[toc]
Hbase 常用shell操作
list
#查看default中的表
list
# 查看命名空间
list_namespace
#查看命名空间表
list_namespace_tables 'hbase'
create
#创建表
create 't5','cf1'
#创建命名空间
create_namespace 'beh'
#创建命名空间表
create 'beh:t5','cf'
#创建分区表
create 't1','f1', SPLITS => ['10','20','30']
create 't1','f1',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
put
# 向表中插入数据
put 'beh:t1','r1','cf1:c1','value1'
# 向命名空间的表中插入数据
put 'beh:t1','r2','cf1:c2','value2'
# 指定时间戳
put 'beh:t1','r3','cf1:c2','value2',1234567
#指定额外属性
put 'beh:t1','r100','cf:c2','value2',1234567 , {ATTRIBUTES=>{'mykey'=>'myvalue'}}
get
# 获取一行数据
get 't1','r1'
# 只获取cf2 列簇的数据
get 't1','r1','cf2'
# 只获取c1,c2两列数据
get 't1','r1',['cf2:c1','cf2:c2']
#限定时间戳
get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => 123456}
#限定版本
get 't1', 'r1', {COLUMN => 'c1', TIMESTAMP => 12345, VERSIONS => 4}
scan
# 扫描表
scan 't1'
# 扫描列
scan 't1',{COLUMN => ['cf1:c1','cf2:c2']}
# limit 10
scan 't1',{LIMIT => 10}
# 设置开始位置
scan 't1',{STARTROW => 'r20'}
# 添加过滤器
scan 't1', FILTER=>"ColumnPrefixFilter('c2') AND ValueFilter(=,'substring:8')"
drop 和delete
#删除数据
deleteall 't1','r1'
#删除一列数据
delete 't1','r2','cf1,c1'
# 删除表
disable 't1'
drop 't1'
#清空表
truncate 't1'
hbase起停
#启动
start-hbase.sh
#启动单个服务
hbase-daemon.sh start master
hbase-daemon.sh start regionserver
hbase常用java api
package com.bonc.hbase;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.NamespaceDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Operation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.filter.BinaryComparator;
import org.apache.hadoop.hbase.filter.ColumnPaginationFilter;
import org.apache.hadoop.hbase.filter.ColumnPrefixFilter;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.FamilyFilter;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.Filter.ReturnCode;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.FilterList.Operator;
import org.apache.hadoop.hbase.filter.PageFilter;
import org.apache.hadoop.hbase.filter.RowFilter;
import org.apache.hadoop.hbase.filter.SingleColumnValueExcludeFilter;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.filter.ValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
@SuppressWarnings("deprecation")
public class ApiSample {
private static HBaseAdmin admin;
private static HTable table;
private static byte[] tableName = Bytes.toBytes("a1");
private static byte[] cf1 = Bytes.toBytes("cf1");
private static byte[] cf2 = Bytes.toBytes("cf2");
Configuration conf = HBaseConfiguration.create();
{
try {
admin = new HBaseAdmin(conf);
} catch (Exception e) {
}
}
public static void main(String[] args) throws Exception {
ApiSample sample = new ApiSample();
// sample.listTable();
// sample.listNameSpace();
// sample.listTableWithNamespace();
// // sample.createTable();
// // sample.createTableWithSplit();
// sample.editVersion();
// sample.putData();
// sample.getData();
// sample.scanData();
sample.scanDataWithFilter();
sample.deleteData();
sample.dropTable();
}
// list
public void listTable() throws Exception {
System.out.println("---------table------------------");
TableName[] ts = admin.listTableNames();
for (TableName tb : ts) {
System.out.println(tb.getNameWithNamespaceInclAsString());
}
}
// list namespace
public void listNameSpace() throws Exception {
System.out.println("---------namespace------------------");
NamespaceDescriptor[] nss = admin.listNamespaceDescriptors();
for (NamespaceDescriptor ns : nss) {
System.out.println(ns.getName());
