1 CDP简介
数据同步节点任务是阿里云大数据平台对外提供的稳定高效、弹性伸缩的数据同步云服务。用户利用数据同步节点可以轻松地实现DRDS到ADS的数据同步。使用CDP将DRDS数据同步至ADS前需要在目标端创建相应的表结构,同步数据的具体操作如下:
2 配置数据源
2.1 增加DRDS数据源
1.登录Base管控台,单击顶部菜单栏中的项目管理,并选择相应的项目。
2. 进入数据源配置,单击新增数据源。
3. 在新建数据源弹出框中,选择数据源类型为 DRDS。
4. 配置 DRDS 数据源的各个信息项。
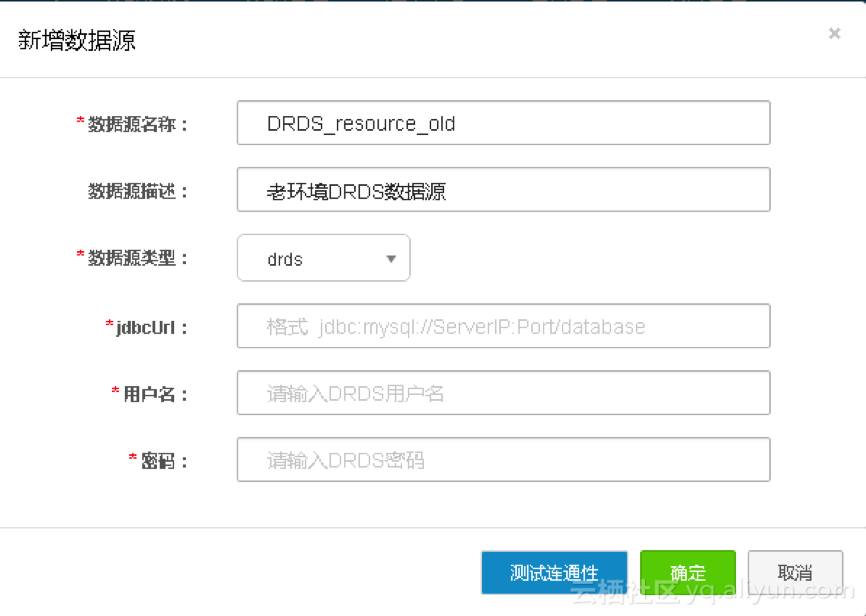
配置项说明:
l 数据源名称:由英文字母、数字、下划线组成且需以字符或下划线开头,长度不超过60个字符。
l 数据源描述:对数据源进行简单描述,不得超过80个字符。
l 数据源类型:当前选择的数据源类型DRDS。
l jdbcUrl:JDBC连接信息,格式为:jdbc://mysql://serverIP:Port/database。
l 用户名/密码:对应的用户名和密码。
5. 单击测试连通性。
6. 测试连通性通过后,单击确定。
2.2 增加ADS数据源
1.登录Base管控台,单击顶部菜单栏中的项目管理,并选择相应的项目。
2. 进入数据源配置,单击新增数据源。
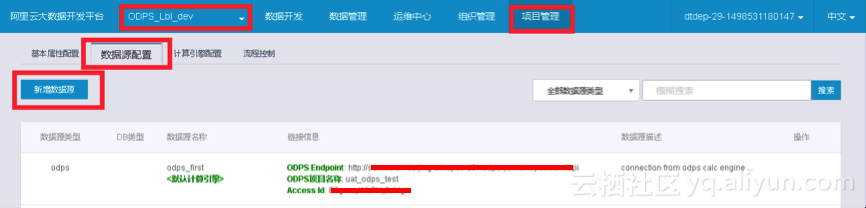
