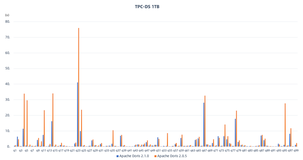
本文讲的是6倍性能差100TB容量,阿里云POLARDB咋实现?【IT168 云计算】POLARDB是阿里云数据库团队研发的基于第三代云计算架构下的商用关系型云数据库产品,实现100%向下兼容MySQL 5.6的同时,支持单库容量扩展至上百TB以及计算引擎能力及存储能力的秒级扩展能力,对比MySQL有6倍性能提升及相对于商业数据库实现大幅度降低成本。
第三代分布式共享存储架构究竟有什么优势?
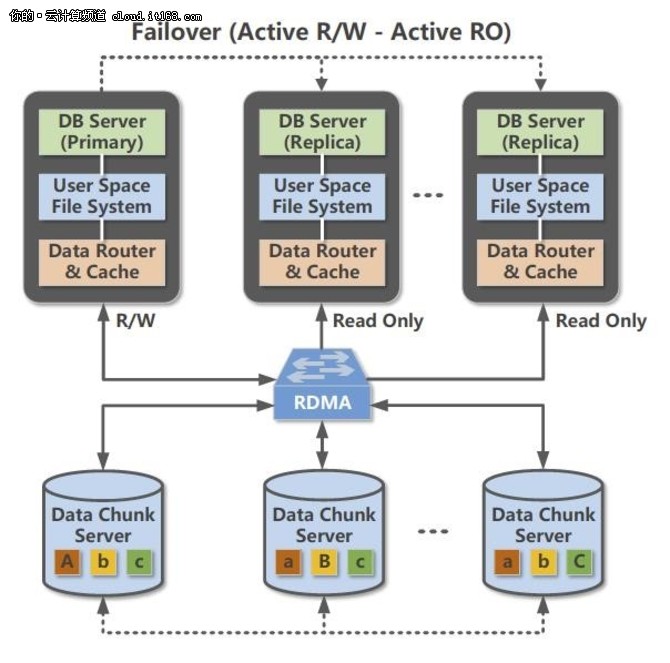
▲POLARDB的第三代分布式共享存储架构
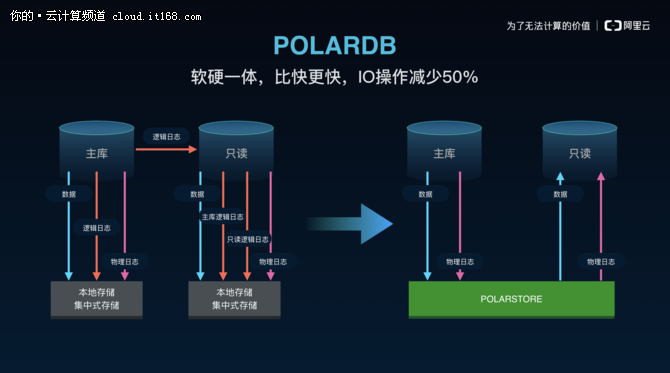
首先,受益于第三代分布式共享存储架构,使POLARDB实现了计算节点(主要做SQL解析以及存储引擎计算的服务器)与存储节点(主要做数据块存储,数据库快照的服务器)的分离,提供了即时生效的可扩展能力和运维能力。
众所周知,在传统数据库上做扩容、备份和迁移等操作,花费的时间和数据库的容量成正比,往往上TB的数据库容量加个只读副本就需要一到两天时间。POLARDB的存储容量可以实现无缝扩展,不管数据量有多大,2分钟内即可实现只读副本扩容,1分钟内即可实现全量备份,为企业的快速业务发展提供了弹性扩展能力。
其次,与传统云数据库一个实例一份数据拷贝不同,POLARDB同一个实例的所有节点(包括读写节点和只读节点)都实现访问存储节点上的同一份数据,使得POLARDB的数据备份耗时实现秒级响应。(备份时间与底层数据量无关)
最后,借助优秀的RDMA网络以及最新的块存储技术,实现服务器宕机后无需搬运数据重启进程即可服务,满足了互联网环境下企业对数据库服务器高可用的需求。
为什么POLARDB能做到6倍于MySQL的性能?
