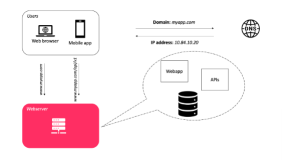
本文讲的是云平台如何支持百万千万或者上亿用户?,在云计算发展飞速的时代,传统通讯正在与互联网、IT等各大领域融合发展,无论是IM、视频、VoIP、还是呼叫中心,企业都需要根据自身业务形态开发和部署属于自己的通讯平台。那么,在用户群体不断壮大之时,云平台如何该支持百万千万或者上亿的在线用户?日前, 容联云通讯CTO(首席技术官)许志强为程序员们带来了一场主题为“云通讯PaaS平台的挑战和应对之道”的在线培训。
一个云平台怎么支持百万千万或者上亿的在线用户?许志强认为这里有几个关键点:
1、操作系统调优
第一步是操作系统的调优,因为操作系统的缺省设置并不是适合这种大规模的系统访问的,包括打开文件数、TCP接收发送缓冲等,你需要根据你的业务请将操作系统各项的参数设置进行一个调优。
2、采用异步接口
第二步,因为现在大多数的网络协议都是基于TCPIP协议的,客户端在很多情况下是非活跃的,那么要单台机器处理几十万或者上百万以上的连接需要采用异步的接口。在Linux上使用的是epoll,在windows上就是I/O Completion Port. 十年前,我们会讨论一台Web服务器怎么支撑一万个用户(著名的C10K问题),现在这个问题已经随着操作系统的完善已经非常轻易的解决了,关键是怎么使用操作系统提供的这些接口。现在如果采用长连接,目前的技术水平达到几十万甚至上百万(依赖实际的吞吐量)的长连接单台服务器是没有任何问题的。
3、内存数据库缓存、减少数据库操作
第三点,我们知道数据库的操作是比较重的,像内存数据有可能用(Memcache、Redis)或者各种内存数据库缓存一些数据,减少数据库的操作,衡量哪些数据放内存数据库中的一个重要原则就是: 如果数据访问比较频繁,可以通过key访问,业务逻辑上不需要强一致的数据适合放内存数据库。
4、内部模块交换采用长连接、Protocol Buffer等
系统内部尽可能采用长连接,因为系统的每一次连接都是一个开销,可能在低负载情况下没有关系,每次请求一个连接,看上去也挺快,一秒钟几百个请求,一千多请求也行,但是一旦系统负荷增大,这部分开销在整个系统开销就会非常大了。另外在协议编码的尽可能采用像Protocol Buffer的协议,这是谷歌开源的协议,具有很好的编解码效率和传输流量优化。
5、节点可并行扩展、Cluster集群
设计的时候需要考虑各个模块、节点是否可并行扩展的?是不是增加一个模块、节点就能够提供服务扩展系统容量?将每个节点尽可能做成无状态的,只有做到这点,系统才能可扩展、才能做集群、才能采用Cluster集群来做负载均衡服务。
6、自动部署新业务节点支持服务的自动化扩容
云服务的用户可能突然业务量大增,系统能不能通过自动部署解决弹性自动扩容?这是云通讯现在正在做的。我们跟运营商的线路不是可以通过动态增加的,那是物理接口没有办法增加的。但是针对IP端的设备我们是可以做自动部署的,像阿里云、亚马逊,可以提供API让你自动地创建虚拟的主机,你可以提前做好相应的磁盘映像, 当检测到某个类型的设备负责过高后,可以通过接口把这个服务部署起来。当你业务节点快速增加的时候,你采用这种自动部署的方案可以大幅减少人工干预维护的工作。
7.一次性Hash的负载分配方式
讲到集群,就必须说的是集群中负载的分配方式。举个例子,之前阿里云余额宝是从IOE架构移到阿里云上,当时存在一个很大的一个挑战,余额宝的请求量太大了,mysql数据库性能不够,怎么解决这个问题呢? 常见的方法就是根据账号分数据库、分系统处理,按照账号分配到对应的数据库和处理系统, 这就是负载分配的方式。一般来说,大家一个很直观的想法可能是根据这个帐号做一下hash计算。有三个节点,就除三,余数在哪儿就去哪个节点,这是惯用的思路。但是这里有一个问题,之前的三个节点,后来可能变成四个节点,五个节点,一旦变成四个节点,五个节点以后,原来的Hash的值就不对了,如果加了一个节点以后,后面所有的分配都会不对,数据库什么都要重新调整,整个负载会剧烈的进行一个移动,对增加处理节点是不友好的。
下面是百度上的一个图,这个是一次性Hash的负载分配方式:
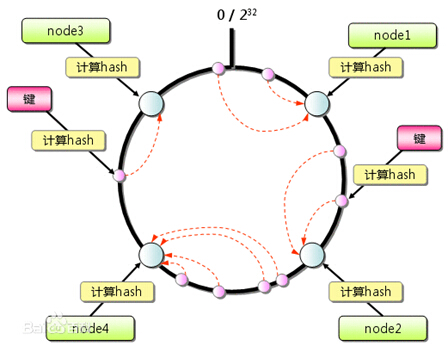
假如这是一个环,这个环是从0到2的32次方,我们保证Hash出来的值在这个区间内随机分布。在这个区间内,我们这里只有四个节点,图中蓝色的节点是我们的服务节点。当一个请求来了,或者一个帐号来了,这个请求是由谁来服务呢?我们把这个请求计算一个hash,hash值会落在这个环的其中一个点上,就是图中的这个紫色的点。紫色的点实际上不是一个具体的服务点,它会按方向找最近的点,假如我们以顺时针方向,他就找顺时针最近的一个点。假如在第三和四节点之间,这两个节点的负载增加了,我们就在这两个节点中间加一个节点,把他们中间的负载做一个分担,这样其他的节点负责的这种负载请求不会波动不会发生变化。只有落在我们分配的节点顺时针之前的节点会有一些变化。所以这样就非常容易把一个节点加到里面不影响整个系统的动荡。