3. 在新建数据源弹出框中,选择数据源类型为 ADS。ADS数据源提供了其他数据源向 AnalyticDB 写入的功能,暂不能读取数据。
4. 配置 ADS 数据源的各个信息项。
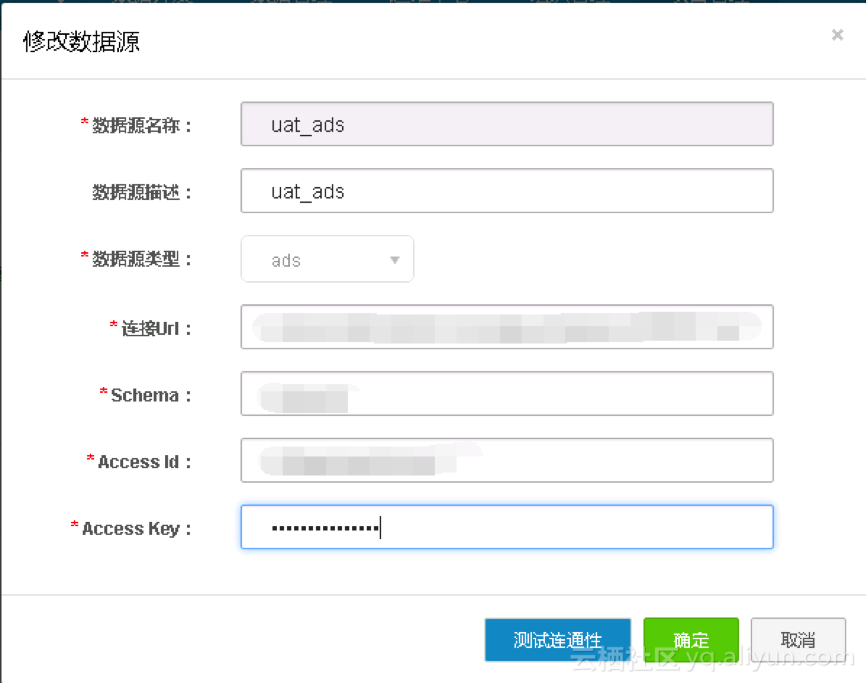
配置项说明:
l 数据源名称:由英文字母、数字、下划线组成且需以字符或下划线开头,长度不超过60个字符。
l 数据源描述:对数据源进行简单描述,不得超过80个字符。
l 数据源类型:当前选择的数据源类型ADS。
l 连接Url:ADS连接信息,格式为:serverIP:Port。
l Schema:相应的 ADS Schema 信息。
l AccessID/AceessKey:访问密钥 AccessKey(AK) 相当于登录密码。
5. 单击测试连通性。
6. 测试连通性通过后,单击确定。
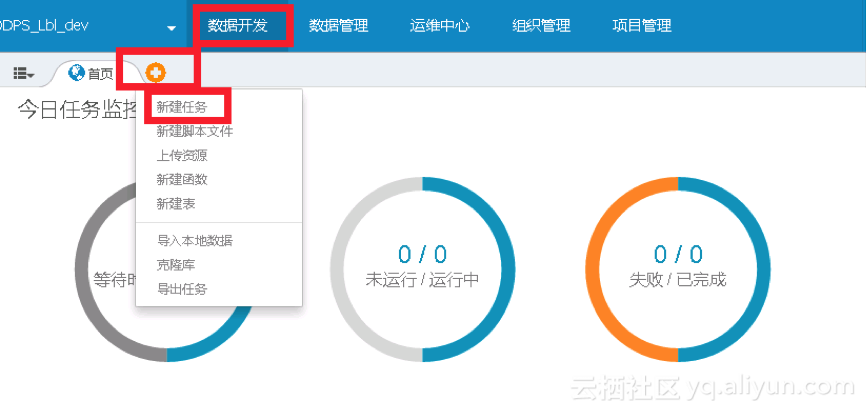
3 创建同步任务
本节将新建一个同步节点drds2ads并进行配置,以把drds的t_app表中的数据写入到新环境ads的数据库中。具体操作如下:
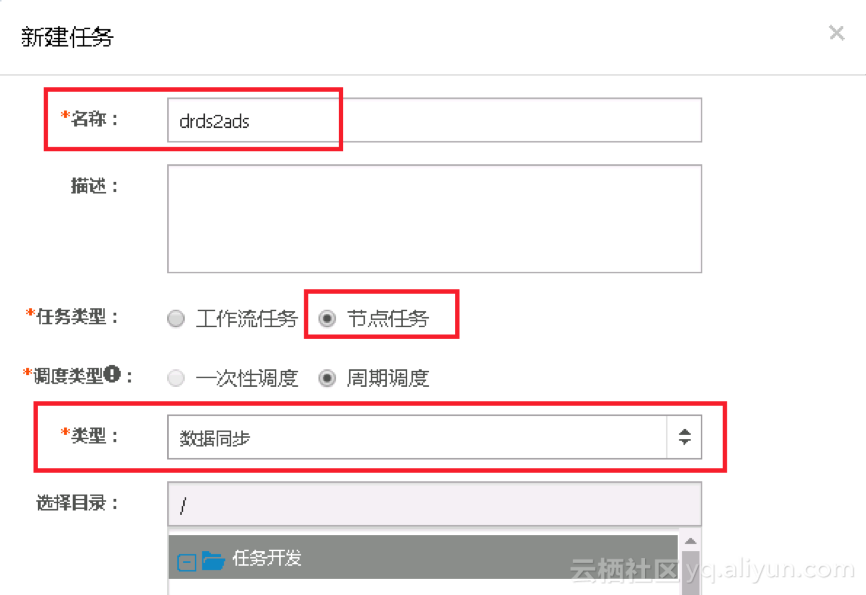
1. 新建同步节点drds2ads,如下图所示:
2. 选择数据来源和目标
在数据同步任务配置过程中,首先需选择数据源和目标(新增数据源请联系项目管理员),并支持模糊匹配查找数据源和目标以及表名。当选择了源头和目标,其选项框末尾将显示对应数据源或目标类型。