}
}
// 获取 beh 命名空间下的表
// list
public void listTableWithNamespace() throws Exception {
System.out.println("---------table on beh------------------");
TableName[] ts = admin.listTableNamesByNamespace("beh");
for (TableName tb : ts) {
System.out.println(tb.getNameWithNamespaceInclAsString());
}
}
// 创建表 a1 列簇: cf1,cf2
public void createTable() throws Exception {
System.out.println("---------create table------------------");
HTableDescriptor t = new HTableDescriptor(tableName);
t.addFamily(new HColumnDescriptor(cf1));
t.addFamily(new HColumnDescriptor(cf2));
admin.createTable(t);
}
// 创建预分区表a1 列簇: cf1,cf2 开始row 1 结束row 9 分10个分区
public void createTableWithSplit() throws Exception {
System.out.println("---------create table with 10 regin------------------");
HTableDescriptor t = new HTableDescriptor(Bytes.toBytes("a2"));
t.addFamily(new HColumnDescriptor(cf1));
t.addFamily(new HColumnDescriptor(cf2));
admin.createTable(t, Bytes.toBytes(0), Bytes.toBytes(9), 10);
}
// put数据
public void putData() throws Exception {
System.out.println("---------put data to a1------------------");
table = new HTable(conf, tableName);
Put p1 = new Put(Bytes.toBytes("r1"));
p1.add(cf1, Bytes.toBytes("c1"), Bytes.toBytes("v1"));
p1.add(cf2, Bytes.toBytes("c2"), Bytes.toBytes("v666"));
p1.add(cf1, Bytes.toBytes("c3"), Bytes.toBytes("v3"));
Put p2 = new Put(Bytes.toBytes("r3"));
p2.add(cf1, Bytes.toBytes("c1"), Bytes.toBytes("v4"));
p2.add(cf2, Bytes.toBytes("c2"), Bytes.toBytes("v5"));
p2.add(cf1, Bytes.toBytes("c3"), Bytes.toBytes("v6"));
table.put(p1);
table.put(p2);
table.close();
}
// 修改a1存储多版本
public void editVersion() throws Exception {
System.out.println("---------修改表存储多版本------------------");
HColumnDescriptor cf = new HColumnDescriptor(cf2);
cf.setMaxVersions(3);
admin.modifyColumn(tableName, cf);
}
// get数据
public void getData() throws Exception {
System.out.println("---------get data from a1------------------");
table = new HTable(conf, tableName);
Get get = new Get(Bytes.toBytes("r1"));
printResult(table.get(get));
System.out.println("---------get r1 only cf2 family-----------------");
get.addFamily(cf2);
printResult(table.get(get));
System.out.println("----------get with max version----------------");
get.setMaxVersions();
printResult(table.get(get));
table.close();
}
// scan
public void scanData() throws Exception {
System.out.println("---------scan data from a1------------------");
table = new HTable(conf, tableName);
Scan scan = new Scan();
printResultScan(table.getScanner(scan));
System.out.println("---------scan data from a1 start with row key r2------------------");
scan.setStartRow(Bytes.toBytes("r2"));
printResultScan(table.getScanner(scan));
System.out.println("---------scan data from a1 start with row key r2 only get cf1 :c1 data-----------------");
scan.addColumn(cf1, Bytes.toBytes("c1"));
printResultScan(table.getScanner(scan));
table.close();
}
// scan
/**
* row过滤 过滤设置scan范围 设置setRowPrefixFilter 跟设置开始结束一样 使用rowFilter family
* addFalimy() FamilyFilter 列过滤 addColumn() ColumnPrefixFilter
* ColumnPaginationFilter 值过滤 valueFilter SingleColumnValueFiler
* SingleColumnValueExcludeFilter
*
* @throws Exception
*/
public void scanDataWithFilter() throws Exception {
System.out.println("---------scan data with row filter from a1------------------");
table = new HTable(conf, tableName);
Scan scan = new Scan();
Filter fiter = new RowFilter(CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("r1")));
