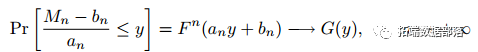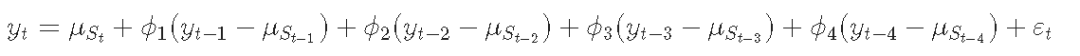热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
Mysql性能优化这5点你知道吗?简单却容易被初学者忽略!
R语言有极值(EVT)依赖结构的马尔可夫链(MC)对洪水极值分析
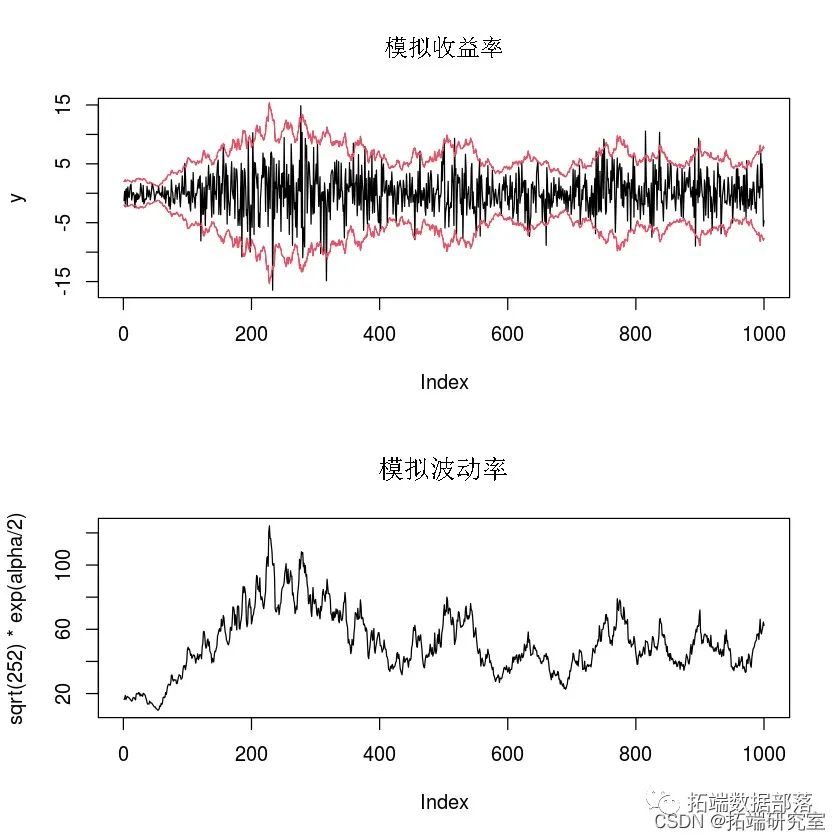
R语言隐马尔可夫模型HMM连续序列重要性重抽样CSIR估计随机波动率模型SV分析股票收益率时间序列
Linux系统之安装ServerBee服务器监控工具
仅需几步就可快速实现SFTP的免密传输
PYTHON用时变马尔可夫区制转换(MARKOV REGIME SWITCHING)自回归模型分析经济时间序列
IDM 平替 Gopeed Flutter 开源免费下载工具
构建高效微服务架构:后端开发的现代实践
深度学习在图像识别中的应用与挑战
R语言用多元ARMA,GARCH ,EWMA, ETS,随机波动率SV模型对金融时间序列数据建模(下)
构建未来:云原生架构在企业数字化转型中的关键作用
构建高效机器学习模型的策略与实践
基于RT-Thread的智能家居助手
【视频】从决策树到随机森林:R语言信用卡违约分析信贷数据实例|数据分享
CDN的优缺点是什么呢
如何利用CDN优化
数据分享|R语言用主成分分析(PCA)PCR回归进行预测汽车购买信息可视化
前端如何做性能优化?
数据分享|Python决策树、随机森林、朴素贝叶斯、KNN(K-最近邻居)分类分析银行拉新活动挖掘潜在贷款客户
sql数据库引擎失败
数据分享|R语言生存分析模型因果分析:非参数估计、IP加权风险模型、结构嵌套加速失效(AFT)模型分析流行病学随访研究数据
Ansible自动化运维工具安装和基本使用
Python 用ARIMA、GARCH模型预测分析股票市场收益率时间序列(下)
Python 用ARIMA、GARCH模型预测分析股票市场收益率时间序列(中)
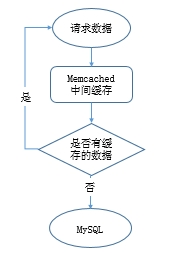
缓存命中率和过期机制的一般思路
Python 用ARIMA、GARCH模型预测分析股票市场收益率时间序列(上)
运维角度浅谈MySQL数据库优化
深入理解PHP的命名空间
网络安全与信息安全:防范漏洞、强化加密、提升意识
探索代码之美:我的编程哲学
linux系统缓存机制
【Go语言快速上手(三)】数组, 切片与映射
【Go语言快速上手(二)】 分支与循环&函数讲解
Redis配置文件详解(redis.conf)
【Go语言快速上手(一)】 初识Go语言
【鹅厂摸鱼日记(一)】(工作篇)认识八大技术架构
【linux网络(一)】初识网络, 理解四层网络模型
【linux线程(四)】初识线程池&手撕线程池
【linux线程(三)】生产者消费者模型详解(多版本)
【linux线程(二)】线程互斥与线程同步
【linux线程(一)】什么是线程?怎样操作线程?
【linux进程信号(二)】信号的保存,处理以及捕捉
【linux进程信号(一)】信号的概念以及产生信号的方式
【linux进程间通信(二)】共享内存详解以及进程互斥概念
【项目日记(九)】项目整体测试,优化以及缺陷分析
【项目日记(八)】第三层: 页缓存的具体实现(下)