热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
[设计模式 Go实现] 结构型~享元模式
[设计模式 Go实现] 结构型~外观模式
[设计模式 Go实现] 结构型~组合模式
[设计模式 Go实现] 结构型~装饰模式
[设计模式 Go实现] 结构型~适配器模式
[设计模式 Go实现] 行为型~解释器模式
[设计模式 Go实现] 行为型~迭代器模式
[设计模式 Go实现] 行为型~备忘录模式
混入Mixins:如何使用Mixins复用Vue组件逻辑
[设计模式 Go实现] 行为型~中介者模式
[设计模式 Go实现] 行为型~观察者模式
[设计模式 Go实现] 行为型~状态模式
分布式缓存Redis(高级)
[设计模式 Go实现] 行为型~模板方法模式
[设计模式 Go实现] 行为型~策略模式
[设计模式 Go实现] 行为型~职责链模式
Java从入门到精通:1.3.1实践编程巩固基础知识
Java从入门到精通:1.2.1选择一本合适的入门书籍
Java从入门到精通:1.1.2深入理解Java的面向对象编程概念
[设计模式 Go实现] 行为型~访问者模式
[设计模式 Go实现] 创建型~ 原型模式
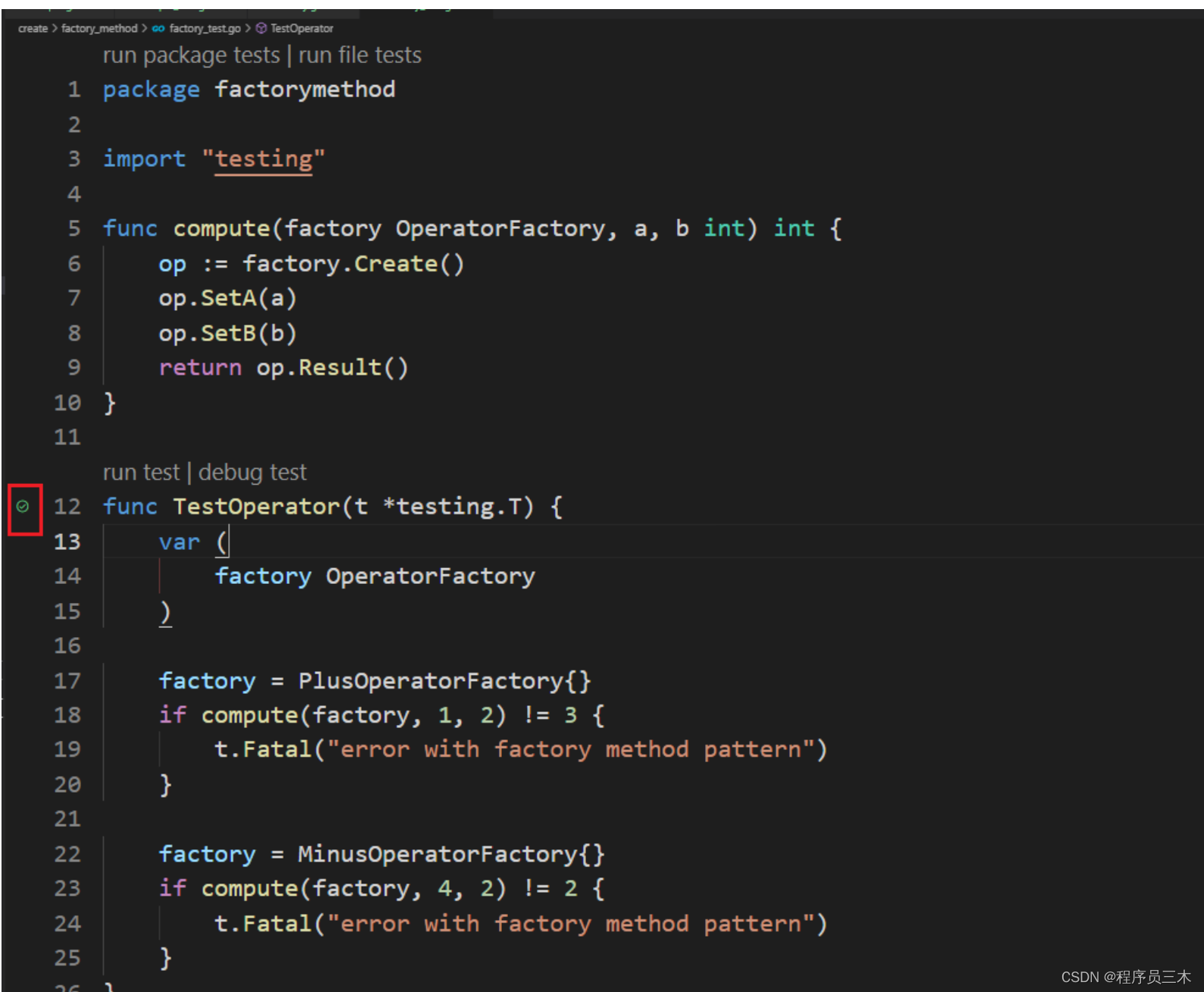
[设计模式 Go实现] 创建型~工厂方法模式
[设计模式 Go实现] 创建型~建造者模式
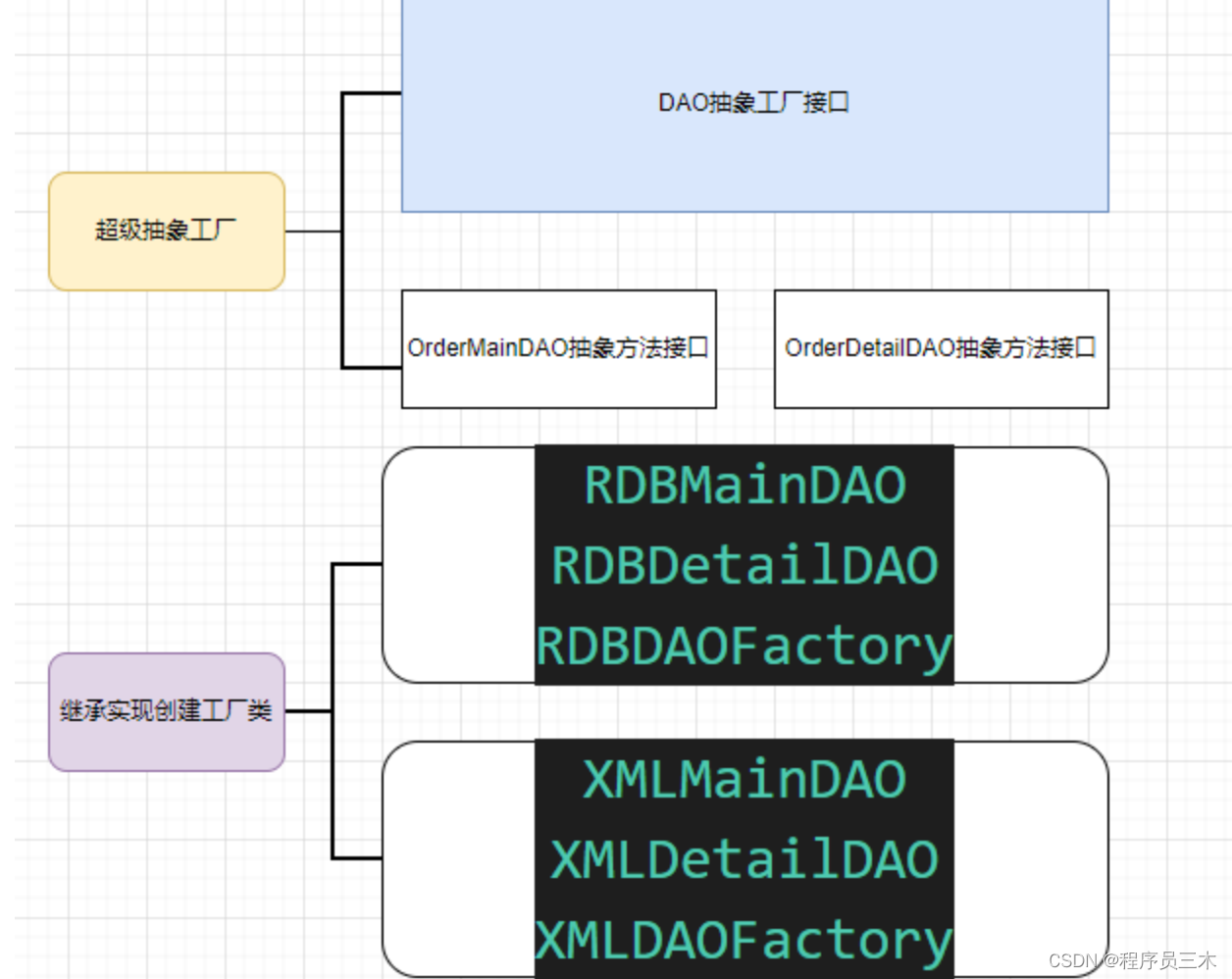
[设计模式 Go实现] 创建型~抽象工厂模式
组合API:掌握Vue的组合式API(Composition API)
[设计模式 Go实现] 创建型~单例模式
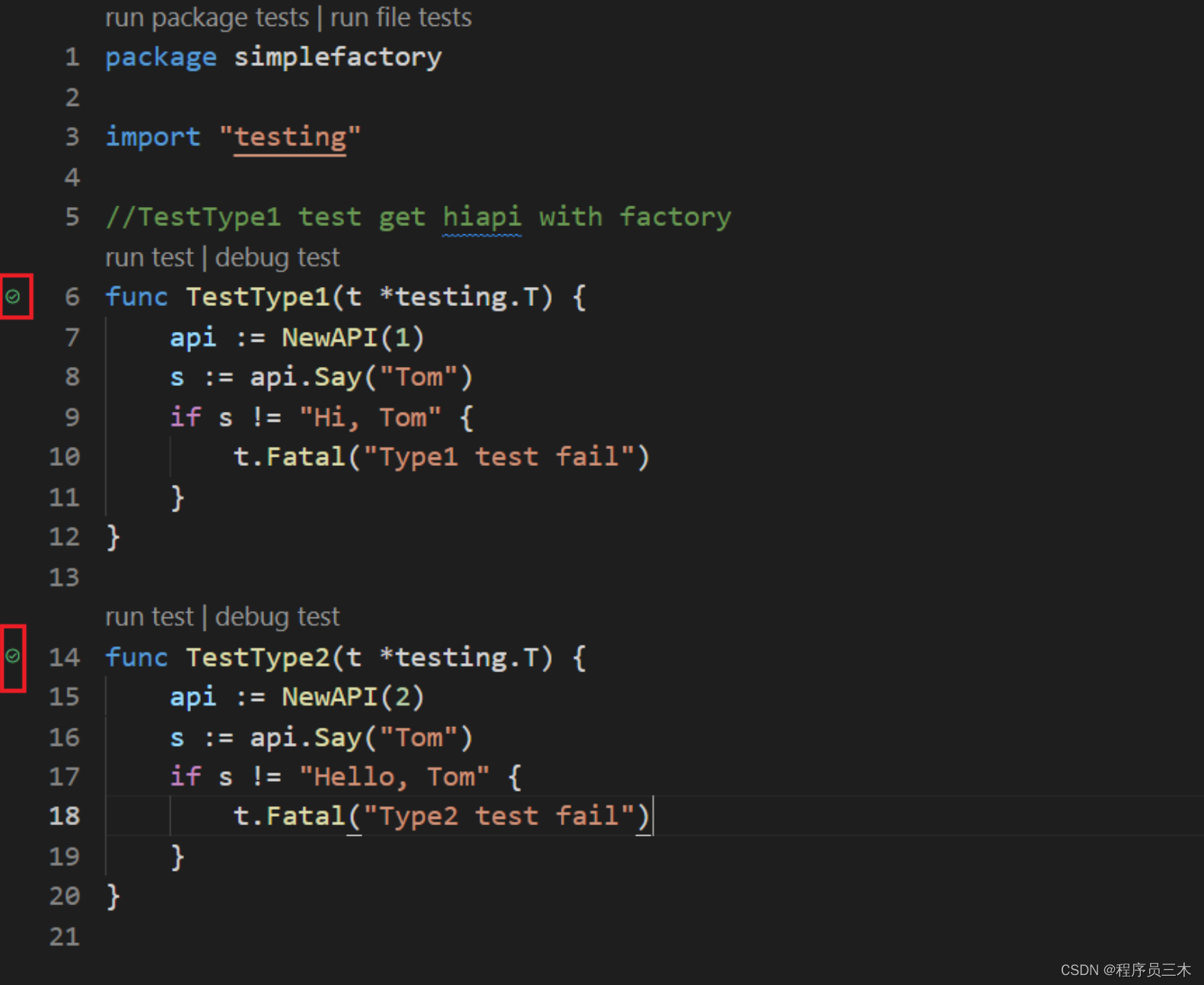
[设计模式 Go实现] 创建型~简单工厂模式
[leetcode ~go]三数之和 M
[leetcode] 四数之和 M
java实现chatGPT SDK
Go语言TCP Socket编程(下)
python代码加密以及注意事项分享
Java从入门到精通:1.1.1了解Java基础知识:学习Java的基本语法
变革来袭!多Agent框架MuAgent带你解锁代码开发新姿势
Java NIO和IO之间的区别
Go语言TCP Socket编程(上)
Kubernetes(K8s)与虚拟GPU(vGPU)协同:实现GPU资源的高效管理与利用
Python从入门到精通:3.3.2 深入学习Python库和框架:Web开发框架的探索与实践
Python从入门到精通的文章3.3.1 深入学习Python库和框架:数据处理与可视化的利器
Teleport传送:使用Vue的Teleport进行跨DOM结构渲染
服务器部署访问出错的原因和解决办法
mysql索引失效的原因以及解决办法
Python GUI编程:从入门到精通3.2 GUI编程:学习使用Tkinter、PyQt或wxPython等库创建图形用户界面。
Python从入门到精通:3.1.2多线程与多进程编程
多模态大模型有了统一分割框架,华科PSALM多任务登顶,模型代码全开源
CVPR 2024:分割一切模型SAM泛化能力差?域适应策略给解决了