本文讲的是Kubernetes Scheduler是如何工作的【编者的话】本文描述了Kubernetes scheduler的工作流程以及出现失败如何实现重新调度的机制,文章的最后,作者对于Kubernetes的学习提出一些很有参考价值的建议。
【烧脑式Kubernetes实战训练营】本次培训理论结合实践,主要包括:Kubernetes架构和资源调度原理、Kubernetes DNS与服务发现、基于Kubernetes和Jenkins的持续部署方案 、Kubernetes网络部署实践、监控、日志、Kubernetes与云原生应用、在CentOS中部署Kubernetes集群、Kubernetes中的容器设计模式、开发Kubernetes原生应用步骤介绍等。
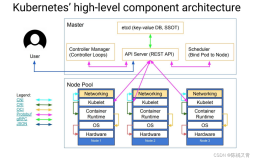
大家好!我们讨论了Kubernetes的 整体架构 。
这周我学习了Kubernetes scheduler如何工作并想跟大家分享。就是那种让人困惑的scheduler如何工作的。
这也是让你能不用问其他任何人,就可以从“这系统是怎么设计的,我对此一无所知”到“OK,我已经理解了基础的设计思想以及他们为什么这样设计”的解释(因为我不认识Kubernetes的任何一个贡献者,更不要说有那种能给我解释一下scheduler的了)。
这是个小小的意识流,但是希望对有些人有用。研究过程中我发现的最有用的链接是让人惊奇的Kubernetes 开发者文档文件夹 中的 Writing Controllers 。
scheduler并不负责运行pod,这是kubelet的工作。因此它只需要确保每个pod能分配到一个node。很简单,对吗?
Kubernetes一般都有controller的概念。Controller的工作是:
scheduler就是一种controller。有很多种controller,它们独立完成不同的工作和操作。
基本上你可以认为如下循环工作的:
如果你对Kubernetes scheduler的工作细节没有兴趣的话,那么你现在就可以停止阅读了——这是个scheduler工作原理的非常合理的模式。
我认为scheduler这么工作是因为这就是 cronjob controller 这样工作的,并且这是我已经阅读过的唯一的Kubernetes成员代码。Cronjob contrllor基本遍历所有的定时任务,查看这些任务是有事情要做,休眠10秒,然后一直重复。超级简单!
有时候pod会一直卡在Pending状态(也没有分配任何node给它)。如果重启scheduler,pod就会解卡。( issue )
这跟我心里认为的Kubernetes scheduler工作模型并不匹配——当然,如果pod在等着分配node,scheduler应该能注意到并且给pod分配node。Scheduler不应该需要重启!
因此我去看了一下代码。以下是我学到的scheduler实际上是如何工作的!像往常一样,这里有些可能是错误的,这东西太复杂了而且我也是这周才学的。
我们从 scheduler.go 开始。(实际上我把scheduler中所有 文件 都放到一起,这样很方便代码跳转和导航。)
scheduler中核心的循环在 链接 (commite4551d50e5)
这个代码的基本意思就是“一直运行sched.scheduleOne”。 酷,代码中怎么实现的呢?
接下来,NextPod()是做什么的呢?这段代码在哪儿定义的呢?
OK,这也很简单!有个pod的队列(podQueue),下一个处理的pod就是从这个队列里获取的。
但是pods是如何添加到那个队列里的呢?下面的代码完成相关动作:
有个事件处理句柄,当新的pod产生,就会被添加到pod队列中。
这里有个有趣的事情——如果pod因为任何原因调度失败的话,没有任何机制让scheduler充重试。Pod从队列中被取出,调度失败,然后就没有然后了。它失去了它唯一的一次机会。(除非你重启scheduler,这样所有的pod都会被重新加入到队列中)
当然scheduler更聪明一些,当pod调度失败,通常会调用失败句柄,例如:
调用sched.config.Error函数会把pod重新添加到调度队列中,完成重试功能。
那么为什么代替它使用的是更复杂的缓存、队列和回调呢?我追溯了一下发展过程觉得这主要是基于性能考虑的——举个例子,大家可以看到 Kubernetes1.6版本中可扩展性的更新 ,由CoreOS提交的关于 提高Kubernetes scheduler性能的帖子 。帖子中提到调度30,000个pod的时间从2小时缩短到了10分钟。2小时太慢了,性能是很重要的!