这里我们将分别以存储性能、计算性能来进行解读诠释。
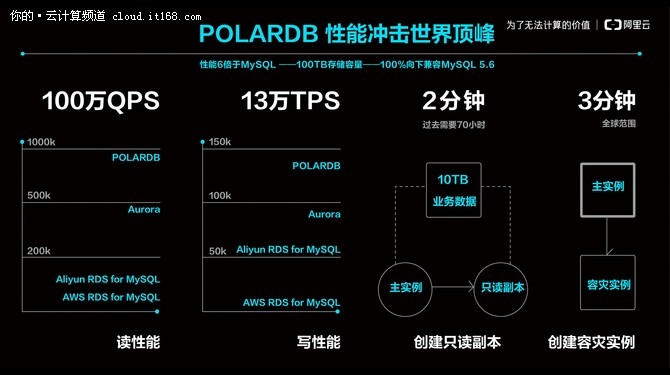
▲阿里云POLARDB性能全景
POLARDB的存储引擎性能优化
持续释放硬件红利
众所周知,关系型数据库是IO密集型的应用,IO性能的提高对数据库的性能提升至关重要。过去十年我们看到在数据库领域,SSD替换HDD的过程给数据库数据处理的吞吐能力带来了数量级的提升。
POLARDB采用了领先的硬件技术:包括使用3DXpoint存储介质的Optane存储卡、NVMe SSD和RoCE RDMA网络。同时面向新硬件架构实现软硬一体优化:从数据库、文件系统到网络通讯协议、分布式存储系统和设备驱动,POLARDB实现纵贯软件栈各层次的整个IO链条的深度优化。
为了将3DXpoint颗粒的高性能和3D NAND颗粒的低成本结合起来,POLARDB创新的在软件层实现对高速的Optane卡和大容量高吞吐的NVMe SSD进行组合,实现一个名为混合存储层。既保证数据写入的低延迟、高吞吐、高QoS,又使整体方案兼具较高的性价比。
旁路内核,榨干硬件能力
在POLARDB里,为了追求更高的性能、更低的延迟,阿里云数据库团队大胆的抛弃了Linux内核提供的各种机制,比如块设备、各种文件系统例如ext4,以及TCP/IP协议栈和socket编程接口而选择了另起炉灶。最终,POLARDB实现了一整套在用户态运行的IO和网络协议栈。
POLARDB用户态协议栈解决了内核IO协议栈慢的问题。用户程序在用户态直接通过DMA操作硬件设备,通过轮询的方式监听硬件设备完成IO事件,消除了上下文切换和中断的开销。用户程序还可以将IO处理线程和cpu进行一一映射,每个IO处理线程独占CPU,相互之间处理不同的IO请求,绑定不同的IO设备硬件队列,一个IO请求生命周期从头到尾都在一个线程一颗CPU上处理,不需要锁进行互斥。这种技术实现最大化的和高速设备进行性能交互,实现一颗CPU达每秒约20万次IO处理的能力,并且保持线性的扩展能力,也就意味着4颗CPU可以达到每秒80万次IO处理的能力,在性能和经济型上远高于内核。
网络也是类似的情况。过去传统的以太网,网卡发一个报文到另一台机器,中间通过一跳交换机,大概需要一百到两百微秒。POLARDB支持ROCE以太网,应用程序通过RDMA网络,直接将本机的内存写入另一台机器的内存地址,或者从另一台机器的内存读一块数据到本机,中间的通讯协议编解码、重传机制都由RDMA网卡来完成,不需要CPU参与,使性能获得极大提升,传输一个4k大小报文只需要6、7微秒的时间。如同内核的IO协议栈跟不上高速存储设备能力,再一次的,内核的TCP/IP协议栈跟不上高速网络设备能力,被POLARDB的用户态网络协议栈代替。
硬件DMA和物理复制实现的数据库多副本
大家都知道关系型数据库的重要特性归纳起来是“ACID”,其中A是原子性,C是约束,I是隔离性,D是持久性。
POLARDB将从两个维度出发,从根本上改进多副本复制。一个是保证数据库ACID中的D(Durable),把网络、存储硬件提供的DMA能力串起,用硬件通道高性能的把主库的日志数据持久化到三个存储节点的磁盘中;另一个是实现了高效的只读节点,在主库和只读节点之间通过物理复制同步数据,直接更新到只读节点的内存里。 如何实现?
