热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
Golang深入浅出之-Go语言函数基础:定义、调用与多返回值
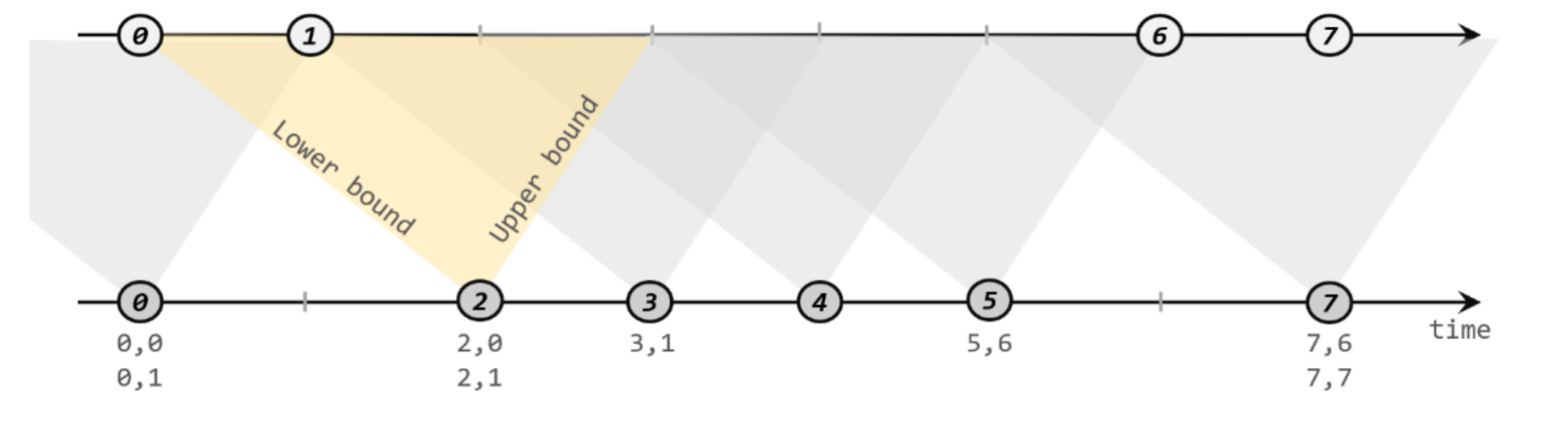
[尚硅谷 flink] 基于时间的合流——双流联结
编写 Dockerfile 最佳实践
[尚硅谷flink] 水位线
JavaSE&常用API