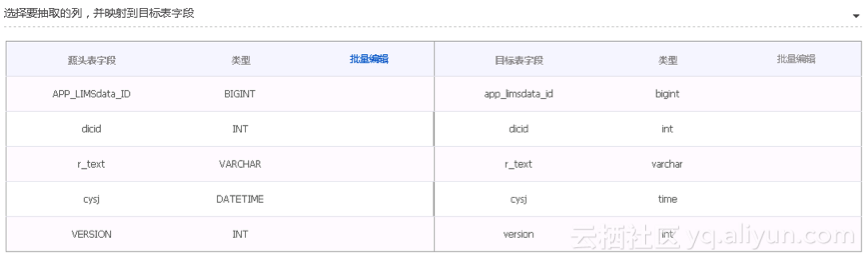
3. 字段配置
需对字段映射关系进行配置,左侧“源头表字段”和右侧“目标表字段”为一一对应的关系。可批量编辑源表或宿表字段,通过此方式添加的表字段类型默认为空。
4. 数据抽取和加载控制
数据抽取控制即数据抽取的过滤条件,而数据加载控制即数据写入时的规则。不同场景的数据同步任务配置界面不同。DRDS到ADS的数据同步任务类型的配置界面如下所示:

l 抽取控制,可参考相应的SQL语法填写where过滤语句(不需要填写where关键字),该过滤条件将作为增量同步的条件。
说明:
where条件即针对源头数据筛选条件,根据指定的column、table、where条件拼接SQL进行数据抽取。利用where条件可进行全量同步和增量同步,具体说明如下:
• 全量同步
第一次做数据导入时通常为全量导入,可不用设置where条件;如只是在测试时,避免数据量过大,可将where条件指定为limit10。
• 增量同步
增量导入在实际业务场景中,往往会选择当天的数据进行同步,通常需要编写where条件语句,请先确认表中描述增量字段(时间戳)为哪一个。如tableA描述增量的字段为creat_time,那么在where条件中编写creat_time>${yesterday},在参数配置中为其参数赋值即可。