POLARDB实现日志数据持久化到三个存储节点的磁盘中。主库通过RDMA将日志数据发送到存储节点的内存中,存储节点之间再通过RDMA互相复制,每个存储节点用SPDK将数据写入NVMe接口的存储介质里,整个过程CPU不用访问被同步的数据块(Payload),实现数据零拷贝。
同时由RDMA网卡和NVMe控制器完成数据传输和持久化,CPU仅做状态机的维护,在一致性协议的协调下,把网卡和存储卡两块硬件串起来,存储节点之间数据同步采用并发Raft(Parallel Raft)协议,和Raft协议一样,决议在leader节点上是串行生成和提交的,但并发Raft协议可以允许主从之间乱序同步,简单的说,允许follower节点在漏掉若干条日志的情况先commit并apply后面过来的日志,并异步的去补之前漏掉的日志,数据同步的性能和稳定性都显著优于Raft协议。
POLARDB在主库和只读实例之间的数据流上,放弃了基于binlog的逻辑复制,而是基于innodb的redolog实现了物理复制,从逻辑复制到物理复制对主库和从库性能带来的提升都非常明显。
在主库上,原本引擎需要和binlog做XA事务,事务要等到binlog和redolog同时写盘后才能返回,去掉binlog后,XA事务可以去掉,事务的执行路径更短,IO开销也更小。在从库上,redolog由于是物理复制,仅需比对页面的LSN就可以决定是否回放,天然可以多线程执行,数据的正确性也更有保证,此外,POLARDB的从库收到redolog后只需要更新缓存里的页面,并不需要写盘和IO操作,开销远低于传统多副本复制里的从库。
针对数据库加速的Smart Storage
POLARDB的存储节点针对数据库的IO workload进行了一些针对性的优化。
IO优先级优化:POLARDB在文件系统和存储节点两层都开了绿色通道,对redolog文件的更新进行优待处理,减少排队,提高IO的优先级。redolog也从512对齐调整为4k对齐,对SSD性能更加友好。
double write优化:POLARDB存储节点原生支持1MB的原子写,因此可以安全关闭double write,从而节省了近一倍的IO开销。
group commit优化:POLARDB里一次group commit可以产生写入几百KB的单个大IO。对于单个SSD,延迟和IO的大小是呈线性的,而POLARDB从文件系统到存储节点都进行一系列优化来保证这种类型的IO能尽快刷下去,针对redolog文件进行条带化,将一个上百KB的大IO切割为一批16KB的较小IO,分发到多个存储节点和不同的磁盘上去执行,进一步的降低关键IO路径的延迟。
POLARDB的计算引擎性能优化

使用共享存储物理复制
由于POLARDB使用共享存储和物理复制,实例的备份恢复也做到完全依赖redolog,因此去掉了binlog。使得单个事务对io的消耗减少,有效减少语句响应时间,提升吞吐量。同时避免了引擎需要与binlog做的XA事务逻辑,事务语句的执行路径更短。
锁优化
POLARDB针对高并发场景,对引擎内部锁做了大量优化,比如把latch分解成粒度更小的锁,或者把latch改成引用计数的方式从而避免锁竞争,例如Undo segment mutex, log system mutex等等。PolarDB还把部分热点的数据结构改成了Lock Free的结构,例如Server层的MDL锁。
日志提交优化
Redolog的顺序写性能对数据库性能的影响很大,为了减少Redolog切换时对性能的影响,我们后台采用类似Fallocate的方式预先分配日志文件,此外,现代的SSD硬盘很多都是4K对齐,而MySQL代码还是按照早期磁盘512字节对齐的方式刷日志的,这样会导致磁盘做很多不必要的读操作,不能发挥出SSD盘的性能,我们在这方面也做了优化。我们对日志提交时Group Commit进行优化,同时采用Double RedoLog Buffer提升并行度。
