ZD至顶网服务器频道 04月06日 新闻消息: GTC16大会消息:期待已久,NVIDIA的Pascal架构GPU终于出笼。它就是GP100,GP100将现身于Tesla P100里,目标应用是高性能计算(如超级计算机模拟天气和核燃料之类的)和深度学习人工智能系统。

P100是今天在加州圣何塞的NVIDIA的GPU技术大会(GTC)上宣布推出的。P100内含150亿个晶体管(如算上16GB内存的话则为 1500亿个),基于16nm FinFET。用户如想染手该硬件,可以买一个129000美元的DGX-1盒,DGX-1消耗的功率为3200瓦,六月份交货,计算能力为170TFLOPS;或是等大云提供商今年后半年提供相应的在线服务;或是2017年初从诸如IBM、Cray、惠普企业、戴尔等商家买一个配有Pascal的服务器。这些云巨头正在大肆购入该数字处理芯片。
P100不是针对游戏玩家和台式机推出的;而是用来吸引科学家和软件工程师加入Nvidia的CUDA派对及在GPU上运行人工智能(AI)培训系统、颗粒分析代码等等的。Nvidia公司联合创始人兼首席执行官黄仁勋告诉与会人士,”深度学习将出现在各种应用程序里。”
不过,除非Nvidia会变戏法,这些Pascal设计终将以自己的方式进入普通老百姓的电脑里。Pascal架构里有一些奇妙的设计。笔者在下面总结一下。
相当大度
自CUDA 6以来,Nvidia为程序员提供了所谓的统一内存(Unified Memory),顾名思义,统一内存提供了主机里GPU和CPU一个共享虚拟地址空间。此方法为开发者提供了GPU和CPU内核之间的统一访问。统一内存空间的最大值和GPU内存相同。
而在新推出的Pascal里, 其GP100可以在统一内存里触发页面错误(Page fault),允许数据按需要载入。换句话说,它不是等着花时间将大量数据移入GPU内存里,而是在图形处理器里运行的代码假定数据已经在GPU内存里并在需要是访问这些数据。如果数据记忆不存在,即会触发页面错误,所需的数据随后会从其他地方移过来。

例如,如果用户分配了2GB阵列的共享内存,假定在CPU内核运行的现代操作系统开始修改其内容,则该CPU在访问原始配置时触发页面错误,并将虚拟记忆空间映射到物理记忆空间。然后,GPU开始在阵列里进行写入操作。其记忆页面对CPU来说是实打实存在的,但对于GPU来说却不是,因此,GPU将阵列里的内容逐页迁移到物理内存里,而在CPU里这些记忆页面则被标记为不存在。
CPU随后修改阵列时,会触发页面错误,并从GPU里取出数据。所有这些对于软件开发者来说是“透明的”,统一内存提供了数据的一致性。这样做还可以令统一内存空间大于GPU物理内存,原因是数据在有需要时被加载。因此,统一内存的地址长度为49位。

要记住的是,该异构模型主要是针对科学和人工智能工作负载,用于处理大型和复杂的数据群:游戏及低延迟应用程序并不总是需要按需载入大量数据的页面错误触发操作。这种页面错误触发操作是颇为昂贵的操作,尤其是如果数据要在PCIe上迁移。但这另一方面意味着研究人员可以从平面内存模型里获得更多的简化和效率。程序员可以在他们的代码上向系统表明需要的来自GPU的预取内存大小,进而可以在启动新的内核时避免出现页面错误风暴。其GPU还可以并行地提供群页面错误服务,无需费时的一个接一个发出。每个页面的大小可达2MB。
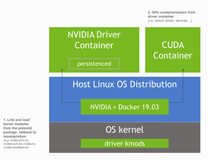
Nvidia还表示正在与Linux发行版厂商合作,将统一内存支持植入Linux系统:将来的软件只需调用一个通用malloc函数,然后将指针交给GPU,而底层操作系统会处理分配和页面操作,无需使用一个特殊的CUDA分配调用。

利用页面错误触发操作实现数据的连贯性。
内核层面
GP100里的每个GPU含3584个32位(单精度)CUDA内核和1792个64位(双精度)CUDA内核。这些32位内核也可以运行16位(半精)计算。
内置4MB的L2高速缓存,另有14MB的共享寄存器,可以以80TB/s的速率传输数据。基准时钟速度为1.3GHz,提升为1.4GHz,5.304TFLOPS双精度数学(使用半精则可达21TFLOPS)。TDP为300W。内核排列成56个SM(流处理器),单个SM的样子如下:

NVLink独挡一面
GP100用的是新型NVLink互连,图形处理器集群的连接不是用PCIe,而是用NVLink,速度为40Gb/s。这意味着数据将高速在图形处理器之间迁移。8个P100(DGX-1的配置)利用NVLink交换数据,其速度直逼1TB/s。

未来的计算内核(目前还只是IBM的OpenPower)可以直接与NVLink连线,因而就无需在慢悠悠的数据总线上传输数据。Tesla P100支持高达4Gb/s的双向链接,可用于读取和写入内存。性能的提升颇大。

本不该提,但是……
在P100里运行的软件可以在指令边界请求优先处理,无需等到绘图调用结束。这意味着其他线程可以立即让位给一个优先级高的线程,而无需等到冗长的绘制操作结束。这种额外的延迟(等待调用结束)对于时间敏感的应用是很麻烦的事,如虚拟现实耳机应用。5毫秒的延迟可能导致Vsync的遗漏,继而在实时渲染出现画面失常,会让一些人抓狂。
而如果在指令层次处理,这种由延迟导致的恶果就会消失,对虚拟现实游戏玩玩家来说是个好消息。指令层次上的优先请求意味着程序员也可以通过GPU进行单步代码找错。
为内存致谢
P100采用HBM2(高带宽内存的英文缩写),以720GB/s的速率交换数据,纠错机制免费奉送,之前的Nvidia芯片为实现纠错牺牲一些存储空间。

据说HBM2提供的容量大于置于芯片外的DDR5 RAM,使用的功率也更少。每个HBM2堆栈的存储最多可达8GB。P100含4个HBM2堆栈,内存共为 16GB。整套(CPU加内存)的尺寸为55毫米x 55毫米。芯片模版本身的面积为600平方毫米。
该GP100还增添了新的原子指令:全局内存里的双精度浮点原子加法运算。
有媒体人士发文称,“黄仁勋表示,数以千计的工程师一直在为Pascal GPU架构不懈的工作着。Nvidia三年前“全面进入”机器学习,同时启动了Pascal GPU架构工程,其间投入了30亿美元。Nvidia想拿回这些钱,当然也想赚一些钱。”
原文发布时间为:2016-04-06
本文来自云栖社区合作伙伴至顶网,了解相关信息可以关注至顶网。