Golang深入浅出之-掌握Go语言Map:初始化、增删查改与遍历
ensp中路由重分发
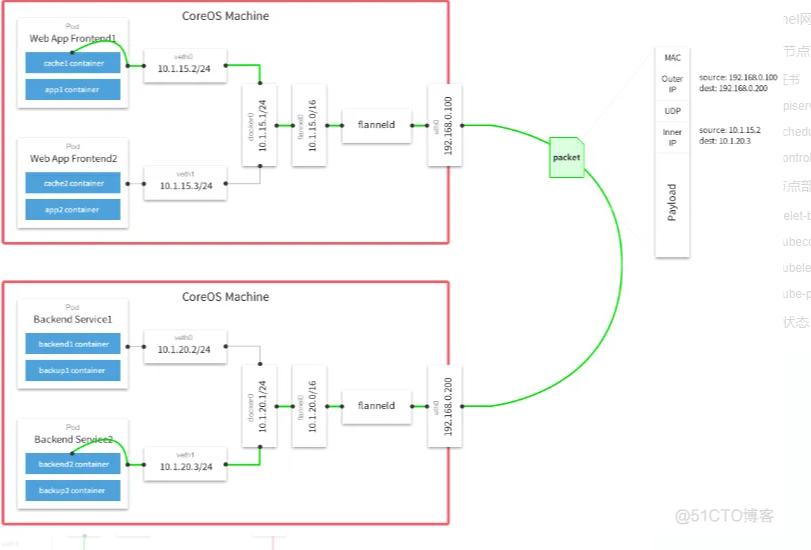
Kubernetes v1.12/v1.13 二进制部署集群(HTTPS+RBAC)
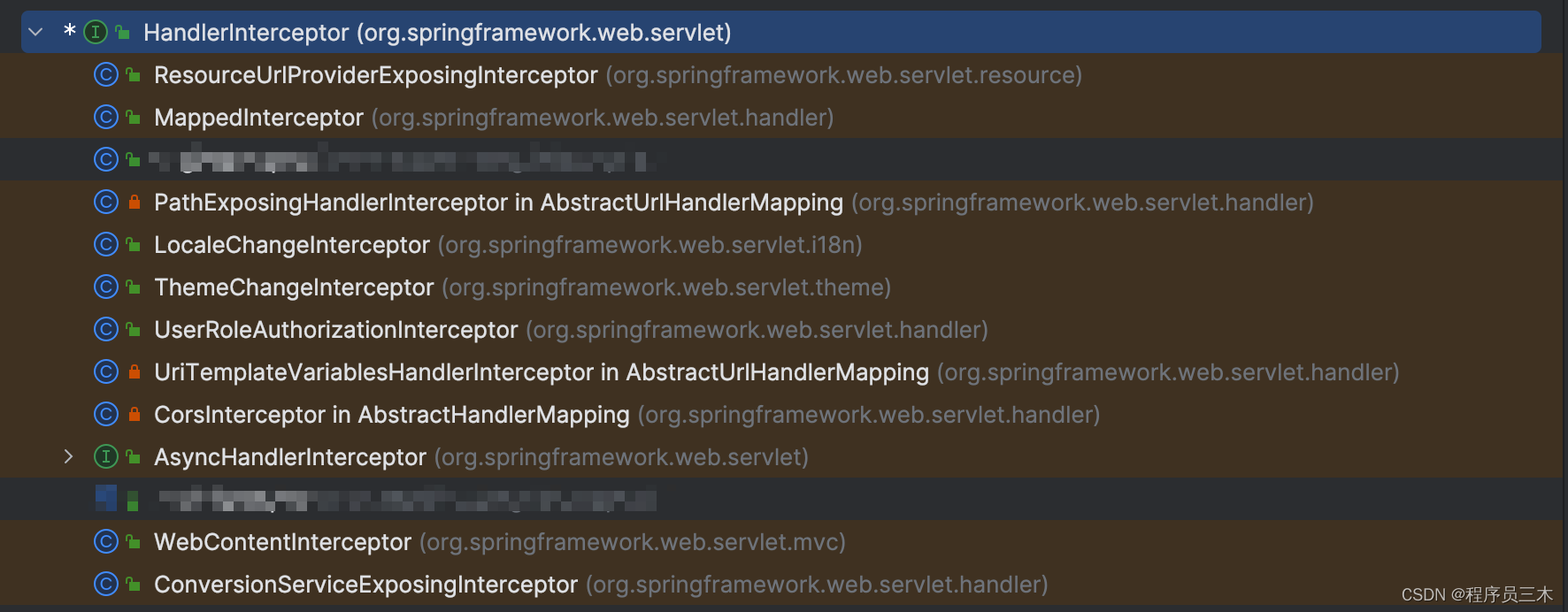
[AIGC] Spring Interceptor 拦截器详解
