
前两期小帮为大家介绍了仁人帮的大数据定义与大数据在仁人帮后台的应用。今天也不跟大家卖关子了,接下来,小帮为大家奉上的是大数据平台技术的探索。
大数据技术,小帮认为可以分成两个大的层面,大数据平台技术与大数据应用技术。要使用大数据,你先必须有计算能力,大数据平台技术包括了数据的采集,存储,流转,加工所需要的底层技术,如hadoop生态圈,数加生态圈。
数据的应用技术是指对数据进行加工,把数据转化成商业价值的技术,如算法,以及由算法衍生出来的模型,引擎,接口,产品等等。这些数据加工的底层平台,包括平台层的工具,以及平台上运行的算法,也可以沉淀到一个大数据的生态市场中,避免重复的研发,大大的提高大数据的处理效率。
大数据首先需要有数据,数据首先要解决采集与存储的问题,数据采集与存储技术,随着数据量的爆发与大数据业务的飞速发展,也是在不停的进化过程中。
在大数据的早期,或者很多企业的发展初期,是只有关系型数据库用来存储核心业务数据,就算数据仓库,也是集中型OLAP关系型数据库。比如很多企业,包括淘宝早期,就用Oracle作为数据仓库来存储数据,当时建立了亚洲最大的Oracle RAC作为数据仓库,按当时的规模来说,可以处理10T以下的数据规模 。
一旦出现独立的数据仓库,就会涉及到ETL,如数据的抽取,数据清洗,数据校验,数据导入甚至数据安全脱敏。如果数据来源仅仅是业务数据库,ETL还不会很复杂。如果数据的来源是多方的,比如日志数据,APP数据,爬虫数据,购买的数据,整合的数据等等,ETL就会变得很复杂,数据清洗与校验的任务就会变得很重要。
这时的ETL必须配合数据标准来实施,如果没有数据标准的ETL,可能会导致数据仓库中的数据都是不准确的,错误的大数据就会导致上层数据应用,数据产品的结果都是错误的。错误的大数据结论,还不如没有大数据。由此可见,数据标准与ETL中的数据清洗,数据校验是非常的重要。
最后,随着数据的来源变多,数据的使用者变多,整个大数据流转就变成了一个非常复杂的网状拓扑结构,每个人都在导入数据,清洗数据,同时每个人也都在使用数据,但是,谁都不相信对方导入,清洗的数据,就会导致重复数据越来越多,数据任务也越来越多,任务的关系越来越复杂。要解决这样的问题,必须引入数据管理,也就是针对大数据的管理。比如元数据标准,公共数据服务层(可信数据层),数据使用信息披露等等。
随着数据量的继续增长,集中式的关系型OLAP数仓已经不能解决企业的问题,这个时候出现了基于MPP的专业级的数据仓库处理软件 ,如GreenPlum。greenplum采用了MPP方式处理数据,可以处理的数据更多,更快,但是本质上还是数据库的技术。Greenplum支持100台机器规模左右,可以处理PB级别数据量。Greenplum产品是基于流行的PostgreSQL之上开发,几乎所有的PostgreSQL客户端工具及PostgreSQL应用都能运行在Greenplum平台上,在Internet上有着丰富的PostgreSQL资源供用户参考。
随着数据量的继续增加,比如阿里每天需要处理100PB以上数据,每天有100万以上的大数据任务。以上的解决方案发现都没有办法来解决了,这个时候,就出现了一些更大的基于M/R分布式的解决方案,如大数据技术生态体系中的Hadoop,Spark和Storm。他们是目前最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Storm常用于在线的实时的大数据处理。以及阿里云推出的数加,它也包括了大数据计算服务MaxCompute(前ODPS),关系型数据库ADS(类似Impala),以及基于Java的Storm系统JStorm(前Galaxy)。
