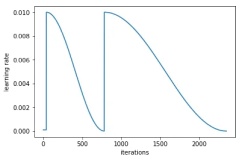
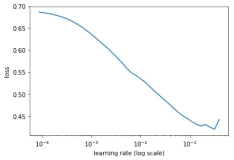
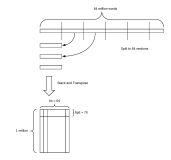
6.4 基于深度学习的知识图谱构建
随着深度学习在自然语言处理领域应用的不断深入,人们也开始尝试将深度神经网络用于知识图谱的自动构建。在此,以实体和关系的表示学习技术为基础,讨论深度学习在命名实体识别、关系抽取、关系补全等任务上的应用。
命名实体识别
命名实体识别是从文本中提取出和人名、地名等特定的短语或名称的任务。早期的命名实体识别主要基于规则和词典来进行,对规律性较强的文本环境较为适合,但难以摆脱对领域专家的的依赖,费时费力且难以移植[28] 。随着语料数据的增长,研究者逐步将机器学习和统计分析技术应用于命名实体识别,其方法可以分为有监督、半监督和无监督的方法。
有监督方法基于序列标注思想,结合大量标注语料,定义一系列实体来训练判别模型。传统模型包括隐马尔科夫模型(HMM) [29] 、最大熵马尔科夫模型(MEMM) [30] 、条件随机场(CRF) [31] 等。在深度学习领域,针对序列标注的思路,研究者将卷积神经网络[18]和循环神经网络[21]用于该任务,结合词语的表示学习,取得了优于传统方法的结果。
半 监 督( 或 弱 监 督) 方 法 主 要 采 用 boot-strapping 技术,只利用很少的标注数据作为种子开始学习,结合大量无标注数据,通过模板、句法分析树等方式迭代地从上下文中发现实体[32] 。
无监督方法则在无标注数据集的情况下,采用聚类等方法,利用类似的上下文推测出类似的概念和实例;或者基于外部知识(如 WordNet 等),完成从一个领域到另一领域的迁移学习。随着文本数据资源的不断丰富,研究者结合词的向量表示和已有的词典等信息,利用词向量之间的相对关系 ( 如v (king) -v(queen) = v(man) -v(woman)) 通过训练词向量和评估词语之间的投射关系矩阵,发现新的上下位实体[33-36] 。
关系抽取和补全
关系抽取是指从无结构的自然语言文本中找出实体之间的语义关系。早期主要采用基于规则的方法,提前定义关系所对应的结构规则,进行特定领域的关系抽取。而后,主要采用基于特征和核函数的方法,前者主要通过提取文本的语法特征[37]来构建关系的分类器;后者则利用短语句法、依存语法、实体之间路径关系等信息设计相应的核函数,并通过核函数计算两个实例的关系来完成关系抽取[38] 。近期,研究者将循环神经网络等深度学习技术应用于关系抽取中。例如,Xu et al [39] 提出一种基于 LSTM 循环神经网络的方法,对自然语言语句的依存树中不同实体间的最短依赖路径进行分析,以确定实体间关系的类别,该方法证实了深度神经网络在关系抽取中的有效性。
关系补全是基于知识库中已有的知识,进行推理或计算,对知识库中缺少的关系进行填补的任务。根据分析目标的不同可以分为两个方面,一是已知某关系两端的实体,求取两实体之间的关系;二是已知某个实体和与之关联的关系,求取该关系另一端的实体。前者可称为链接预测,后者可称为实体预测。当前,常见的关系补全方法包括基于张量重构的方法和基于翻译模型的方法等。基于张量重构的方法,以 RESCAL 系统为主要代表[40-42] ,将知识库的整个实体关系网络看作三维张量,其中每个二维切片是对一种关系的描述,该方法将整个知识库的信息进行编码整合,推理过程计算量小,但当知识库规模较大时,张量重构的代价较大。基于翻译模型的方法则将知识库中的关系看作实体间的平移向量,即将关系三元组 < 实体 S,关系 P,实体O> 中的尾部实体 O 看作头部实体 S 经过关系 P 的翻译结果。Trans* 系列模型是这类方法的代表。其中,Bordes et al [43] 提出的 TransE 模型通过结合实体和关系的表示学习,对知识库中的 1-1 关系进行补全。在此基础上,为了近一步处理1-N、N-1、N-N等复杂关系,出现了 TransII、TransR 等模型[44-45] ,为了将孤立三元组关系的语义融合为关系路径的语义,出现了 PTransE 模型[46] ,为了近一步融合知识库三元组关系和外部文本知识,出现了 DKRL 模型[47]等。