scan.setFilter(fiter);
printResultScan(table.getScanner(scan));
System.out.println("---------scan data with add family from a1------------------");
// scan.addFamily(cf1);
printResultScan(table.getScanner(scan));
System.out.println("---------scan data with cf Filter filter from a1------------------");
scan.setFilter(new FamilyFilter(CompareOp.EQUAL, new BinaryComparator(Bytes.toBytes("cf1"))));
printResultScan(table.getScanner(scan));
System.out.println("---------scan data with column prefix filter from a1------------------");
FilterList list = new FilterList(Operator.MUST_PASS_ALL);
list.addFilter(new ColumnPrefixFilter(Bytes.toBytes("c")));
scan.setFilter(list);
printResultScan(table.getScanner(scan));
System.out.println("---------scan data with column pagination filter from a1------------------");
// 对行进行分页,获取一行的几列,从哪开始
list.addFilter(new ColumnPaginationFilter(2, 2));
scan.setFilter(list);
printResultScan(table.getScanner(scan));
System.out.println("---------scan data with value filter from a1------------------");
list.addFilter(new ValueFilter(CompareOp.GREATER_OR_EQUAL, new BinaryComparator(Bytes.toBytes("v5"))));
scan.setFilter(list);
printResultScan(table.getScanner(scan));
System.out.println("---------scan data with column value filter from a1------------------");
list.addFilter(new SingleColumnValueFilter(cf1, Bytes.toBytes("c2"), CompareOp.GREATER, Bytes.toBytes("v5")));
scan.setFilter(list);
printResultScan(table.getScanner(scan));
System.out.println("---------scan data with column value include filter from a1------------------");
list.addFilter(
new SingleColumnValueExcludeFilter(cf1, Bytes.toBytes("c2"), CompareOp.GREATER, Bytes.toBytes("v5")));
scan.setFilter(list);
printResultScan(table.getScanner(scan));
table.close();
}
public void deleteData() throws Exception {
System.out.println("---------delete data from a1------------------");
table = new HTable(conf, tableName);
Delete delete = new Delete(Bytes.toBytes("r1"));
table.delete(delete);
System.out.println("---------get r1 from a1------------------");
Get get = new Get(Bytes.toBytes("r1"));
printResult(table.get(get));
table.close();
}
public void dropTable() throws Exception {
System.out.println("---------delete table a1------------------");
admin.disableTable(tableName);
admin.deleteTable(tableName);
admin.disableTable(Bytes.toBytes("a2"));
admin.deleteTable(Bytes.toBytes("a2"));
admin.close();
}
private void printResultScan(ResultScanner rs) throws Exception {
Result r = null;
while ((r = rs.next()) != null) {
printResult(r);
}
rs.close();
}
private void printResult(Result rs) {
if (!rs.isEmpty()) {
for (KeyValue kv : rs.list()) {
System.out.println(String.format("row:%s\t family:%s\t qualifier:%s\t value:%s\t timestamp:%s",
Bytes.toString(kv.getRow()), Bytes.toString(kv.getFamily()), Bytes.toString(kv.getQualifier()),
Bytes.toString(kv.getValue()), kv.getTimestamp()));
}
}
}
}
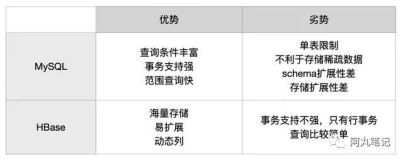
hbase 常见的二级索引
Coprocessor
思路
利用coprocessor可以在入库,查询前后的一些操作实现同时对所用表的入库,删除等维护索引表
实现
package com.bonc.hbase.coprocessor;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CoprocessorEnvironment;
import org.apache.hadoop.hbase.HRegionInfo;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HConnection;
import org.apache.hadoop.hbase.client.HConnectionManager;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.coprocessor.BaseMasterAndRegionObserver;
