用户自定义函数(UDF)的结合效果。
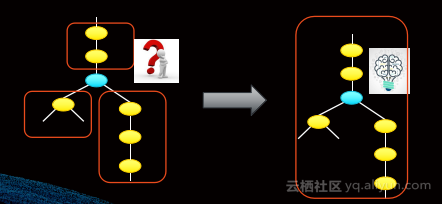
左边是没有理解UDF的效果,这种情况下优化性能较低,无法感知UDF的输出特性,从而产生低效的物理执行计划。右边则实现了UDF和优化器的良好互动,能够全局优化,有效和用户交互理解UDF的特性,使黑盒变成了灰盒。
实际例子
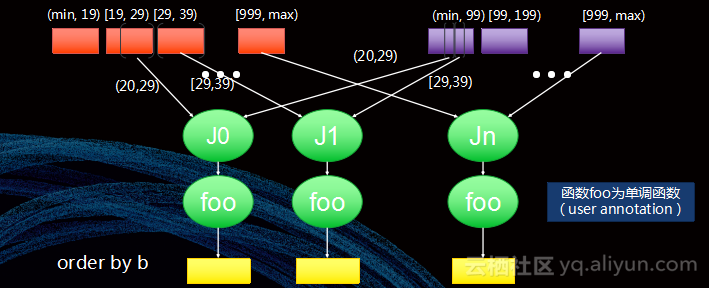
图中的应用大大减轻了分布式Cost,并且做到了灵活性和优化性的平衡。其实UDF的一些特性是值得用户去思考的:
a.Row-wise?单调函数?
b.某些column不变(pass through)?
c.保持分片?保持排序?
d.Selectivity,data distribution of output等等。
和单机SQL不同的是分布式场景的优化。大量NoSQL的用户自定义函数、分布式场景中各种动态环境(分配worker的拓扑结构、Failure Region的分布)等因素下,想要做到编译时优化和运行时优化的平衡,就要求强大的引擎来进行运行时优化:选择分区数目,边界;选择Join方式;高效的Datashuffle方式。
总结
NewSQL的原则是整合NoSQL和OldSQL的优势,帮助开发工作者提高开发效率,实现交互式运算。通过强大的系统优化能力,希望成功地做到高可用、高可解释、高性能、大规模以及高自适应,从而带来整个MaxCompute生态的繁荣。

MaxCompute招聘信息:DT时代,与坚持梦想者同行!
阿里巴巴大数据-玩家社区 https://yq.aliyun.com/teams/6/
---阿里大数据博文,问答,社群,实践,有朋自远方来,不亦说乎……