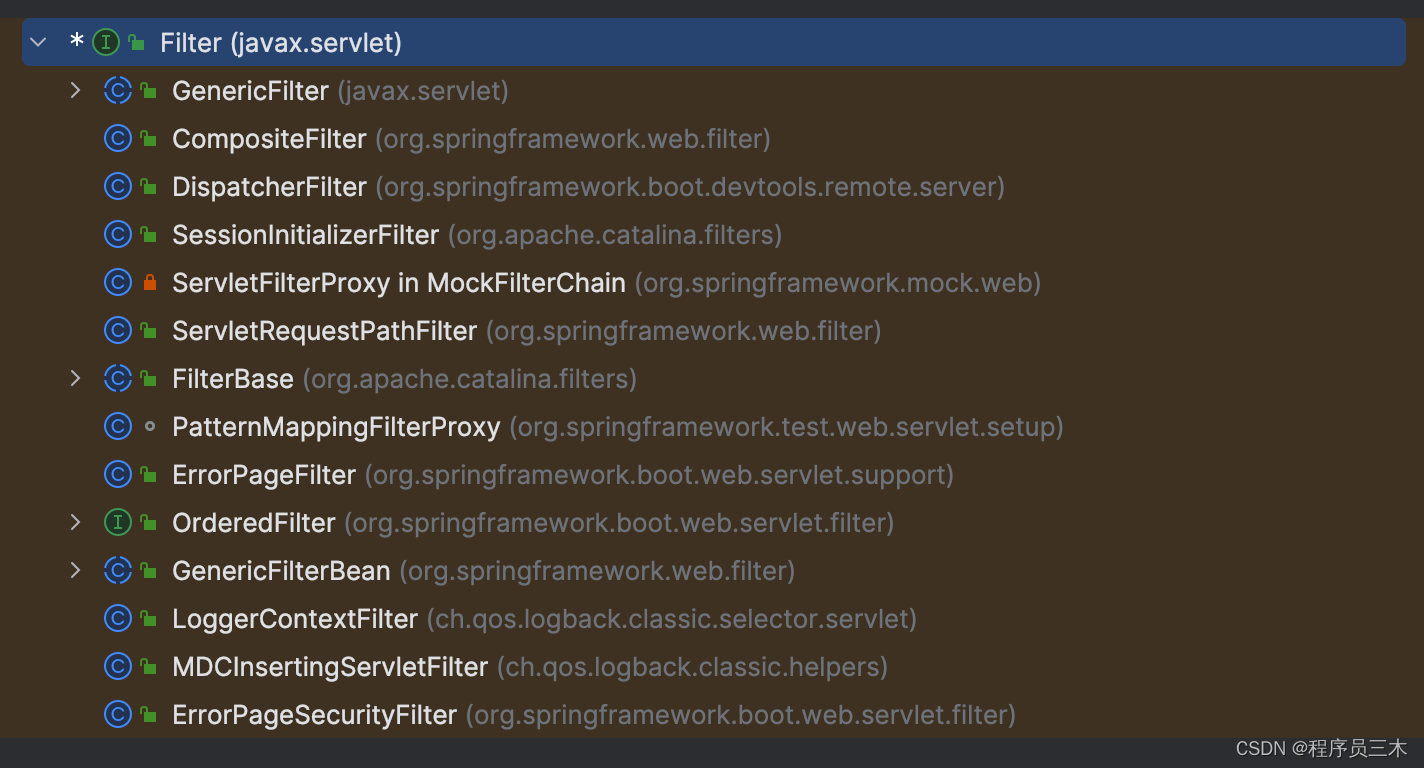
[AIGC] Spring Filter 过滤器详解
[实时流基础 flink] 窗口函数
MyBatis-Plus全套笔记三
电子好书发您分享《2023龙蜥操作系统全面拥抱智算时代分论坛》
电子好书发您分享《2023龙蜥操作系统大会全面进化 一云多芯分论坛》
电子好书发您分享《2023龙蜥操作系统大会全面繁荣开发者生态》
