这是一篇总结文,总结我看过的几篇用GAN做图像翻译的文章的“套路”。
首先,什么是图像翻译?
为了说清楚这个问题,下面我给出一个不严谨的形式化定义。我们先来看两个概念。第一个概念是图像内容(content) 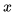 ,它是图像的固有内容,是区分不同图像的依据。第二个概念是图像域(domain),域内的图像可以认为是图像内容被赋予了某些相同的属性。举个例子,我们看到一张猫的图片,图像内容就是那只特定的喵,如果我们给图像赋予彩色,就得到了现实中看到的喵;如果给那张图像赋予铅笔画属性,就得到了一只“铅笔喵”。喵~
,它是图像的固有内容,是区分不同图像的依据。第二个概念是图像域(domain),域内的图像可以认为是图像内容被赋予了某些相同的属性。举个例子,我们看到一张猫的图片,图像内容就是那只特定的喵,如果我们给图像赋予彩色,就得到了现实中看到的喵;如果给那张图像赋予铅笔画属性,就得到了一只“铅笔喵”。喵~

图像翻译是指图像内容从一个域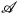 迁移到另一个域
迁移到另一个域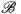 ,可以看成是图像移除一个域的属性
,可以看成是图像移除一个域的属性 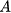 ,然后赋予另一个域的属性
,然后赋予另一个域的属性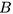 。我们用
。我们用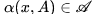 和
和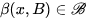 来表示域
来表示域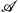 和域
和域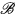 的图像,图像翻译任务即可以定义为,寻找一个合适的变换
的图像,图像翻译任务即可以定义为,寻找一个合适的变换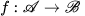 使得
使得
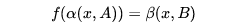
当然,还有一种图像翻译,在翻译的时候会把图像内容也换掉,下面介绍的方法也适用于这种翻译,这种翻译除了研究图像属性的变化,还可以研究图像内容的变化,在这里就不做讨论了。
常见的GAN图像翻译方法
下面简单总结几种GAN的图像翻译方法。
-
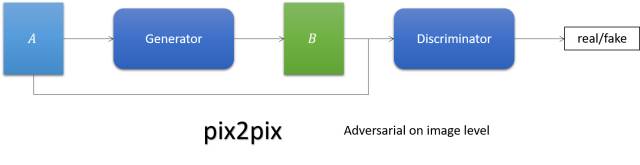
pix2pix
简单来说,它就是跟cGAN。Generator的输入不再是noise,而是图像。
-
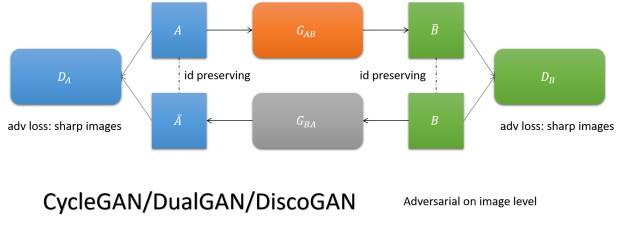
CycleGAN/DualGAN/DiscoGAN
要求图像翻译以后翻回来还是它自己,实现两个域图像的互转。
-
DTN
用一个encoder实现两个域的共性编码,通过特定域的decoder解码,实现图像翻译。

