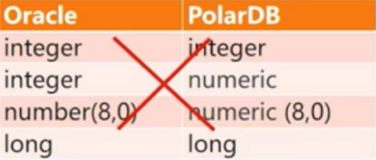
《Greenplum 数据库最佳实践 》 系统参数配置
系统配置
本章主要描述在Greenplum部署之前,系统参数的配置
文件系统 (File System)
推荐使用XFS作为Greenplum默认文件系统, 目前redhat,Centos 7.0 都开始使用XFS作为默认文件系统
如果系统不支持 需要使用下面的挂载命令
rw,noatime,nobarrier,nodev,inode64,allocsize=16m
XFS相比较ext4具有如下优点:
- XFS的扩展性明显优于ext4,ext4的单个文件目录超过200W个性能下降明显
- ext4作为传统文件系统确实非常稳定,但是随着存储需求的越来越大,ext4渐渐不在适应
- 由于历史磁盘原因,ext4的inode个数限制(32位),最多只能支持40多亿个文件,单个文件最大支持到16T
- XFS使用的是64位管理空间,文件系统规模可以达到EB级别,XFS是基于B+Tree管理元数据
端口配置 (Port Configuration)
设置端口ip_local_port_range 它不应该和Greenplum 数据库的端口范围冲突 例如
net.ipv4.ip_local_port_range = 3000 65535
PORT_BASE = 2000
MIRROR_PORT_BASE = 2100
REPLICATION_PORT_BASE = 2200
MIRROR_REPLICATION_PORT_BASE = 2300
I/O 配置
包含数据目录的设备的预读大小应设为 16384
# /sbin/blockdev --getra /dev/sdb
8192
如果显示的是8192需要使用如下命令设置
# /sbin/blockdev --setra 16384 /dev/sdb
#/sbin/blockdev --getra /dev/sdb
16384
包含数据目录的设备的I/O调度算法设置为deadline
# cat /sys/block/sdb/queue/scheduler
noop anticipatory [deadline] cfq
通过/etc/security/limits.conf 增大操作系统文件数和进程数
* soft nofile 65536
* hard nofile 65536
* soft nproc 131072
* hard nproc 131072
启动core dump 文件转储 [ 参考注1],并保存到已知位置,确保limits.conf中允许core转储文件
kernel.core_pattern = /var/core/core.%h.%t
# grep core /etc/security/limits.conf
* soft core unlimited
如果显示的是 # * soft core 0 , 需要修改为 * soft core unlimited
Core Dump (核转储文件)路径的设置
#vi /etc/sysctl.conf
kernel.core_pattern = /var/core/core.%h.%t
这里面的%h (表示主机名), %t (表示 触发 Core Dump 的时间(单位为秒,从 1970-01-01 00:00:00 开始计算))
操作系统内存配置
Linux sysctl 的 vm.overcommit_memory 和 vm.overcommit_ratio 变量会影响操作系统对内存分配的管理 这些变量设置如下:
vm.overcommit_memory 决定系统分配多少内存给全部的进程,通常我们设置该值为2, 这是一个非常安全的设置对于数据库
vm.overcommit_ratio 是当前的内存被全部进程所使用的,对于Red hat Enterprise linux默认值是50
共享内存配置
共享内存主要用于postgres实例间通信,建议使用sysctl配置如下内存共享参数,不建议修改:
kernel.shmmax = 500000000
kernel.shmmni = 4096
kernel.shmall = 4000000000
最终编辑文件 /etc/sysctl.config
验证操作系统
使用gpcheck 验证操作系统配置 参考《Greenplum数据库工具指南》
设置节点上段数据库的个数
确定每个节点上段数据库的个数对整体性能的影响巨大,一个节点上这些段数据库之间共享主机的CPU核、内存、网卡等,且和主机上的所有进程共享这些资源
段数据库的个数需要参考如下的主机信息:
- 主机的CPU核数
- 主机所含有的物理内存的数量
- 网卡个数和速度
- 主机所挂载的存储大小
- 主节点和镜像节点的数量
- ETL进程是否运行在主机上
- 非Greenplum进程运行在主机上
段数据库的配置
服务器配置参数 gp_vmem_protect_limit 控制了每个段数据库为所有运行的查询分配的内存总量,如果查询所需要的内存超过此值,则会失败,使用下面公式确定合适的值.