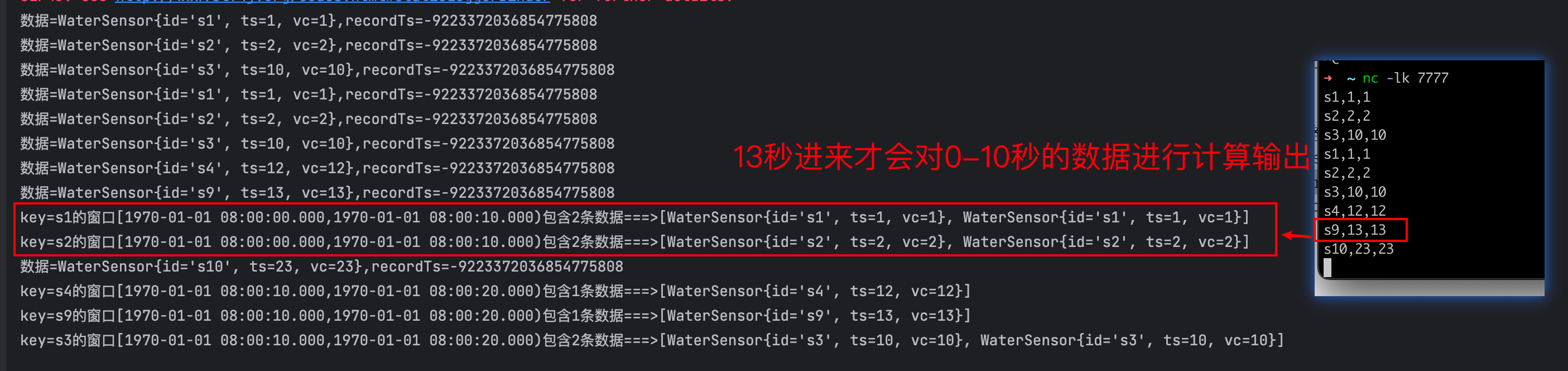
[实时流基础 flink] 窗口
10分钟搭建Kubernetes容器集群平台(kubeadm)
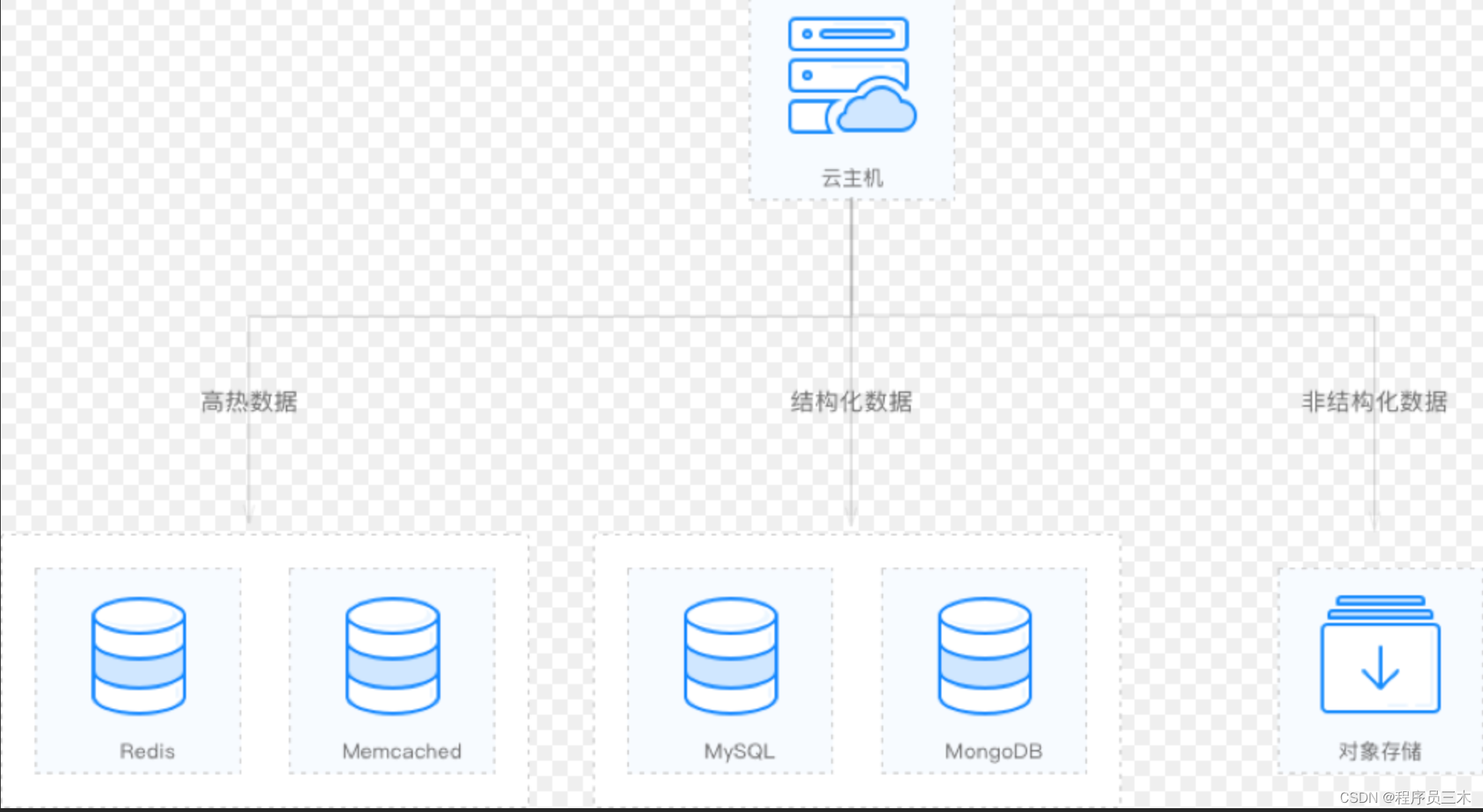
【Redis系列笔记】缓存三剑客
[leetcode] 哈希表
[flink 实时流基础] 输出算子(Sink)
