背景
如果你是做互联网金融的,那么一定听说过评分卡。评分卡是信用风险评估领域常用的建模方法,评分卡并不简单对应于某一种机器学习算法,而是一种通用的建模框架,将原始数据通过分箱后进行特征工程变换,继而应用于线性模型进行建模的一种方法。
评分卡建模理论常被用于各种信用评估领域,比如信用卡风险评估、贷款发放等业务。另外,在其它领域评分卡常被用来作为分数评估,比如常见的客服质量打分、芝麻信用分打分等等。在本文中,我们将通过一个案例为大家讲解如何通过PAI平台的金融板块组件,搭建出一套评分卡建模方案。
本实验案例可在机器学习PAI平台使用,包含整个实验流程和数据:
数据集介绍
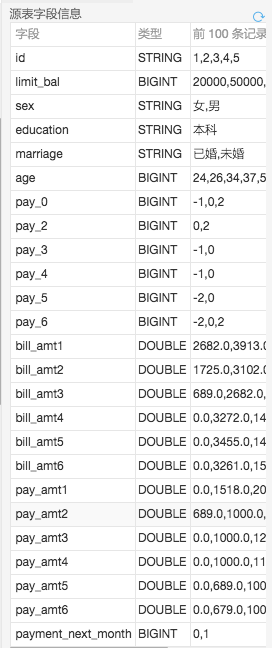
这是一份国外某机构开源的数据集,数据的内容包括每个用户的一些性别、教育、婚姻、年龄等属性,同时也包含用户过去一段时间的信用卡消费情况和账单情况。payment_next_month是目标队列,表示用户是否偿还信用卡账单,1表示偿还,0表示没有偿还。
数据供30000条。
数据集下载地址:https://www.kaggle.com/uciml/default-of-credit-card-clients-dataset
