OceanBase是一台内存数据库,兼容MySQL协议以及SQL协议,拥有跟内存数据库一样的属性:所有的数据都需要先写入到内存里面,但是并不会立刻落盘写入到存储里面,需要等一次合并操作,将内存里面所有的改动落盘到存储里面。所以发生这种合并操作的时候,伴随着资源的使用,也会出现问题。我们来看其中一种由于合并操作导致数据库杀死事务的情况如何排查。
机器配置:
2c8g
应用端报错信息:
系统未知错误,请联系管理员: transaction error,need to rollback。
第一次遇到这种问题也是比较懵的,因为平常测试库的压力不大,而且合并时间都在凌晨,一般不会出现这种问题。所以排查也是冲头到尾一步一步梳理的。
排错过程:
首先确认一下所有的observe是否都正常。
可以直接使用observe机器所在的IP直接连接,或者是查看端口是否通等等的。确认无误。
然后查看相关监控信息如下:
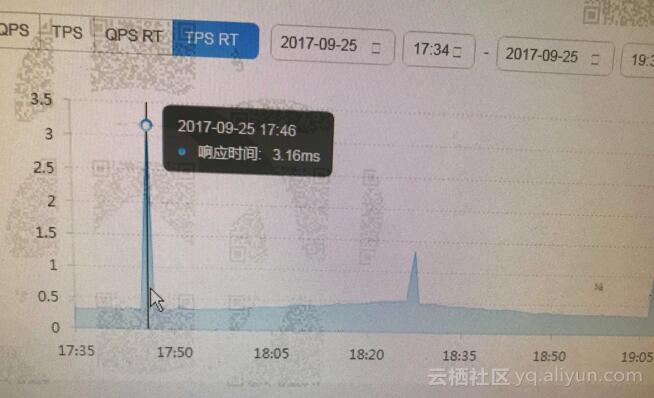
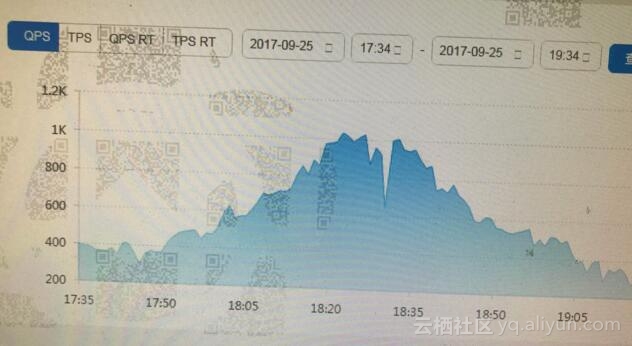
