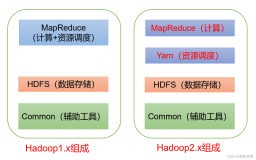
▲2011年Hadoop in China大会专题
2012年,Hadoop必将风靡世界。以下是六个具体的理由:
1.投资者看好Hadoop
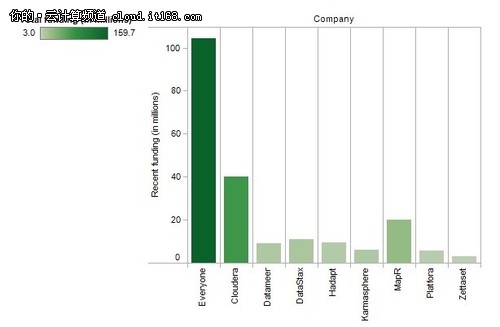
目前,投资者十分看好Hadoop,并开始纷纷投资相关技术。从分布式层面上来说,Hadoop开源软件整体方案供应商Cloudera已获得7600万美元投资,分布式架构新成员MapR和Hortonworks分别融资2900万美元和5000万美元;而从栈的层面上来看,Hadoop海量数据分析平台Datameer、 Karmasphere和Hadapt已分别获得了1000万美元左右投资。大量专注这一技术的初创公司(如Zettaset、Odiago和Platfora等)更是如雨后春笋般迅速涌现。另外,投资机构Accel Partners最近还成立了一个总额为1亿美金的大型数据基金,专门用于投资基于Hadoop和其他核心大型数据技术的应用。
▲
2.竞争孕育成功
Hadoop必将是未来的发展趋势,尤其是当涉及到集成管理等业务问题时。Hadoop也是Cloudera、MapR和Hortonworks能在赢取客户资源方面具有明显竞争优势的原因。
3.学习曲线
除了改善在分布式层面的管理和支持能力外,Cloudera、MapR和Hortonworks等公司已经开始着手提高Hadoop的易用性。同时,Karmasphere和Concurrent公司也已开始提供编写Hadoop流程和应用服务,而Datameer和IBM等公司正在努力将Hadoop普及到普通商业用户。随着越来越多的Hapdoop创业公司涌现,通过各种创新方法简化繁重的数据分析工作也将变得越来越常见。
4.用户是永远的黄金准则
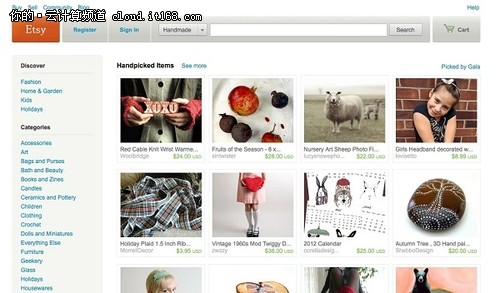
懂得任何管理Hadoop集群和编写Hadoop应用是一回事,而将它有效地用于实际的分析管理却是另外一回事。在Hadoop World大会和网络博客上经常可以看到Walt Disney、Orbitz、LinkedIn、和Etsy等很多大公司通过讲述自己的亲身实践大赞Hadoop。用户口碑永远是最有效的宣传途径。这些大用户的“亲身试法”,对很多潜在用户来说是一种无形的鼓励,也能在一定程度上帮助他们认识“从何开始、去往何处”的问题。
▲
5.无处不在的用武之地
像Oracle、MySQL和SQL Server等老牌数据库一样,虽然人们对此了解不多也不深,且容易被忽视,但它们无处不在,几乎所有人都听过。从长远来看,Hadoop也将发展到类似阶段。一旦遇到涉及大量非结构化的数据采集和处理时,Hadoop就有了用武之地。
6.内容多,功能强大
除了核心设计思想MapReduce和HDFS(Hadoop Distributed File System)外,Hadoop还包括了从类SQL查询语言HQL,到NoSQL HBase数据库,以及机器学习库Mahout等内容。Cloudera、Hortonworks和MapR都已在他们的分布式系统中加入了Hadoop项目。最近,Cloudera还成立一个名为Bigtop的项目,集成了所有Hadoop相关项目。作为一个幕后英雄,Hadoop未来必将应用于越来越多的领域,风靡全球。

▲
原文发布时间为:2011-11-28
本文作者: 唐蓉
本文来自云栖社区合作伙伴IT168,了解相关信息可以关注IT168。