javaSE&多态
[flink 实时流基础] 转换算子
MyBatis-Plus全套笔记二
[flink 实时流基础] flink 源算子
[flink 实时流基础]源算子和转换算子
网络安全与信息安全:防御前线的科学与策略
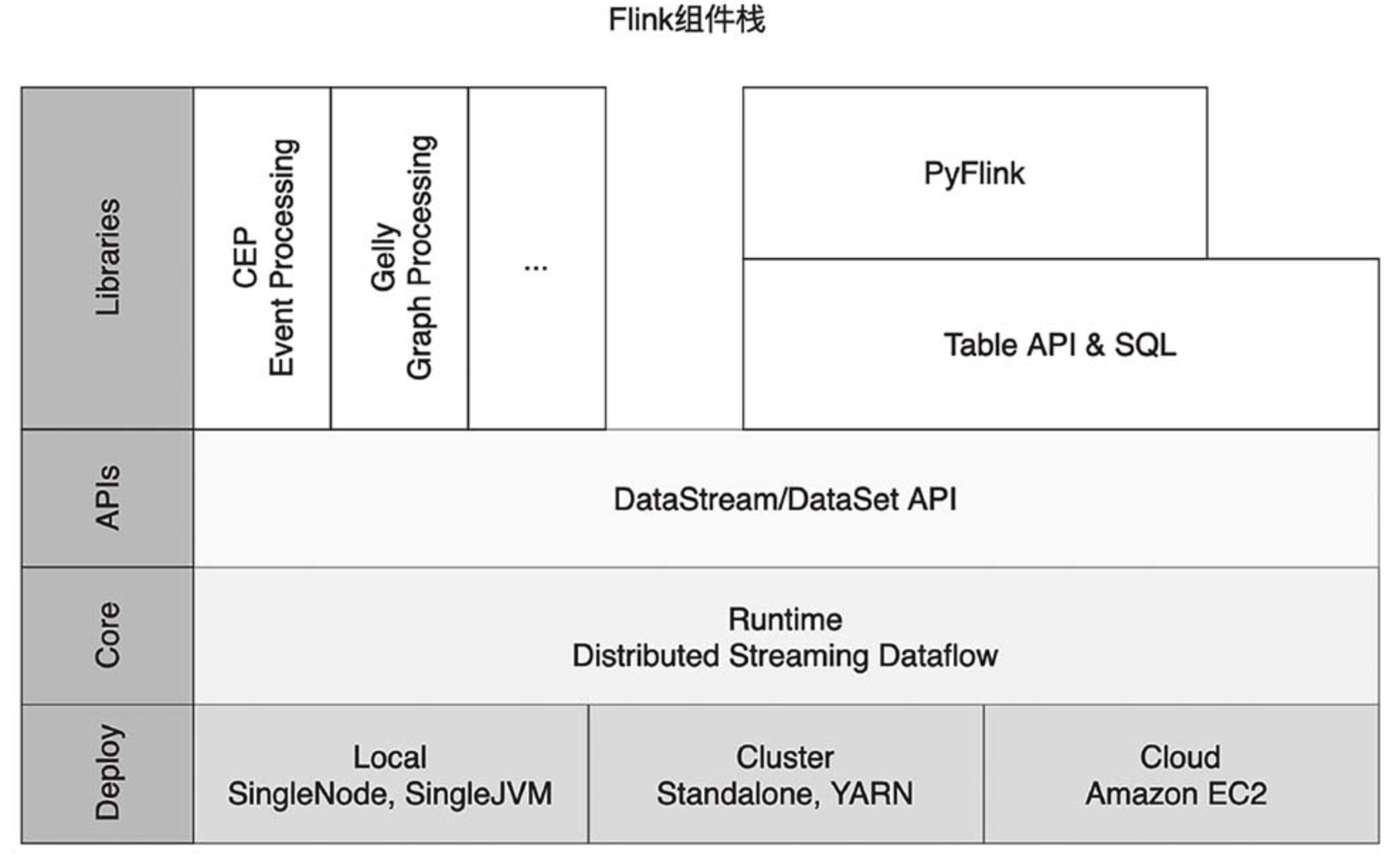
[flink 实时流基础] flink组件栈以及任务执行与资源划分
云计算环境下的网络安全策略与挑战