实验流程
先来看下实验图:
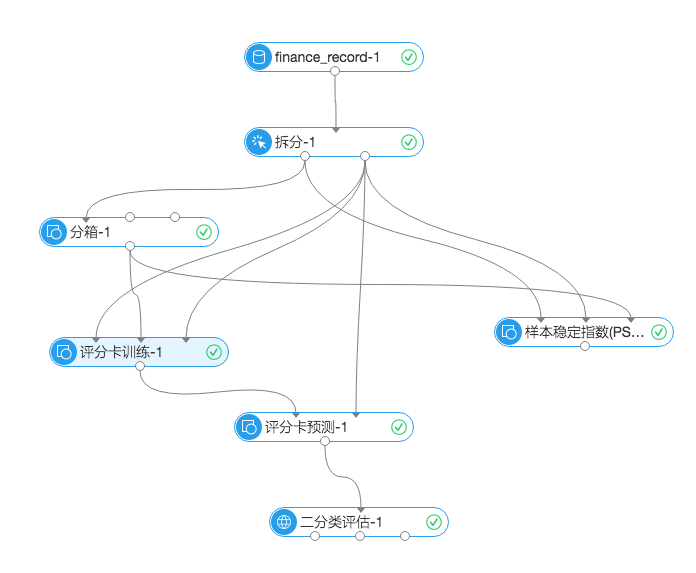
现在对一些关键节点进行介绍:
(1)拆分
将输入数据集分为两部分,一部分用来训练模型,另一部分用来预测评估。
(2)分箱
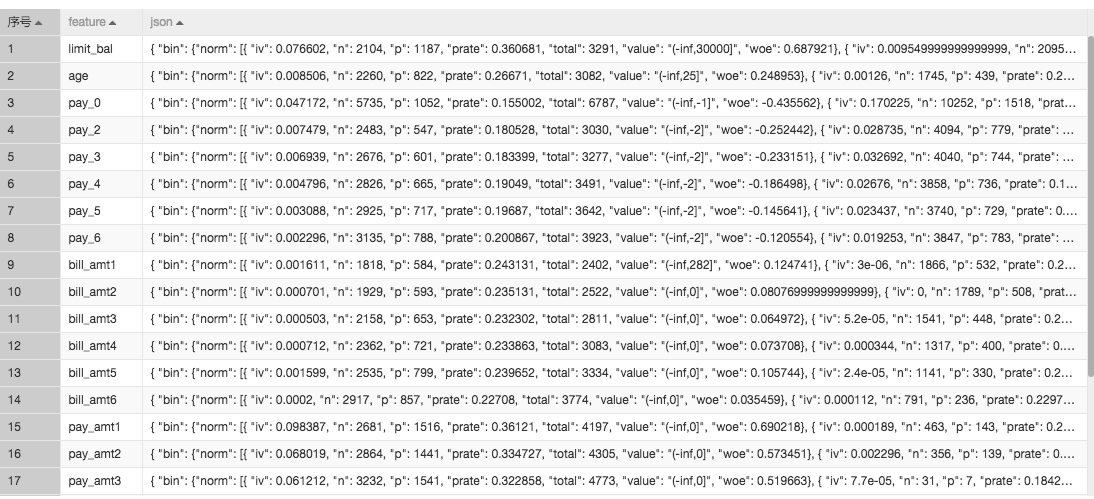
分箱组件类似于onehot编码,可以将数据按照分布映射成更高维度的特征。我们以age这个字段为例,分箱组件可以按照数据在不同区间的分布进行分享操作,分箱结果如图:
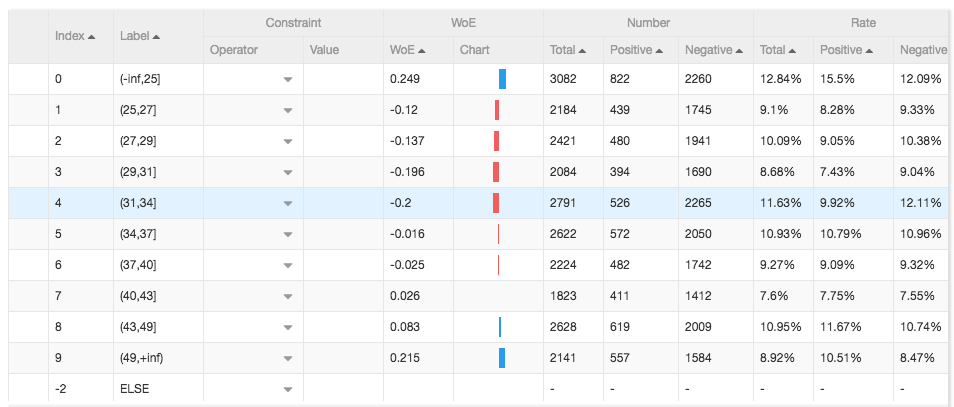
最终分箱组件的输出如图,每个字段都被分箱到多个区间上:
(3)样本稳定指数PSI
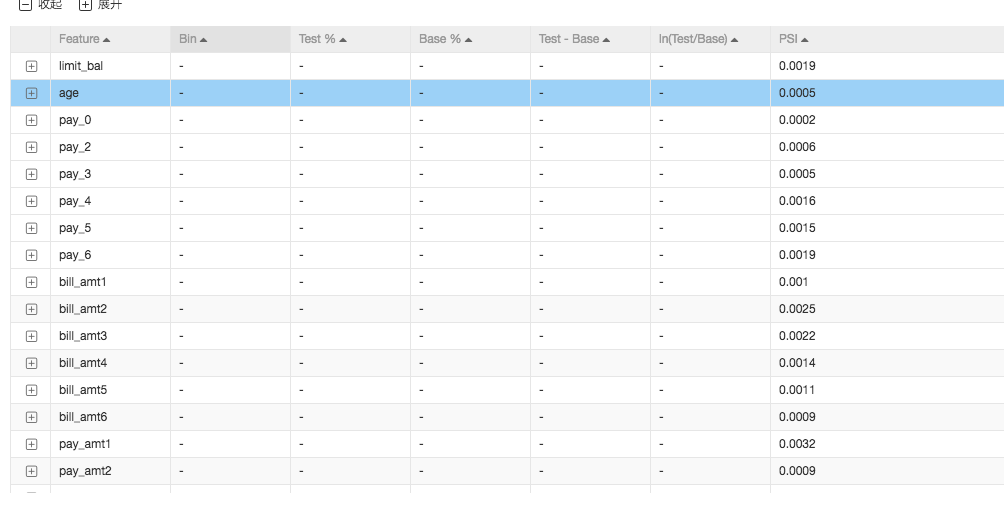
样本稳定指数是衡量样本变化所产生的偏移量的一种重要指标,通常用来衡量样本的稳定程度,比如样本在两个月份之间的变化是否稳定。通常变量的PSI值在0.1以下表示变化不太显著,在0.1到0.25之间表示有比较显著的变化,大于0.25表示变量变化比较剧烈,需要特殊关注。