我们看看大数据技术生态中的不同解决方案,也对比看看阿里云数加的解决方案,最后我也会单独介绍数加。
1、大数据生态技术体系
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。Hadoop作为一个基础框架,上面也可以承载很多其它东西,比如Hive,不想用程序语言开发MapReduce的人,熟悉SQL的人可以使用Hive开离线的进行数据处理与分析工作。比如HBase,作为面向列的数据库运行在HDFS之上,HDFS缺乏随即读写操作,HBase正是为此而出现,HBase是一个分布式的、面向列的开源数据库。
Spark也是Apache基金会的开源项目,它由加州大学伯克利分校的实验室开发,是另外一种重要的分布式计算系统。Spark与Hadoop最大的不同点在于,Hadoop使用硬盘来存储数据,而Spark使用内存来存储数据,因此Spark可以提供超过Hadoop100倍的运算速度。Spark可以通过YARN(另一种资源协调者)在Hadoop集群中运行,但是现在的Spark也在往生态走,希望能够上下游通吃,一套技术栈解决大家多种需求。比如Spark Shark,是为了VS hadoop Hive,Spark Streaming是为了VS Storm。
Storm是Twitter主推的分布式计算系统,它由BackType团队开发,是Apache基金会的孵化项目。它在Hadoop的基础上提供了实时运算的特性,可以实时的处理大数据流。不同于Hadoop和Spark,Storm不进行数据的收集和存储工作,它直接通过网络实时的接受数据并且实时的处理数据,然后直接通过网络实时的传回结果。Storm擅长处理实时流式。比如日志,比如网站购物的点击流,是源源不断、按顺序的、没有终结的,所以通过Kafka等消息队列来了数据后,Storm就一边开始工作。Storm自己不收集数据也不存储数据,随来随处理随输出结果。
其上的模块只是大规模分布式计算底层的通用框架,通常也用计算引擎来描述他们。
除了计算引擎,想要做数据的加工应用,我们还需要一些平台工具,如开发IDE,作业调度系统,数据同步工具,BI模块,数据管理,监控报警等等,他们与计算引擎一起,构成大数据的基础平台。
在这个平台上,我们就可以基于数据做大数据的加工应用,开发数据应用产品了。
比如一个餐厅,为了做中餐,西餐,日料,西班牙菜,它必须食材(数据),配合不同的厨具(大数据底层计算引擎),加上不同的佐料(加工工具)才能做出做出不同类型的菜系;但是为了接待大批量的客人,他必须配备更大的厨房空间,更强的厨具,更多的厨师(分布式);做的菜到底好吃不好吃,这又得看厨师的水平(大数据加工,应用能力)。
2、阿里大数据体系
我们先看一下阿里的计算引擎三件套。
阿里云最早先使用Hadoop解决方案,并且成功的把Hadoop单集群规模扩展到5000台规模。2010年起,阿里云开始独立研发了类似Hadoop的分布式计算平台Maxcompute平台(前ODPS,https://www.aliyun.com/product/odps),目前单集群规模过万台,并支持多集群联合计算,可以在6个小时内处理完100PB的数据量,相当于一亿部高清电影。