每次要在系统中调度一个新的pod,查询所有30,000个pod效率太低对我来说很值得注意,所以你真的想要做些复杂的事情。
这篇名为 writing controller 的文章非常有用,它在controller实现方面给出设计建议(例如scheduler或者cronjob controller)。非常酷!
如果我一开始就找到这篇文章,我想我会更快明白发生了什么。
关于informers,文章是这么说的:
cronjob controller不会用到informer(使用informer更复杂,我觉得它对性能还不太在意),但是很多其它的controller用informer。尤其是scheduler使用了informer!你可以看到它关于informer的 配置
Informers有个同步的概念。同步有点类似重启程序 – 你会获取到一个你监控的所有资源的列表,你可以检查资源是否正常。这里是“writing controllers”指导关于同步的描述。
Watch和informer会同步。他们周期性地把集群中匹配的对象传递到你的update方法。这对你需要这对对象做额外操作的场景是有好处的,但是你知道有时候并没有额外的操作需要做。
如果你很确定没有新更改,不需要项目重入队列,则可以比较旧对象和新对象资源的版本。如果版本一样,可以忽略重入队列。这么操作的是请仔细。如果出现失败的时候跳过队列重入,那个项目如果失败就不会重入队列,也就再也不会重试了。
数字0 – 这意味着重新同步周期,我理解为从不重新同步。有趣!!为什么不重新同步呢?我不确定,但我google了“kubernetes scheduler resync”,发现了一个pull请求 #16840 (添加scheduler 重新同步),后面有两个评论:
这是帮助我阅读代码的两件事情:
文档写的好,没文档的代码写的容易阅读,而且社区很愿意审核pull申请。
我绝对比平时更多地“阅读文档,如果没文档读代码”。这确实是个使人进步的好技能。
【烧脑式Kubernetes实战训练营】本次培训理论结合实践,主要包括:Kubernetes架构和资源调度原理、Kubernetes DNS与服务发现、基于Kubernetes和Jenkins的持续部署方案 、Kubernetes网络部署实践、监控、日志、Kubernetes与云原生应用、在CentOS中部署Kubernetes集群、Kubernetes中的容器设计模式、开发Kubernetes原生应用步骤介绍等。
大家好!我们讨论了Kubernetes的 整体架构 。
这周我学习了Kubernetes scheduler如何工作并想跟大家分享。就是那种让人困惑的scheduler如何工作的。
这也是让你能不用问其他任何人,就可以从“这系统是怎么设计的,我对此一无所知”到“OK,我已经理解了基础的设计思想以及他们为什么这样设计”的解释(因为我不认识Kubernetes的任何一个贡献者,更不要说有那种能给我解释一下scheduler的了)。
这是个小小的意识流,但是希望对有些人有用。研究过程中我发现的最有用的链接是让人惊奇的Kubernetes 开发者文档文件夹 中的 Writing Controllers 。
scheduler为谁工作
Kubernetes scheduler掌管pods到nodes的调度。基本如下:- 创建pod
- scheduler发现新创建的pod没有分配node
- scheduler为pod分配node
scheduler并不负责运行pod,这是kubelet的工作。因此它只需要确保每个pod能分配到一个node。很简单,对吗?
Kubernetes一般都有controller的概念。Controller的工作是:
- 查看系统状态;
- 真实状态和希望状态不匹配(例如pod需要分配node)的通知方式
- 重复
scheduler就是一种controller。有很多种controller,它们独立完成不同的工作和操作。
基本上你可以认为如下循环工作的:
while True: pods = get_all_pods() for pod in pods: if pod.node == nil: assignNode(pod)
如果你对Kubernetes scheduler的工作细节没有兴趣的话,那么你现在就可以停止阅读了——这是个scheduler工作原理的非常合理的模式。
我认为scheduler这么工作是因为这就是 cronjob controller 这样工作的,并且这是我已经阅读过的唯一的Kubernetes成员代码。Cronjob contrllor基本遍历所有的定时任务,查看这些任务是有事情要做,休眠10秒,然后一直重复。超级简单!
它并不是这么工作的
这周我们在Kubernetes集群增加了一些负载,一个问题引起了我们的注意。有时候pod会一直卡在Pending状态(也没有分配任何node给它)。如果重启scheduler,pod就会解卡。( issue )
这跟我心里认为的Kubernetes scheduler工作模型并不匹配——当然,如果pod在等着分配node,scheduler应该能注意到并且给pod分配node。Scheduler不应该需要重启!