import org.apache.hadoop.hbase.coprocessor.MasterCoprocessorEnvironment;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.master.TableNamespaceManager;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.hbase.util.MD5Hash;
public class SecondaryIndexByComprocessorForGlobal extends BaseMasterAndRegionObserver {
private static String INDEX_TABLE_NAME = "index.table.name";
private static String INDEX_FAMILY_NAME = "index.family.name";
private static String TABLE_CELL = "table.cell";
private byte[] index_name;
private byte[] index_family;
private byte[] main_family;
private byte[] main_qualifier;
private Configuration conf;
private Connection conn;
/**
* 需要参数: 索引表名称,索引表列簇名称,主表需要索引列
*/
@Override
public void start(CoprocessorEnvironment ctx) throws IOException {
conf = ctx.getConfiguration();
index_name = Bytes.toBytes(conf.get(INDEX_TABLE_NAME));
index_family = Bytes.toBytes(conf.get(INDEX_FAMILY_NAME));
String cell = conf.get(TABLE_CELL);
if (cell != null) {
String[] s = cell.split(":");
main_family = Bytes.toBytes(s[0]);
main_qualifier = Bytes.toBytes(s[1]);
}
System.out.println("添加协处理器,建立索引的表:" + Bytes.toString(index_name) + " ,被索引的列 : " + cell);
super.start(ctx);
}
private Connection getConnection() {
if (conn == null || conn.isClosed()) {
try {
conn = ConnectionFactory.createConnection(conf);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
return conn;
}
private Table getTable() throws IllegalArgumentException, IOException {
return getConnection().getTable(TableName.valueOf(index_name));
}
@Override
// 定义创建表之前的动作,因为表创建表之前无法确定有那些列,索引没办法同步创建索引表
public void preCreateTable(ObserverContext<MasterCoprocessorEnvironment> ctx, HTableDescriptor desc,
HRegionInfo[] regions) throws IOException {
// TODO Auto-generated method stub
super.preCreateTable(ctx, desc, regions);
}
@Override
// put数据之后执行,但是很难保证事务性
public void postPut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability)
throws IOException {
// put
List<Cell> list = put.get(main_family, main_qualifier);
if (list != null && !list.isEmpty()) {
for (Cell cell : list) {
putDataToIndex(cell);
}
}
super.prePut(e, put, edit, durability);
}
@Override
// 主表删除数据后,索引表删除数据
public void preDelete(ObserverContext<RegionCoprocessorEnvironment> e, Delete delete, WALEdit edit,
Durability durability) throws IOException {
byte[] row = delete.getRow();
Result result = e.getEnvironment().getRegion().get(new Get(row));
KeyValue kv = result.getColumnLatest(main_family, main_qualifier);
byte[] value = kv.getValue();
deleteDataFromIndex(Bytes.add(Bytes.toBytes(MD5Hash.getMD5AsHex(value).substring(0, 8)), value, row));
super.postDelete(e, delete, edit, durability);
}
@Override
// 删除表时同时删除索引表
public void postDeleteTable(ObserverContext<MasterCoprocessorEnvironment> ctx, TableName tableName)
throws IOException {
Admin admin = getConnection().getAdmin();
admin.deleteTable(TableName.valueOf(INDEX_TABLE_NAME));
super.postDeleteTable(ctx, tableName);
}
private void deleteDataFromIndex(byte[] row) {
Delete d = new Delete(row);
try {
Table table = getTable();
table.delete(d);
table.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
private void putDataToIndex(Cell cell) throws IOException {
byte[] row = cell.getRow();
byte[] value = cell.getValue();
Put put = new Put(Bytes.add(Bytes.toBytes(MD5Hash.getMD5AsHex(value).substring(0, 8)), value, row));
put.add(index_family, Bytes.toBytes("c"), row);
Table table = getTable();
table.put(put);
table.close();
}
}