分析型数据库服务ADS(AnalyticDB) ,是一套RT-OLAP(Realtime OLAP,实时 OLAP)系统。在数据存储模型上,采用自由灵活的关系模型存储,可以使用 SQL进行自由灵活的计算分析,无需预先建模;而利用分布式计算技术,ADS可以在处理百亿条甚至更多量级的数据上达到甚至超越MOLAP类系统的处理性能,真正实现百亿数据毫秒级计算。ADS是采用搜索+数据库技术的数据高度预分布类MPP架构,初始成本相对比较高,但是查询速度极快,高并发。而类似的产品Impala,采用Dremel数据结构的低预分布MPP架构,初始化成本相对比较低,并发与响应速度也相当慢一些。
流计算产品(前Galaxy),可以针对大规模流动数据在不断变化运动过程中实时的进行分析 ,是阿里巴巴开源的基于Storm采用Java重写的一套分布式实时流计算框架,也叫JStorm,对比产品是Storm或者是Spark Streaming。最近阿里云会开始公测stream sql,通过sql 的方式来实现实时的流式计算,降低了使用流式计算技术的使用门槛。
说了这么多,可能大家会觉得无聊。这和咱们仁人帮有什么关系呢。全部都是一些专业化的术语,不了解大数据的人跟看天书一样。
其实,仁人帮未来的走向必将以学习阿里在商业中使用大数据的方式作为参考标准。
数据存储只是一个部分。就在2017年9月29日,仁人帮注册用户已经达到10万级。从10万到100万用户,时间会非常短,估计会在半年左右内完成。如何保证后台数据的稳定性成为仁人帮必须要面对或者功课的难题。从用户发布的数据,到用户行为数据,到日志数据,等等对于我们来说都是一笔宝贵的财富。不会使用大数据分析的企业,无异于“坐在金山啃馒头”。那么使用何种数据引擎成了我们技术部最关心的话题。刚开始创业团队规模小、资金少,且时刻会面临用户爆炸式增长的情况,所以初期架构设计非常重要。仁人帮APP架构就是依赖于阿里云搭建而成,从开始的一台云服务器扩展到现在的接近10台服务器的规模。首先系统做到集群化设计,无单点,且支持纵横扩容。同时系统可模块化拆分,数据存储应做到持久化存储。
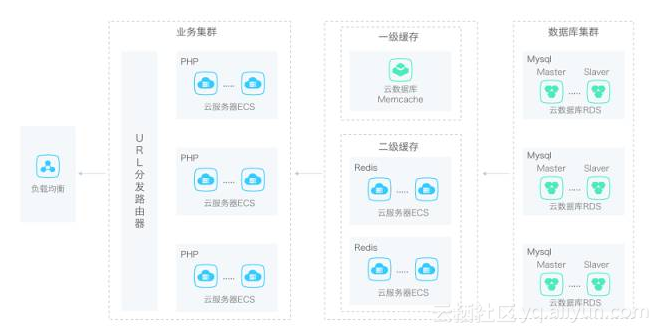
通过负载均衡的解决方案,我们使用移动域名解析解决方案,移动加速解决方案,移动安全解决方案。通过URL分发路由的方式,实现寻找最优解析路径的方式,通过一级二级缓存加快流速。通过数据库集群设计,增加处理数据的效率。此外,我们还打算基于阿里云搭建了BI系统。最后,为了缓解自建大数据集群的规模较小的情况,积极采用阿里云大数据平台对数据进行分析和处理计算。
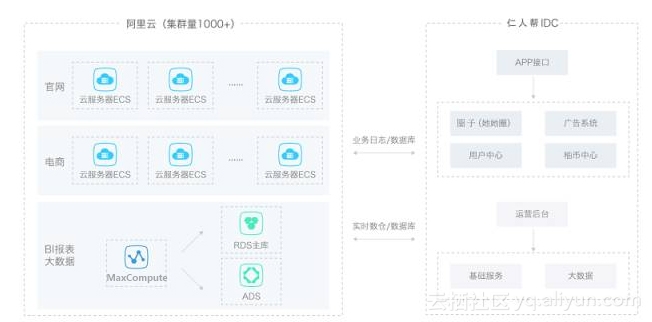
未来,仁人帮会加入广告植入和互换模式,这需要不同系统,不同来源的数据加以统计和分析,进而与合作商达到合作共赢,科学管理的方式。大规模和普遍的合作所产生的数据对仁人帮将会是一个不小的考验。仁人帮愿意接受各种考验,我们也将在核心算法上不断完善,剔除垃圾数据。提升响应体验。
今天就聊到这了,咱们下期再见吧!
阿里巴巴大数据-玩家社区 https://yq.aliyun.com/teams/6/
---阿里大数据博文,问答,社群,实践,有朋自远方来,不亦说乎……