因此我去看了一下代码。以下是我学到的scheduler实际上是如何工作的!像往常一样,这里有些可能是错误的,这东西太复杂了而且我也是这周才学的。
Scheduler是怎么工作的:代码快速介绍
这些基本就是我从代码阅读中理解到的。我们从 scheduler.go 开始。(实际上我把scheduler中所有 文件 都放到一起,这样很方便代码跳转和导航。)
scheduler中核心的循环在 链接 (commite4551d50e5)
go wait.Until(sched.scheduleOne, 0, sched.config.StopEverything)
这个代码的基本意思就是“一直运行sched.scheduleOne”。 酷,代码中怎么实现的呢?
func (sched *Scheduler) scheduleOne() {
pod := sched.config.NextPod()
// do all the scheduler stuff for `pod`
}
接下来,NextPod()是做什么的呢?这段代码在哪儿定义的呢?
func (f *ConfigFactory) getNextPod() *v1.Pod {
for {
pod := cache.Pop(f.podQueue).(*v1.Pod)
if f.ResponsibleForPod(pod) {
glog.V(4).Infof("About to try and schedule pod %v", pod.Name)
return pod
}
}
}
OK,这也很简单!有个pod的队列(podQueue),下一个处理的pod就是从这个队列里获取的。
但是pods是如何添加到那个队列里的呢?下面的代码完成相关动作:
podInformer.Informer().AddEventHandler(
cache.FilteringResourceEventHandler{
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
if err := c.podQueue.Add(obj); err != nil {
runtime.HandleError(fmt.Errorf("unable to queue %T: %v", obj, err))
}
},
有个事件处理句柄,当新的pod产生,就会被添加到pod队列中。
Scheduler如何工作
我们已经研究过代码了,接下来是相关的总结:- 开始的时候,每个pod需要被调度添加到队列中;
- 当新的pod被创建,它们也要被添加到队列中;
- scheduler不断的从队列中取出pod调度;
- 以上
这里有个有趣的事情——如果pod因为任何原因调度失败的话,没有任何机制让scheduler充重试。Pod从队列中被取出,调度失败,然后就没有然后了。它失去了它唯一的一次机会。(除非你重启scheduler,这样所有的pod都会被重新加入到队列中)
当然scheduler更聪明一些,当pod调度失败,通常会调用失败句柄,例如:
host, err := sched.config.Algorithm.Schedule(pod, sched.config.NodeLister)
if err != nil {
glog.V(1).Infof("Failed to schedule pod: %v/%v", pod.Namespace, pod.Name)
sched.config.Error(pod, err)
调用sched.config.Error函数会把pod重新添加到调度队列中,完成重试功能。
等等,那为什么我们的pod卡住了呢?
这很简单——说明Error函数并不是出现error的时候总被调用。我们打了个补丁,在出现error的时候合适的调用Error函数,目前看上去修复了这个问题。酷!为什么scheduler这么设计?
我觉得这么设计更牛:host, err := sched.config.Algorithm.Schedule(pod, sched.config.NodeLister)
if err != nil {
glog.V(1).Infof("Failed to schedule pod: %v/%v", pod.Namespace, pod.Name)
sched.config.Error(pod, err)
那么为什么代替它使用的是更复杂的缓存、队列和回调呢?我追溯了一下发展过程觉得这主要是基于性能考虑的——举个例子,大家可以看到 Kubernetes1.6版本中可扩展性的更新 ,由CoreOS提交的关于 提高Kubernetes scheduler性能的帖子 。帖子中提到调度30,000个pod的时间从2小时缩短到了10分钟。2小时太慢了,性能是很重要的!
每次要在系统中调度一个新的pod,查询所有30,000个pod效率太低对我来说很值得注意,所以你真的想要做些复杂的事情。
Kubernetes到底用的什么:Kubernetes informers
我想讨论我所学到的,似乎是所有关于Kubernetes controller设计非常重要的事情。“informer”的概念。幸运的是确实能通过谷歌搜索“Kubernetes informer”获得相关的文档。这篇名为 writing controller 的文章非常有用,它在controller实现方面给出设计建议(例如scheduler或者cronjob controller)。非常酷!