- 计算 gp_vmem ,主机有多少内存可供Greenplum Database使用,使用如下公式:
gp_vmem = ((SWAP+RAM) - (7.5GB + 0,05*RAM)) / 1.7
SWAP 是主机的交换空间 单位GB
RAM 是主机所安装的内存 单位GB
- 计算 max_acting_primary_segments
当段数据库故障或者主机故障使得镜像段(mirror segments)被激活时,该值用来表示在一个主机上可以运行的最大主段数量
配有四个主机块的镜像,每个主机上有8个主段。例如:一个单一的段数据库失效将会激活2或者3个镜像数据节点在每个剩余主机上的失败的 hosts's 块上
max_acting_primart_segments = 8 + 3 = 11 (8个主段 + 3个被激活的镜像节点)
- 计算 gp_vmem_protect_limit , 使用Greenplum 数据库可用的内存数GB 除以 所含有的段数据的数量(主段的数量)
gp_vmem_protected_limit = gp_vmem / max_acting_primary_segments
注: 这里的单位使用的MB,所以 需要对计算结果进行单位转换
对于生成大量工作文件(workfiles)的情况,需要调整gp_vmem已完成计算
gp_vmem=((SWAP+RAM) - (7.5GB + 0.05*RAM-(300KB*total_#_workfiles))) / 1.7
关于Greenplum中监控和管理workfile 的使用情况,需要参考 《Greenplum Database Administrator Guide》
计算 vm.overcommit_ratio
vm.overcommit_ratio = (RAM-0.026*gp_vmem) / RAM
例如:
8GB 交换空间 SWAP
128GB 内存 RAM
vm.overcommit_ratio = 50 === 0.5
8个段数据库
(8 + (128*0.5) )*0.9/8 = 8GB
则设置 gp_vmem_protect_limit = 8GB, 需要转换为 8192MB
SQL 语句内存配置
服务器配置参数 gp_statement_mem 控制段数据库上单个查询可以使用的内存总量,如果语句需要更多的内存,则会溢出数据到磁盘,用下面公式确定合适的值
(gp_vmem_protected_limit *0.9)/max_expected_concurrent_queries
例如,如果并发度为40, gp_vmeme_protected_limit 为8GB,则gp_statement_mem
(8192MB*0.9)/40 = 184MB
每一个查询只能分配184MB的内存,查询的内存资源超过该值时,会溢出到磁盘文件中。
若想安全的增大 gp_statement_mem ,要么增大gp_vmem_protect_limit,要么降低并发。增加gp_vmem_protect_limit,必须增大物理内存和交换空间,或者减少主机上运行的段数据的数量
注意:集群中加入更多的段数据库实例并不能解决内存溢出(out-of-memory errors)的问题,除非向集群中添加更多的新主机,将每个主机上运行的段数据库数量降低下来(即将段数据库分配到新的主机上)
当没有足够的内存用来存放mapper的输出,80%的Buffer被占用时,系统就会创建溢出文件(workfile)
溢出文件参数配置
在Greenplum数据库集群中,溢出文件 (spill files)也别称为 工作文件(workfiles),它是指当查询分配的内存不足以应对查询运行所需的内存资源时,(内存分配不足)。默认情况下,单一的查询不能创建多余100000个溢出文件,这对于大多数查询任务来说,这个溢出文件的数量足够用了。
我们可以通过设置 gp_workfile_limit_files_per_query 这个参数来修改最大数量的溢出文件, 这个值可以从0设置到无穷大。限制溢出文件的数量可以保证在查询运行中,防止系统的崩溃。
当内存不足以分配给一个查询或者数据倾斜引起一个查询任务产生很多溢出文件。如果查询任务产生的溢出文件数量超过阈值时,Greenplum会抛出异常
ERROR: number of workfiles per query limit exceeded
当我们准备调整溢出文件参数 gp_workfile_limit_files_per_query 限制时,可以先考虑修改我们的查询语句以达到减少溢出文件的数量(减小中间结果集的大小,避免中间计算引起计算倾斜问题),改变分布键(分布键引起数据分布不均匀,造成计算倾斜),调整内存参数
gp_toolkit
gp_toolkit 模式包含视图,允许我们查看当前的查询所使用的溢出文件的数量。这个参数可以用来排除故障和调优查询, 注意如下视图
gp_workfile_usage_per_query 视图
使用一行存储,当前时间段中,一个段数据库的一个操作的workfile所占用的磁盘空间
gp_workfile_usage_per_query 视图
使用一行记录,当前时间段中,有个段数据库的一个查询的workfile所占的磁盘空间大小
gp_workfile_usage_per_segment 视图
每一个段一行记录。
每一行记录都显示当前的workfile所使用的磁盘空间的总量
上述视图查看的语句为
SELECT * FROM gp_toolkit.gp_workfile_usage_*
查看 《Greenplum Database Reference Guide》 去看每一个视图的字段信息
参数 gp_workfile_compress_algorithm 参数是用来控制溢出文件的。它可以被设置为 none(默认)或者 zlib。设置为zlib,可以提升溢出文件的性能。
参考网址:
https://gpdb.docs.pivotal.io/500/best_practices/sysconfig.html
注:
- Linux 中生成Core Dump 文件方法。
1.1. 什么是 Core Dump
Core Dump 又叫核心转储。在程序运行过程中发生异常时,将其内存数据保存到文件中,这个过程叫做 Core Dump.
1.2. Core Dump 的作用
在开发过程中,难免会遇到程序运行过程中异常退出的情况,这时候想要定位到问题出在哪里,仅仅依靠程序自身的打印信息(日志记录)往往不够,这个时候就需要Core Dump 文件来帮忙了。
一个完整的Core Dump 文件实际上相当于恢复了异常现场,利用 Core Dump 文件,可以查看程序异常时的所有信息,变量值,站信息,内存数据,程序宜昌市的运行位置(甚至是diamante行号)等等,定位所需要的一切信息都可以从Core Dump文件获取,能够非常有效的提高定位效率。
http://blog.chinaunix.net/uid-20554957-id-4233534.html