复制性能
POLARDB中物理复制的性能至关重要,我们不仅通过基于数据页维度的并行提高了性能,还对复制中的必要流程进行了优化,例如在MTR日志中增加了一个长度字段,从而减少了日志Parse阶段的CPU开销,这个简单的优化就能减少60%的日志Parse时间。我们还通过复用Dummy Index的内存数据结构,减少了其在Malloc/Free上的开销,进一步提高复制性能。
读节点性能
POLARDB的Replica节点,日志目前是一批一批应用的,因此当新的一批日志被应用之前,Replica上的读请求不需要重复创建新的ReadView,可以使用上次缓存下来的。这个优化也能提高Replica上的读性能。
为什么POLARDB能做到远低于商业数据库的成本
存储资源池化
POLARDB采用了一种计算和存储分离的架构,DB运行在计算节点,计算节点组成了一个计算资源池,数据都放在存储节点上,存储节点组成了一个存储资源池。如果CPU和内存不够了,就扩充计算资源池,如果容量或者IOPS不够了,就扩充存储资源池,两个池子都是按需扩容。而且存储节点和计算节点可以分别向两个方向优化,存储节点会选择低配的CPU和内存,提高存储密度,而计算节点可以选择小容量、低配的SSD作为操作系统和日志盘,上多路服务器增加CPU的核数。
而传统的数据库部署模型则是一种烟囱模型,一台主机既跑数据库又存数据,这带来两个问题。一个是机型难以选择,CPU和磁盘的配比主要取决于实际业务的需求,很难提前找到最优比例。第二是磁盘碎片问题,一个生产集群里,总有部分机器磁盘使用率是很低的,有的还不到10%,但出于业务稳定性要求,会要求独占主机的CPU,这些机器上的SSD其实是被浪费的。通过存储资源池化,这两个问题都能得到解决,SSD的利用率得到提高,成本自然也降低下来。
透明压缩
POLARDB的存储节点除了对ibd文件提供1MB的原子写,消除double write的开销,还支持对ibd文件的数据块进行透明压缩,压缩率可以达到2.4倍,进一步降低了存储成本。
而传统数据库在DB内进行压缩的方案相比,存储节点实现透明压缩不消耗计算节点的CPU,不影响DB的性能,利用QAT卡进行加速,以及在IO路径上用FPGA进行加速。POLARDB的存储节点还支持快照去重(dedup)功能,数据库的相邻快照之间,如果页面没有发生修改,会链接到同一份只读页面上,物理上只会存储一份。
存储成本的只读实例
传统数据库做只读实例,实施一写多读方案,是通过搭建只读副本的方案,先拷贝一个最近的全量备份恢复一个临时实例,再让这个临时实例连接主库或者其他binlog源同步增量数据,增量追上后,把这个临时实例加到线上升级为一个只读副本。这种方法一个是耗时,搭建一个只读实例需要的时间与数据量成正比;另一方面也很昂贵,需要增加一份存储成本,比如用户购买一个主实例加上五个只读实例,需要付7~8份存储的钱(7份还是8份取决于主实例是两副本还是三副本)。
而在PolarDB架构中,这两个问题都得到解决,一方面新增只读实例不需要拷贝数据,不管数据量有多大都可以在2分钟内创建出来;另一方面,主实例和只读实例共享同一份存储资源,通过这种架构去增加只读副本,可以做到零新增存储成本,用户只需要支付只读实例消耗的CPU和内存的费用。

POLARDB是未来云数据库的雏形(All in one),一个数据库即可满足现时多类数据库混合使用效果。阿里云发挥自身自研能力优势,以POLARDB为产品契机,实现数据库OLTP与OLAP的一体化设计,为企业的数字化升级所需的IT设施架构实现革命性进化。
原文发布时间为:2017-09-21
本文作者:朱立娜
本文来自云栖社区合作伙伴IT168,了解相关信息可以关注IT168
原文标题:6倍性能差100TB容量,阿里云POLARDB咋实现?