如果我一开始就找到这篇文章,我想我会更快明白发生了什么。
关于informers,文章是这么说的:
使用共享informers。 共享informers为指定的资源提供钩子,用来接收添加、更改和删除的通知。它们也提供了很便利的函数访问共享缓存和决定什么时候使用缓存。基本上,当controller运行的时候会创建“informer”,(例如pod informer),主要管理:
- 首先列出所有pods;
- 告诉你所有的更新;
cronjob controller不会用到informer(使用informer更复杂,我觉得它对性能还不太在意),但是很多其它的controller用informer。尤其是scheduler使用了informer!你可以看到它关于informer的 配置
队列重入
这有一些“writing controllers”文档中遇到的关于如何处理重入队列条目的指引。过滤错误到最高等级,以实现一致的队列重入。workqueue.RateLimitingInterface 提供合理的支撑,允许简单的队列重入。这看上去是个不错的建议,正确处理所有错误似乎有点难,所以有个简单的方法确保评审可以确认所有错误都被正确处理很重要!酷!
你的main controller函数在需要重入队列的时候返回错误。如果不这样,会使用utilruntime.HandleError并且返回nil。这让评审很容易检查错误处理的case,并且有信心相信你的controller不会偶然丢弃那些它应该重试的操作。
你应该同步你的informers(应该吧?)
好的,这里是我学到的最后一个有趣的事情。Informers有个同步的概念。同步有点类似重启程序 – 你会获取到一个你监控的所有资源的列表,你可以检查资源是否正常。这里是“writing controllers”指导关于同步的描述。
Watch和informer会同步。他们周期性地把集群中匹配的对象传递到你的update方法。这对你需要这对对象做额外操作的场景是有好处的,但是你知道有时候并没有额外的操作需要做。
如果你很确定没有新更改,不需要项目重入队列,则可以比较旧对象和新对象资源的版本。如果版本一样,可以忽略重入队列。这么操作的是请仔细。如果出现失败的时候跳过队列重入,那个项目如果失败就不会重入队列,也就再也不会重试了。
Kubernetes scheduler并不重新同步
接下来,自从我了解了同步的概念,我想。。。。。。等等,这是不是意味着Kubernetes scheduler从不重新同步?答案似乎是“是的,不重新同步!”。代码如下:informerFactory := informers.NewSharedInformerFactory(kubecli, 0) // cache only non-terminal pods podInformer := factory.NewPodInformer(kubecli, 0)`
数字0 – 这意味着重新同步周期,我理解为从不重新同步。有趣!!为什么不重新同步呢?我不确定,但我google了“kubernetes scheduler resync”,发现了一个pull请求 #16840 (添加scheduler 重新同步),后面有两个评论:
@brendandburns – 这是为了修复什么?我反对这么小的重新同步周期,这会很严重的影响性能和
同意@ wojtek-t。如果重新同步修复了一个问题,这意味着我们隐藏了一个潜在的要修改的bug。 我不认为resync是正确的解决方案。看上去项目管理员决定不做resync,因为当有需要修复bug的时候,他们希望它能浮出水面并修复而不是用resync把它隐藏起来。
代码阅读的一些建议
据我所知,“Kubernetes scheduler内部是如何工作的”哪儿都没有写(就像大多数事情一样!)。这是帮助我阅读代码的两件事情:
- 把整个代码链接成一个大文件。我已经提过这个,但是这个确实帮助我在函数调用的时候跳转 – 文件之间切换很让人困惑,特别是当我还不清楚整体代码架构的时候!
- 有一些具体的问题。这里我想要解释清楚“错误处理应该怎么工作?如果pod没有被调度会发生什么?”有一些关于类似怎么选择pod调度的node的代码细节,我并不需要太在意(我还是不知道它是怎么工作的)
到目前为止Kubernetes是非常好用的
Kubernetes确实是一份很复杂的代码!要使得集群正常工作,你需要安装至少六个组件(api server, scheduler, controller manager, 容器网络例如flannel, kube-proxy以及kubelet)。因此(如果要十分了解你所运行的软件)为了达到我所需要的目的,我不得不理解所有组件、它们之间如何交互以及如何配置它们拿一大堆参数。文档写的好,没文档的代码写的容易阅读,而且社区很愿意审核pull申请。
我绝对比平时更多地“阅读文档,如果没文档读代码”。这确实是个使人进步的好技能。
原文链接:How does the Kubernetes scheduler work?(翻译:李桦)
原文发布时间为:2017-08-23
本文作者:xiao_ye2000
本文来自云栖社区合作伙伴Dockerone.io,了解相关信息可以关注Dockerone.io。
原文标题:Kubernetes Scheduler是如何工作的