l 导入模式,支持批量导入(Load Data)和实时插入(Insert Ignore)两种模式。
l 清理规则:
▬写入前清理已有数据:导数据之前,清空表或者分区的所有数据,相当于 insert overwrite;
▬写入前保留已有数据:导数据前不清理任何数据,每次运行数据都是追加的,相当于insert into。
5. 流量与出错控制
流量与出错控制用来配置作业速率上限和脏数据检查规则,如下图所示:

l 作业速率上限:是指配置的当前数据同步作业可能达到的最高速率,其最终实际速率受网络环境、数据库配置等的影响,支持最大为10MB/s。
以下为脏数据检查规则,可配置一个或两个,两个规则之间的关系:
l 当出错记录数超过:当脏数据数量(即错误记录数)超过所配置的个数时,该数据同步任务结束。
l 错误百分比达到:当脏数据数量(即错误记录数)超过所配置的百分比时,该数据同步任务结束。
4 设置周期和依赖
大数据开发套件提供了强大的调度能力,支持按照时间、依赖关系的任务触发机制,支持每日千万级别的任务按照 DAG 关系准确、准时运行。支持分钟、小时、天、周和月多种调度周期配置。具体操作步骤如下:
1. 配置同步任务的调度属性
进入 数据开发 > 任务开发 页面,双击打开需要配置的同步任务(drds2drds),单击右侧的 调度配置,即可为任务配置 调度属性,如下图所示:
配置参数说明:
l 调度状态:勾选后即为暂停状态。
l 生效日期:任务的有效日期,根据自身需求进行设置。
