11月17日,在正在举行的2015全球超级计算大会(SC15)上,浪潮联合全球可编程逻辑芯片巨头Altera,以及中国最大的智能语音技术提供商科大讯飞,共同发布了一套面向深度学习、基于AlteraArria 10 FPGA平台、采用OpenCL开发语言进行并行化设计和优化的深度学习DNN的语音识别方案。同时,此次发布也标志着浪潮成为全球领先的具备GPU、MIC和FPGA三项HPC异构计算应用能力的HPC系统厂商。

深度学习,需要HPC“提速”
让计算机拥有接近人类的智能水平是IT行业最伟大,也是最难实现的梦想,而深度学习则是通往人工智能的漫漫长路上一项重要的技术。深度学习的出发点是通过构建深层神经网络,模拟人脑神经元和神经突触的信息和数据传输及计算,在抽象出来的规则限定下,逐渐让机器像人一样理解真实的世界。

不过,由于人脑每天能接触数以万计的信息并且在短短几秒内给出判断和反映,所以要实现让机器能真正像人类一样思考不仅依靠算法模型的精确,同时也需要媲美人脑计算效率的高性能计算技术。
可以说,深度学习对计算力资源的需求如同“黑洞”一般永无止境,这使得近几年异构加速技术在该领域得到越加广泛的应用,协处理器运算速度的快速提升让深度学习技术得到了硬件层面的有力支持。
FPGA,通用和专用之间的半定制化芯片
FPGA(Field-ProgrammableGate Array,现场可编程门阵列)介于专用芯片和通用芯片之间,具有一定的可编程性,可同时进行数据并行和任务并行计算,在处理特定应用时有更加明显的效率。更重要的是,FPGA具有明显的性能功耗比优势,其能耗比是CPU的10倍以上、GPU的3倍。此外,可定制化也是FPGA的一大重要特性。

正是因为具备极强的性能功耗比优势和定制化特点,FPGA在诸多领域得到应用,如逻辑控制,信号处理,图像处理等方面,最近更是在深度学习中的在线识别系统中开始尝试使用。
不过,传统FPGA开发采用Verilog、VHDL等硬件描述语言,对开发者要求较高,开发周期也较长,因此在高性能计算应用受到限制。而采用OpenCL,利用软件高级语言和模型编程,开发周期可大幅缩短,对于一些应用可以实现几个人月完成,为FPGA的应用发展提供了更为广阔的平台。

利用OpenCL实现基于FPGA平台的语音识别系统
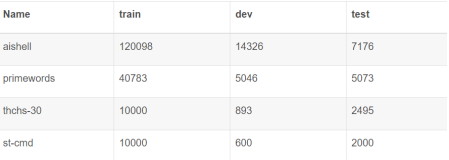
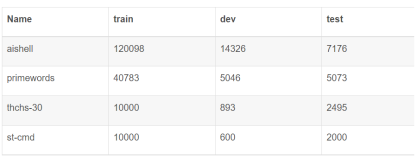
科大讯飞拥有中国最大的语音识别系统,在常用场景下准确率已达到98%,在业内领先。。为了进一步提升DNN算法的效率和性能,科大讯飞计划在语音识别业务中启用FPGA平台,而若性能符合要求,则将在未来建造一个上万规模的FPGA语音识别系统。科大讯飞技术总监于振华表示,深度学习模型的软件算法需要不断地微调和优化,随着时间的推移,固定功能的服务器加速器效率会变得越来越低,浪费空间和电力。相比之下,FPGA可以更加灵活的定制化,并且功耗更低。这也是科大讯飞决定将DNN算法移植到FPGA平台的重要原因。