本案例中,可以综合比较拆分前后以及分箱结果的样本稳定程度,返回每个特征的PSI数值:
(4)评分卡训练
评分卡训练的结果图如下: 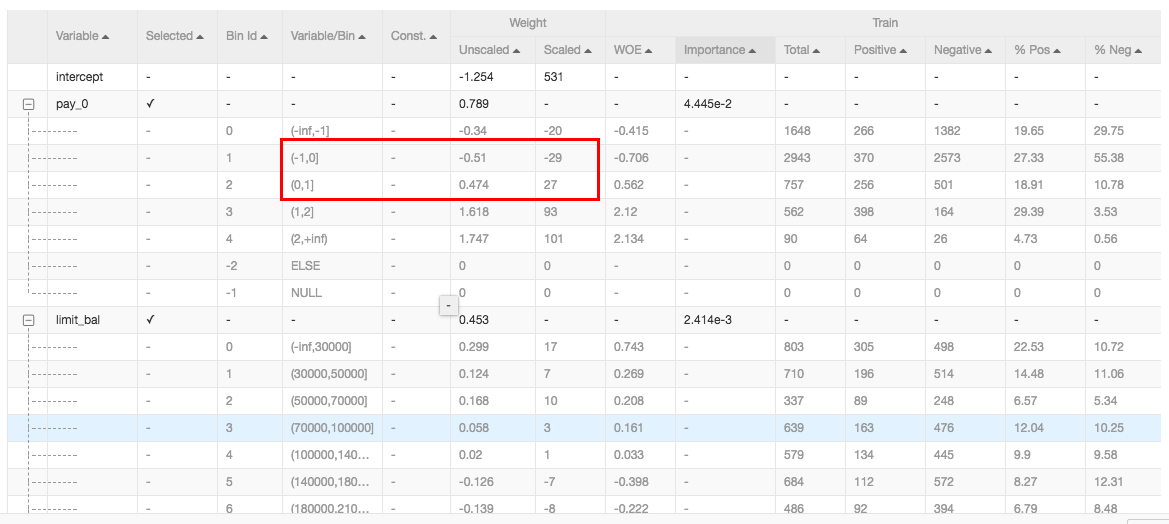
评分卡的精髓是将复杂的比较难理解的一些模型权重用符合业务标准的分数表示。
- intercepy表示的是截距
- Unscaled是原始的权重值
- Scaled是分数更改指标,比如对于pay_0这个特征,如果特征落在(-1,0]之间分数就减29,如果特征落在(0,1]之间分数就加上27.
- importance表示每个特征对于结果的影响大小,数值越大表示影响越大
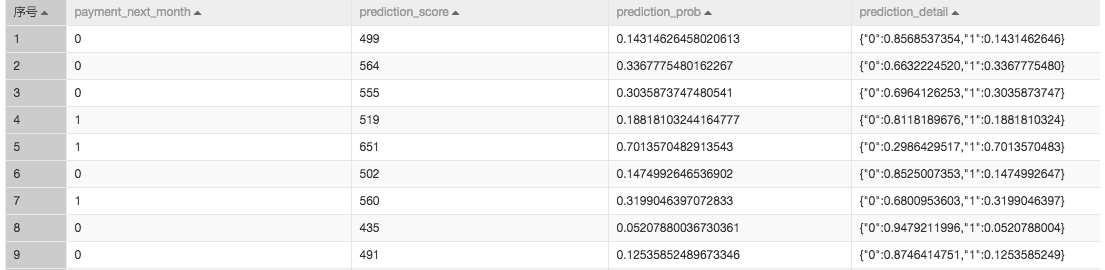
(5)评分卡预测
展示每个预测结果的最终评分,在本案例中表示的是每个用户的信用评分。
结论
基于用户的信用卡消费记录,最终通过评分卡模型的训练,我们在评分卡预测中可以拿到每个用户的最终信用评分,这个评分可以应用到其它的各种贷款或者金融相关的征信领域中去。
体验产品:阿里云数加机器学习平台
作者微信公众号(与作者讨论): 