-
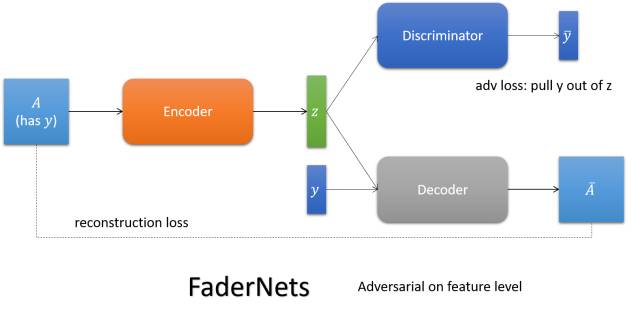
FaderNets
用encoder编码图像的内容,通过喂给它不同的属性,得到内容的不同表达。
-
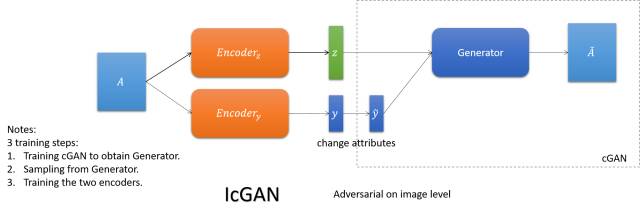
IcGAN
依靠cGAN喂给它不同属性得到不同表达的能力,学一个可逆的cGAN以实现图想到图像的翻译(传统的cGAN是编码+属性到图像的翻译)。
-
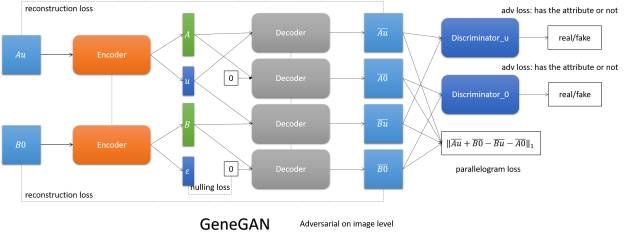
GeneGAN
将图像编码成内容和属性,通过交换两张图的属性,实现属性的互转。
-
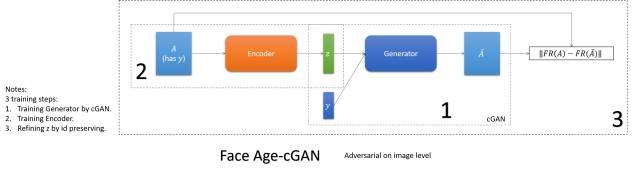
Face Age-cGAN
这篇是做同个人不同年龄的翻译。依靠cGAN喂给它不同属性(年龄)得到不同年龄的图像的能力,学cGAN的逆变换以得到图像内容的编码,再通过人脸识别系统纠正编码,实现保id。
图像翻译方法的完备性
我认为一个图像翻译方法要取得成功,需要能够保证下面两个一致性(必要性):
-
Content consistency(内容一致性)
-
Domain consistency(论域一致性)
此外,我们也似乎也可以认为,满足这两点的图像翻译方法是能work的(充分性)。
我把上述两点称为图像翻译方法的完备性,换句话说,只要一个方法具备了上述两个要求,它就应该能work。关于这个完备性的详细论述,我会在以后给出。
下面,我们来看一下上述几种方法是如何达成这两个一致性的。
内容一致性
我把它们实现内容一致性的手段列在下面的表格里了。

这里有两点需要指出。
其一,有两个方法(IcGAN和Face Age-cGAN)依靠cGAN的能力,学cGAN的逆映射来实现图像换属性,它们会有多个训练阶段,不是端到端训练的方法。而cGAN训练的好坏,以及逆映射的好坏对实验结果影响会比较大,经过几个阶段的训练,图像的内容损失会比较严重,实际中我们也可以观察到 IcGAN 的实验效果比较差。Face Age-cGAN通过引入人脸识别系统识别结果相同的约束,能够对内容的编码进行优化,可以起到一些缓解作用。
其二,DTN主要依靠TID loss来实现内容的一致性,而编码一般来说是有损的,编码相同只能在较大程度上保证内容相同。从DTN的emoji和人脸互转的实验我们也可以看出,emoji保id问题堪忧,参看下图。

论域一致性
论域一致性是指,翻译后的图像得是论域内的图像,也就是说,得有目标论域的共有属性。用GAN实现的方法,很自然的一个实现论域一致性的方法就是,通过discriminator判断图像是否属于目标论域。
上述几种图像翻译的方法,它们实现论域一致性的手段可以分为两种,参见下表。

此外,可以看到,FaderNets实现两个一致性的方法都是剥离属性和内容,而实现剥离手段则是对抗训练。编码层面的对抗训练我认为博弈双方不是势均力敌,一方太容易赢得博弈,不难预料到它的训练会比较tricky,训练有效果应该不难达成,要想得到好的结果是比较难的。目前还没有看到能够完美复现的代码。文章的效果太好,好得甚至让人怀疑。
最后的最后,放一个歌单,听说听这个歌单炼丹会更快哦。