MyBatis-Plus全套笔记一
构建高效机器学习模型的策略与实践
探索人工智能在医疗诊断中的应用
[flink 实时流基础系列]揭开flink的什么面纱基础一
移动应用开发的未来:跨平台框架与原生操作系统的融合
揭秘深度学习中的优化算法
[flink] flink macm1pro 快速使用从零到一
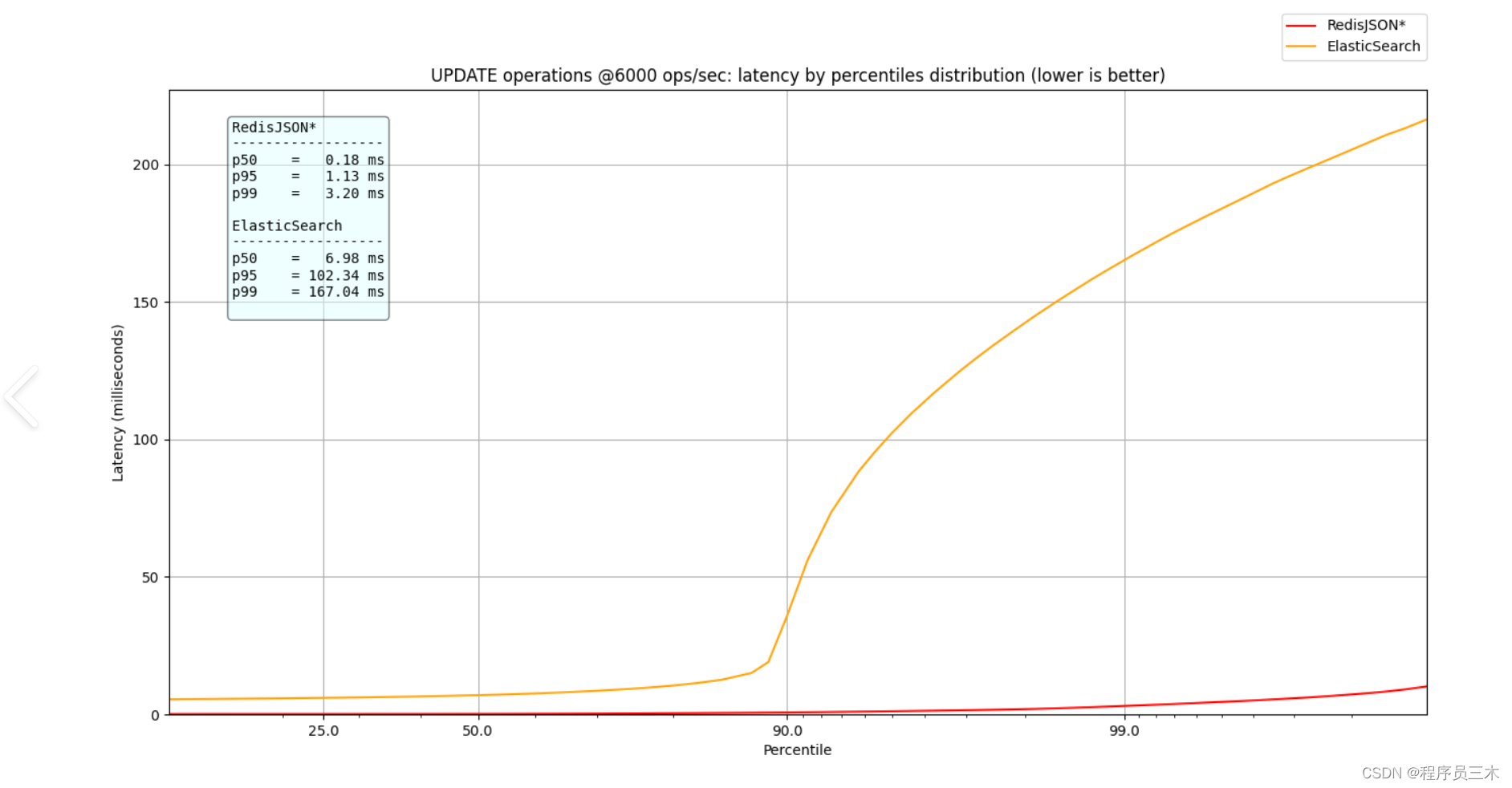