l 调度周期:任务的运行周期(月/周/天/小时/分钟),比如以周为调度周期进行调度。
l 具体时间:任务运行的具体时间,比如将任务配置为在每周二的凌晨2点开始运行。
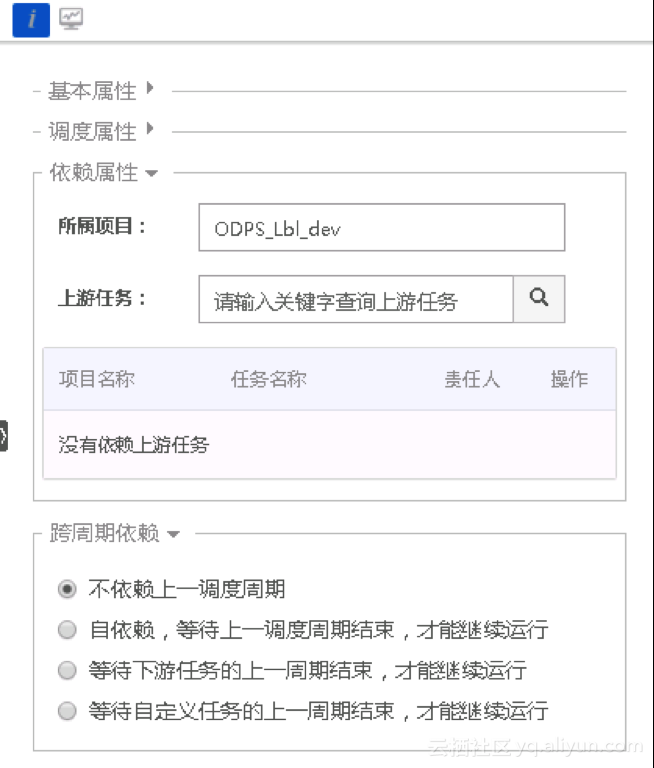
2. 配置同步任务的依赖属性
配置完同步任务的调度属性后,展开依赖属性继续配置,如下图所示:
依赖属性中可以配置任务的上游依赖,表示即使当前任务的实例已经到定时时间,也必须等待上游任务的实例运行完毕才会触发运行。
如果没有配置上游任务,则当前任务默认由项目本身触发运行,故在调度系统中,该任务的上游默认为 project_start 任务。每一个项目中默认会创建一个 project_start 任务作为根任务。
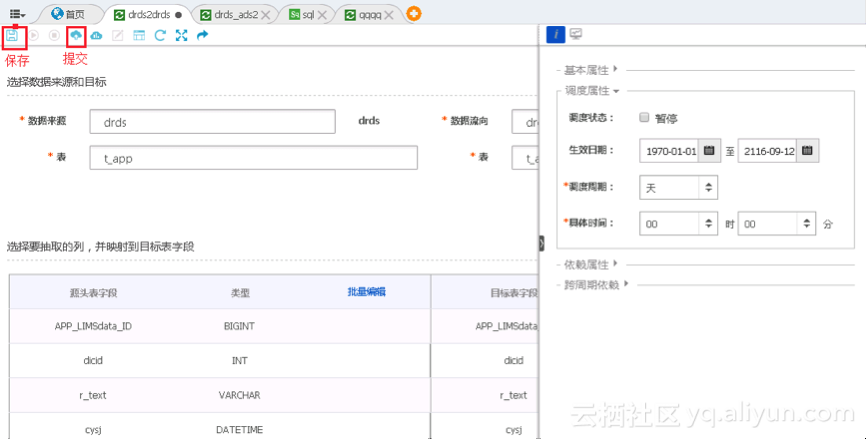
3. 提交同步任务
保存同步任务drds2drds,单击提交,将其提交到调度系统中,如下图所示:
任务只有提交到调度系统中,才会从第二天开始自动按照调度属性配置的周期在各时间点生成实例,然后定时运行。
注意: 如果是 23:30 以后提交的任务,则调度系统从第三天开始才会自动周期生成实例并定时运行。
5 运维及日志排错
在之前的操作中,假如您配置了每周二凌晨 2 点执行同步任务,将任务提交后需要到第二天才能看到调度系统自动执行的结果,那么如何确认实例运行的定时时间和相互依赖关系符合预期呢?大数据开发套件提供了测试运行和周期运行等触发方式,详情如下:
l 测试运行:手动触发方式。如果您仅需确认单个任务的定时情况和运行,建议使用测试运行。
l 周期运行:系统自动触发方式。提交成功的任务,调度系统在第二天0点起会自动生成当天不同时间点的运行实例,并在定时时间达到时检查各实例的上游实例是否运行成功,如果定时时间已到并且上游实例全部运行成功,则当前实例会自动触发运行,无需人工干预。
注意:
手动触发和自动调度的调度系统根据周期生成实例的规则一致:
l 无论周期选择天/小时/分钟/月/周,任务在每一个日期都会有对应实例生成。
l 仅在指定日期的对应实例会定时运行并生成运行日志。
l 非指定日期的对应实例不会实际运行,而是在满足运行条件时将状态直接转换为成功,因此不会有运行日志生成。
本节将为您说明如何实现以上两种触发方式,具体操作见下文。
5.1 测试运行
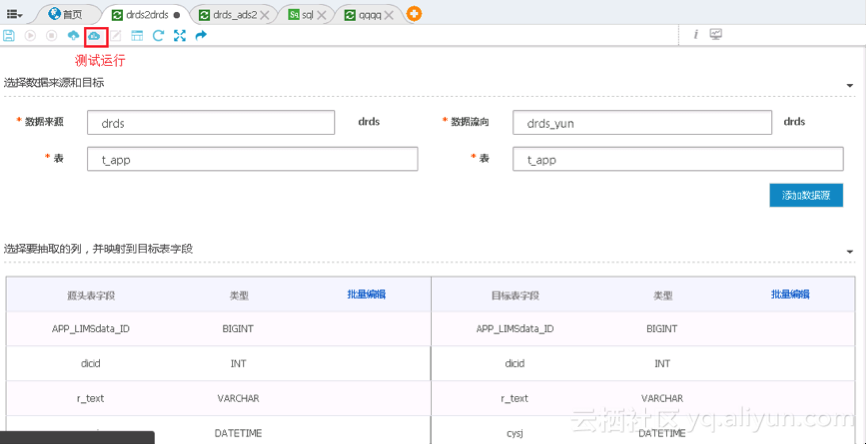
1. 单击工作流页面中的测试运行按钮,如下图所示:
2. 根据跳转页面的提示,单击确认和运行,如下图所示::


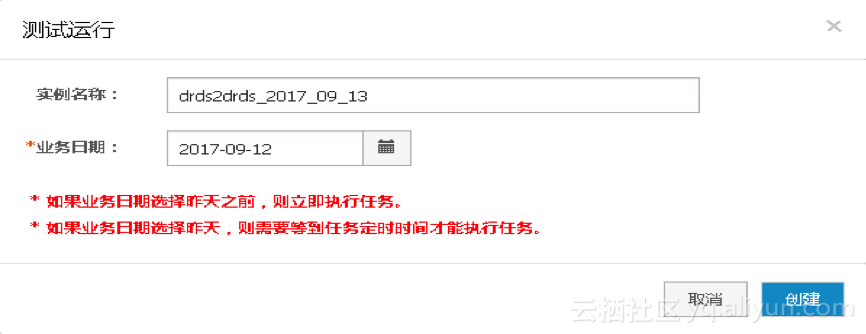
3.单击前往运维中心查看任务运行状态,如下图所示:
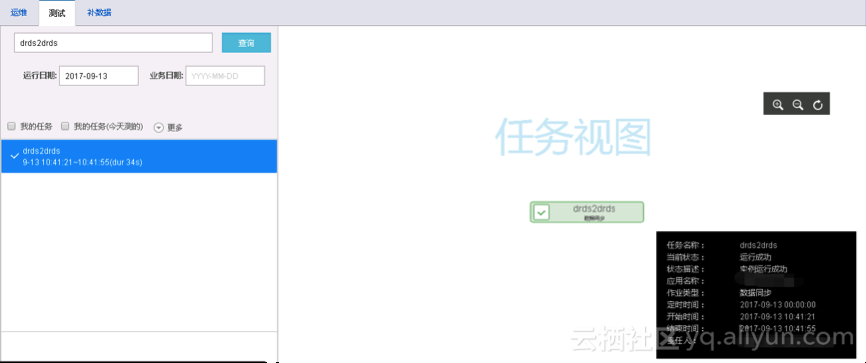
4. 查看测试实例的信息及运行日志
进入 测试 页面,右击任务实例名称,可以查看定时时间/配置属性/代码等信息,也可以查看运行日志,如下图所示:
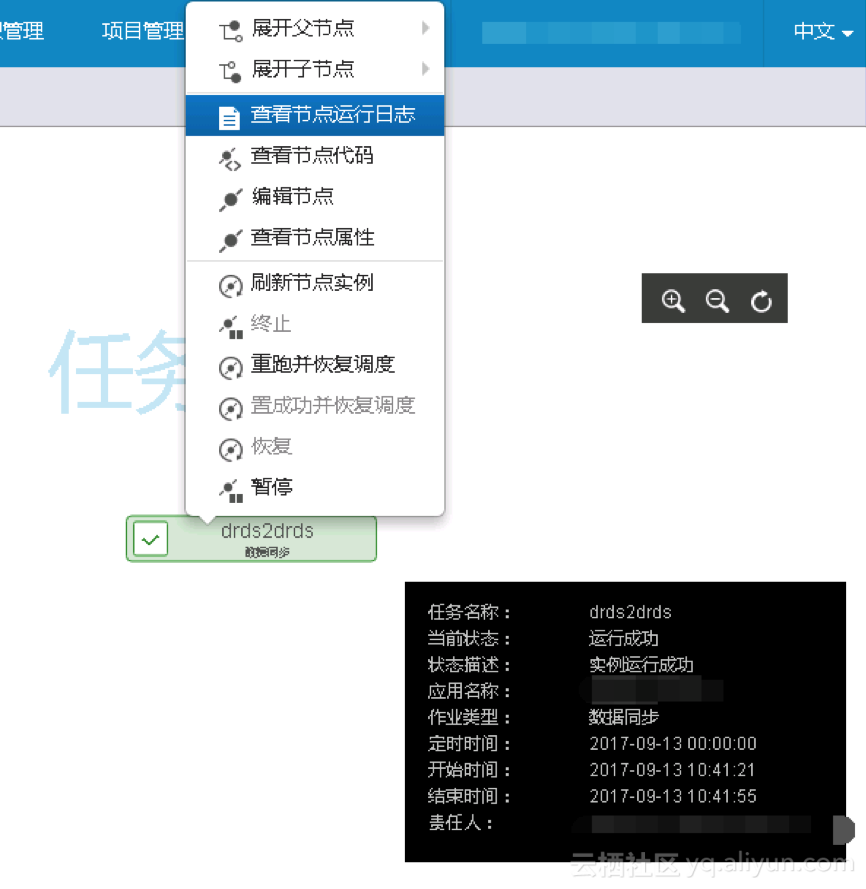
说明:
测试运行是手动触发任务,只要定时时间到了,立即运行,无视实例的上游依赖关系。
若同步任务只需要运行一次,测试运行完成后在调度属性中将调度状态选为暂停即可。
5.2 周期自动运行
周期自动运行,由系统根据所有任务的调度配置自动触发,故页面没有操作入口。查看实例信息和运行日志有以下两种:
(1)进入运维中心>任务运维页面,单击运维,选择业务日期或运行日期等参数,搜索drds2drds任务对应的实例,然后右键查看实例信息,并可对已调度起的实例任务进行日常的运维管理,如对任务进行终止、重跑、修复等操作。如下图所示:
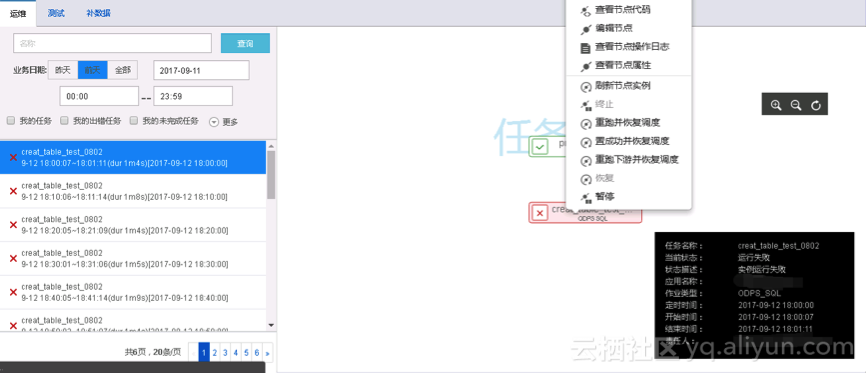
(2)查看运行日志;单节点任务实例、工作流任务节点右击展开的下拉菜单中可以选择查看当前选中对象在执行过程中的相关日志信息。如下图所示:
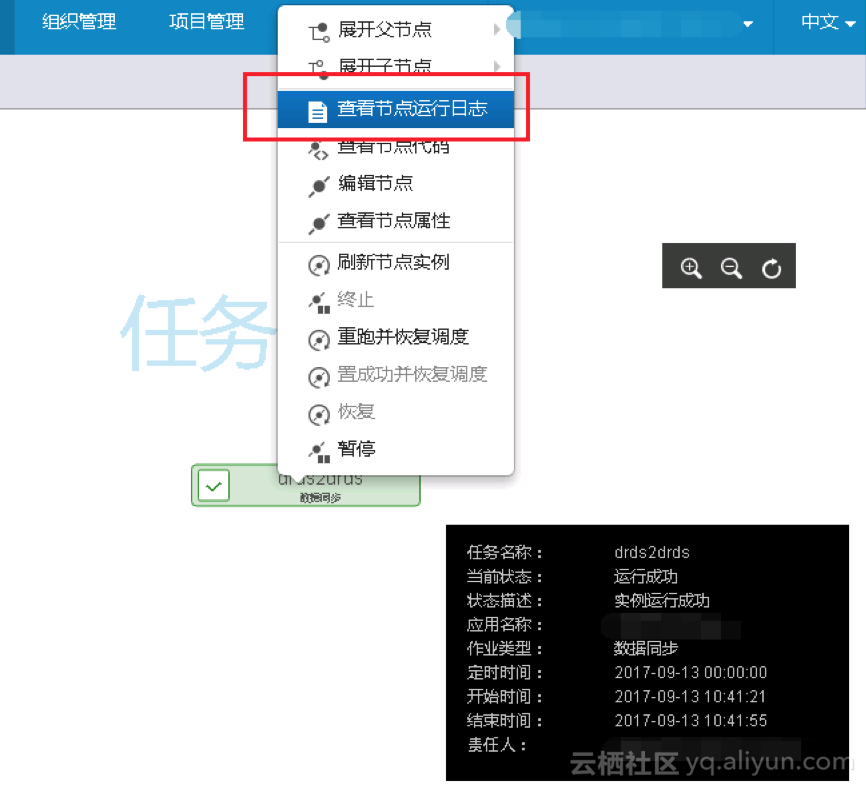
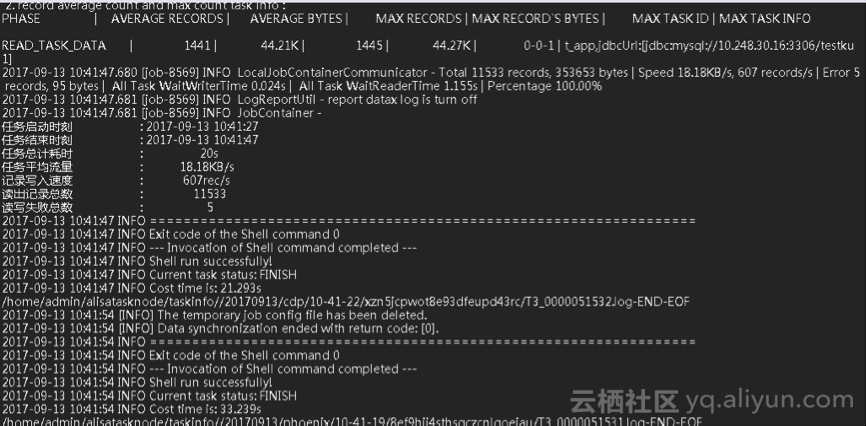
说明:
l 若任务的实例初始状态为未运行,当定时时间到达时,调度系统会检查这个实例的全部上游实例是否运行成功。
l 只有上游实例全部运行成功并且定时时间到达的实例,才会被触发运行。
l 处于未运行状态的实例,请确认上游实例已经全部成功且已到定时时间。