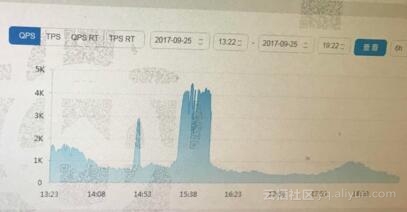
监控信息里面能反应出一些事情来,确实那个时间段相对的系统负载要比平时高。
然后,看一下是否由于压力的问题,导致了系统发生了合并操作。
OceanBase (root@oceanbase)> show tables like '%rootservice%';
+-------------------------------------+
| Tables_in_oceanbase (%rootservice%) |
+-------------------------------------+
| __all_rootservice_event_history |
| __all_rootservice_job |
+-------------------------------------+
2 rows in set (0.02 sec)select * from __all_rootservice_event_history where gmt_create between '2017-09-25 16:00:00' and '2017-09-25 17:00:00' order by gmt_create;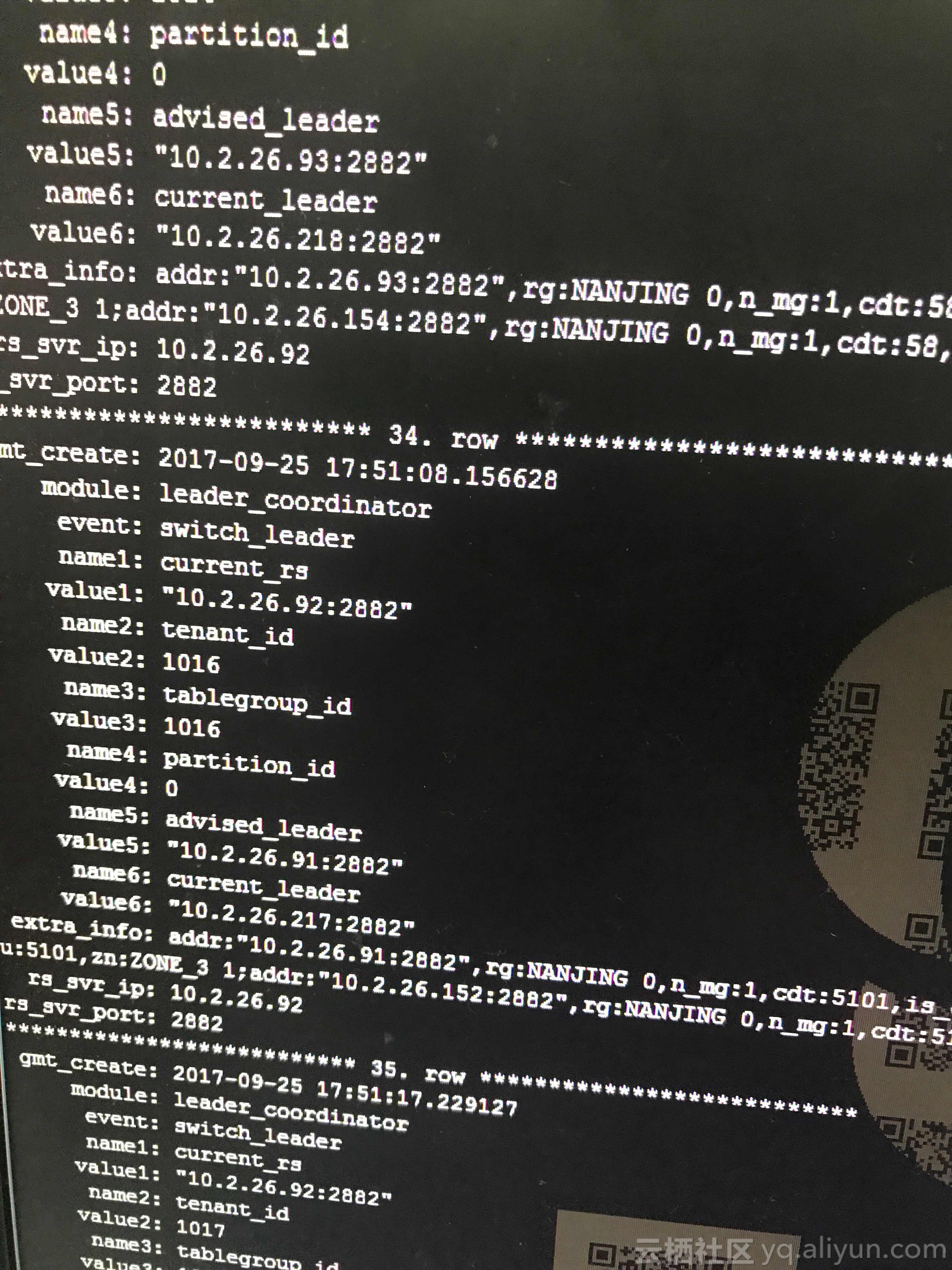
发现在故障时间点确实是存在合并操作的。通过之前的操作可以看到75是这次合并操作的序号
select count(*)
from __all_rootservice_event_history
where gmt_create between '2017-09-25 16:00:00' and '2017-09-25 17:00:00' and
value1 = 75
order by gmt_create;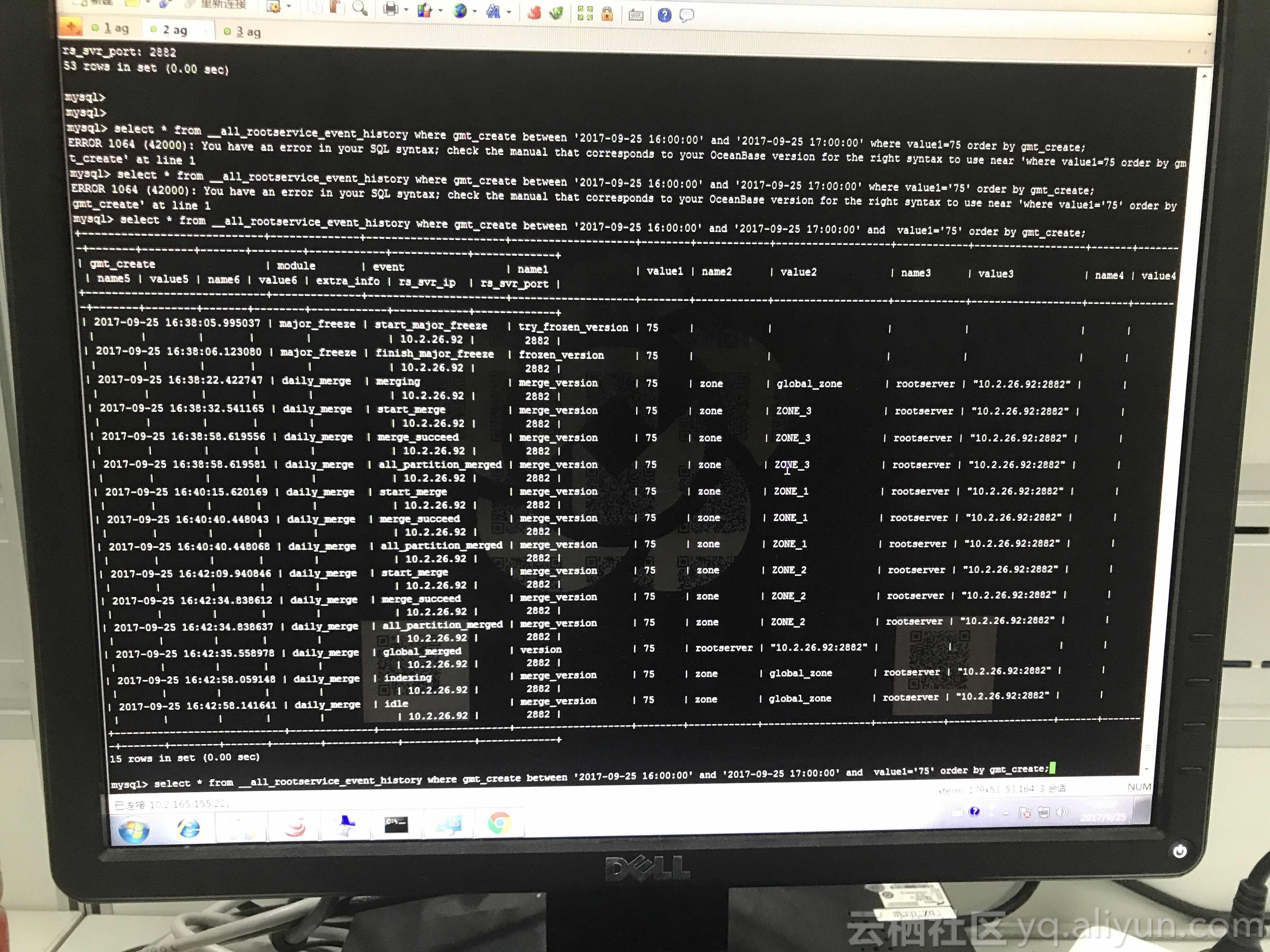
show parameters like '%turn%';这是一次非计划的合并,说明性能测试写操作太猛,租户的memstore增长太快,达到一定阈值后就自动触发了合并操作。