[AIGC] 对比MySQL全文索引,RedisSearch,和Elasticsearch的详细区别
[AIGC] 使用Spring Boot进行单元测试:一份指南
[AIGC] SQL中的数据添加和操作:数据类型介绍
[金三银四] 操作系统上下文切换系列
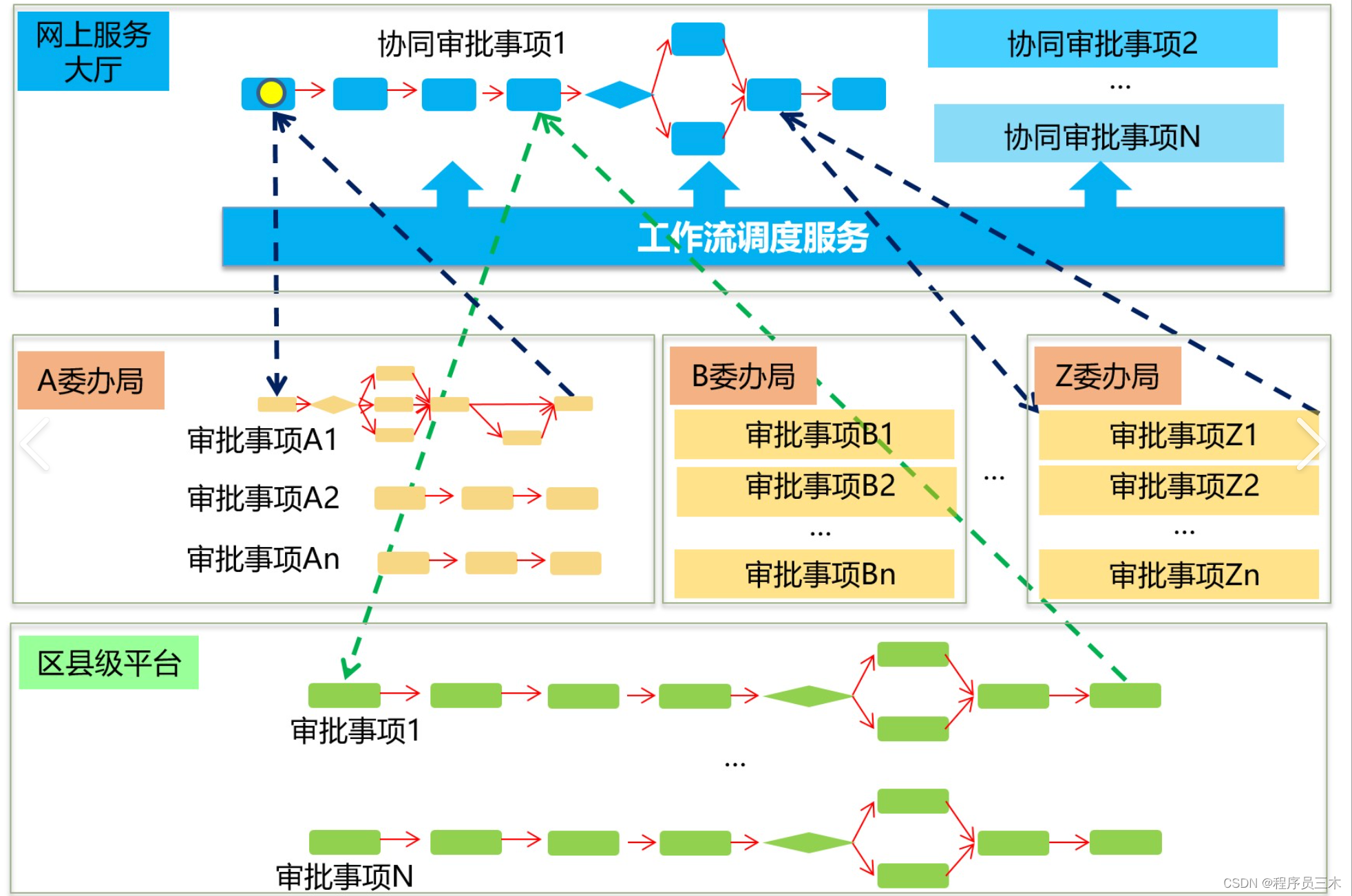
[AIGC] 工作流中的会签:概念与实现
淘汰算法