于是一项由浪潮、科大讯飞和Altera公司共同发起的合作诞生了——由Altera公司提供Altera Arria 10 FPGA平台,科大讯飞提供DNN识别算法,浪潮则负责完成基于FPGA 平台,采用OpenCL进行DNN的并行设计、迁移与优化。经过努力,三方最终完成了基于OpenCL的FPGA线上深度学习语音识别加速方案。该方案硬件平台采用CPU+AlteraArria 10 FPGA异构架构,软件完全采用高级编程模式OpenCL实现从CPU到FPGA的迁移,具备四大特点:
高性能:处理100 bound数据,基于IntelXeon E5-2650 V2 双路CPU(启动16个线程),DNN运行时间为242.027s,而基于Altera ARRIA 10 FPGA,DNN运行时间为84.312s,性能加速2.871倍;
低功耗:Altera Arria 10FPGA功耗为30W,Intel Xeon E5-2650 V2 双路CPU功耗为190W,FPGA功耗只有CPU的15.7%,在DNN 实际运行测试中,FPGA可实现30GFlops/W的高性能功耗比,能大大节省应用功耗成本;
易编程:采用OpenCL编程模型,基于FPGA的DNN并行程序开发完全由软件工程师完成,仅仅耗费4个人月。若采用传统的Verilog、VHDL等底层语言,同样的开发工作至少需要12个人月,并且需要软件工程师和硬件工程师配合完成。
高适用性:FPGA即可以采用DNRange模式实现数据并行,也可以采用Pipeline模式实现任务并行,从而满足了更多的应用场景,可以为更多的应用软件带来性能提升。
Altera公司服务器和存储事业部总经理DavidGamba表示,此次三方成功完成基于Altera ARRIA 10 FPGA平台的OpenCL 并行化设计与开发,创造出极高的功耗性能比,进一步验证了Altera FPGA平台的优势。本次方案的开发成功将成为FPGA在深度学习领域应用的重要参考。
 通过此次合作,三方实现了基于FPGA的HPC新异构加速模式和技术的可行性研究,在实际深度学习DNN应用的验证中,此方案在提升性能、节省功耗的同时,实现了OpenCL易编程性的印证。
通过此次合作,三方实现了基于FPGA的HPC新异构加速模式和技术的可行性研究,在实际深度学习DNN应用的验证中,此方案在提升性能、节省功耗的同时,实现了OpenCL易编程性的印证。
谈及下一步合作,浪潮集团副总裁胡雷钧表示,浪潮一直致力于为用户提供最适合其需求的计算系统解决方案。FPGA具有极高的性能功耗比优势,浪潮将进一步和科大讯飞、Altera公司开展基于FPGA的线上语音深度学习应用合作,同时浪潮还将研发基于FPGA的通用系统方案,包括整机柜计算、网络、存储FPGA方案,并将方案推广到其它应用领域和客户。
谈及下一步合作,浪潮集团副总裁胡雷钧表示,浪潮一直致力于为用户提供最适合其需求的计算系统解决方案。FPGA具有极高的性能功耗比优势,浪潮将进一步和科大讯飞、Altera公司开展基于FPGA的线上语音深度学习应用合作,bing研发基于FPGA的通用系统方案,包括整机柜计算、网络、存储FPGA方案,并将方案推广到其它应用领域和客户。未来,CPU+FPGA或许将作为HPC新的异构模式,被越来越多的HPC大应用、数据中心、互联网深度学习等越来越多的应用领域采用。
浪潮、科大讯飞、Altera简介
浪潮依托高效能服务器和存储技术国家重点实验室、国家信息存储技术工程中心、Inspur-Intel中国并行计算联合实验室、Inspur-NIVDIA云超算创新中心等全球领先的研发创新体系,浪潮拥有从万亿次到千万亿次的超级计算机产品研发、系统建设、运维服务能力,拥有完备的HPC软硬件产品线,为中国高校科研、石油勘探、气象预报、生命基因、航天航空、制造设计、动漫渲染、环保监测等众多行业用户提供了领先优质的超算系统与应用服务,并实现国产高性能计算机系统的海外出口产业化。
科大讯飞作为中国最大的智能语音技术提供商,在智能语音技术领域有着长期的研究积累,并在语音合成、语音识别、口语评测、自然语言处理等多项技术上拥有国际领先的成果。科大讯飞的语音识别技术在常用场景下准确率已达到98%,业内领先。
Altera公司站在技术创新的最前沿,30 多年来一直为业界提供最新的可编程逻辑、工艺技术、IP 内核以及开发工具。公司的 FPGA、SoC和嵌入式处理器系统、CPLD、ASIC,以及互补技术,例如,电源解决方案等,受到了全世界各类最终市场上 12,000 多名客户的欢迎。
谈及下一步合作,浪潮集团副总裁胡雷钧表示,浪潮一直致力于为用户提供最适合其需求的计算系统解决方案。FPGA具有极高的性能功耗比优势,浪潮将进一步和科大讯飞、Altera公司开展基于FPGA的线上语音深度学习应用合作,并研发基于FPGA的通用系统方案,包括整机柜计算、网络、存储FPGA方案,并将方案推广到其它应用领域和客户。
原文发布时间为:2015年11月18日
本文来自云栖社区合作伙伴至顶网,了解相关信息可以关注至顶网。