[AIGC] 主流工作流引擎对比与适用场景介绍
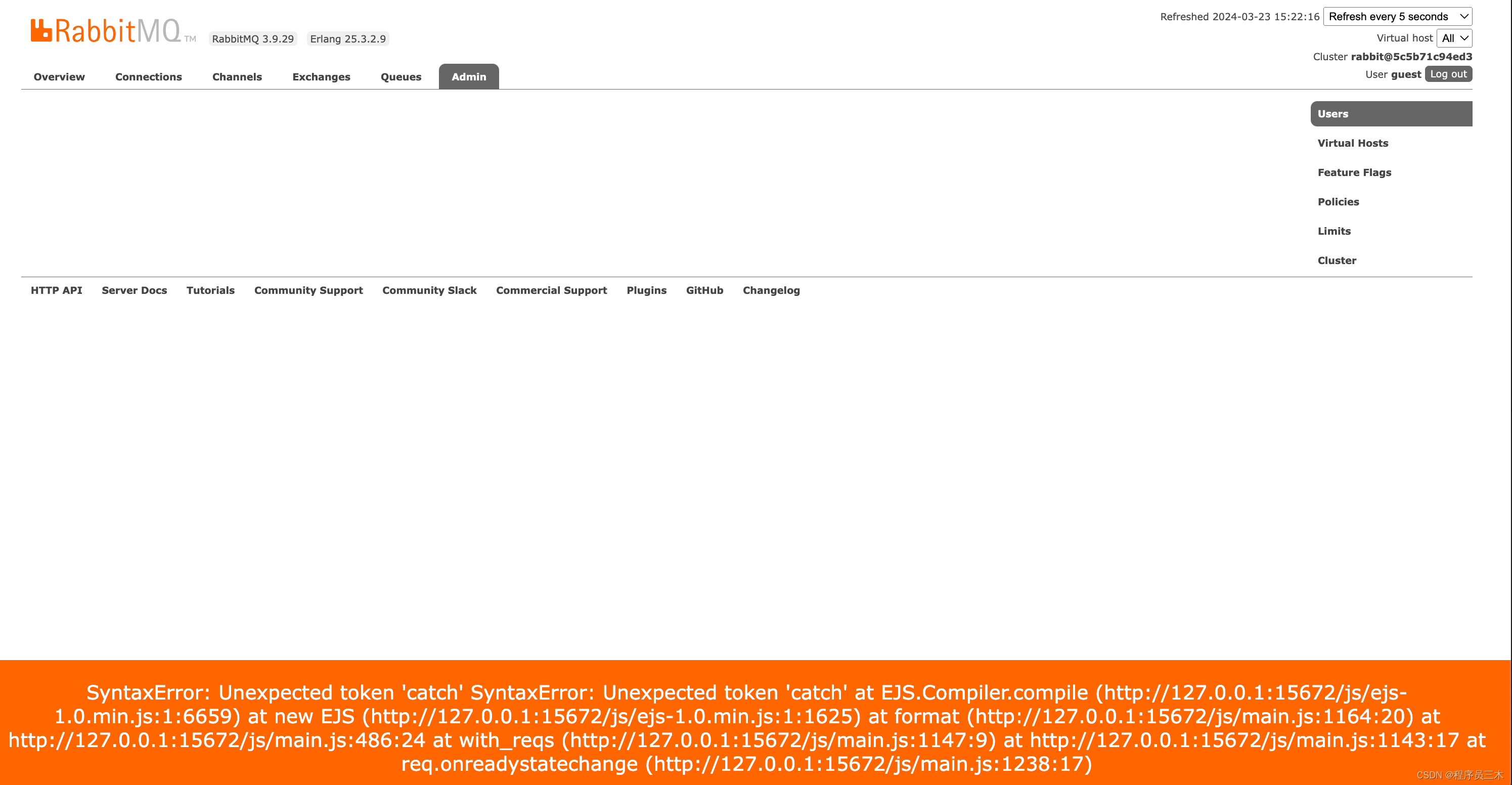
rabbitmq 3.9.29 docker mac 管理员页面无法打开
[AIGC] OkHttp:轻松实现网络请求
[Java探索者之路] Java中的AbstractQueuedSynchronizer(AQS)简介
[AIGC] 在Spring Boot中指定请求体格式