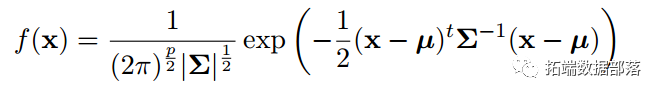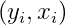热门
万字长文:一文彻底搞懂Elasticsearch中Geo数据类型查询、聚合、排序
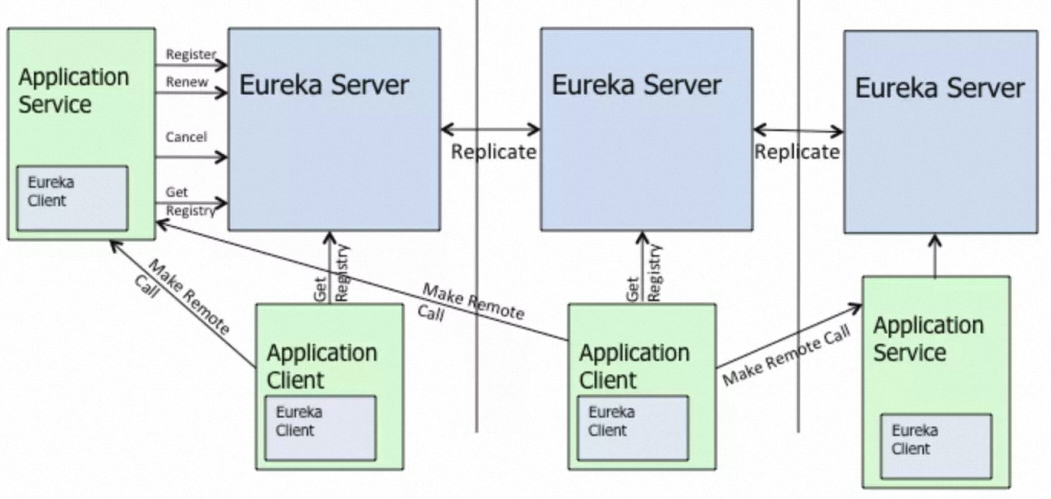
上一任留下的 Eureka,我该如何提升她的性能和稳定性(含数据比对)?
蚂蚁流场景状态演进和优化
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
西瓜书机器学习AUC与ℓ-rank(loss)的联系理解以及证明(通俗易懂)
偏最小二乘回归(PLSR)和主成分回归(PCR)
面试题 01.06. 字符串压缩
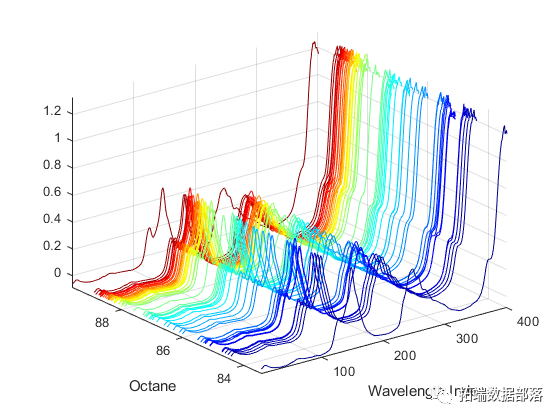
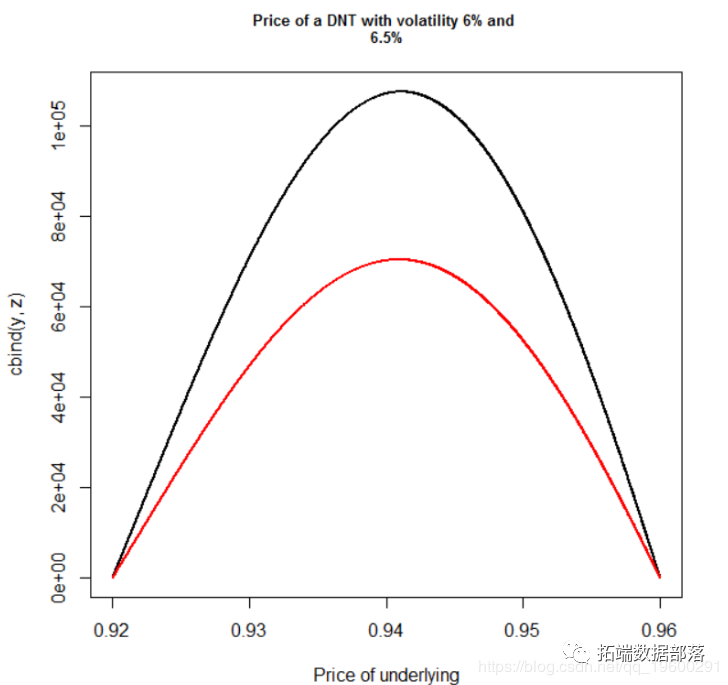
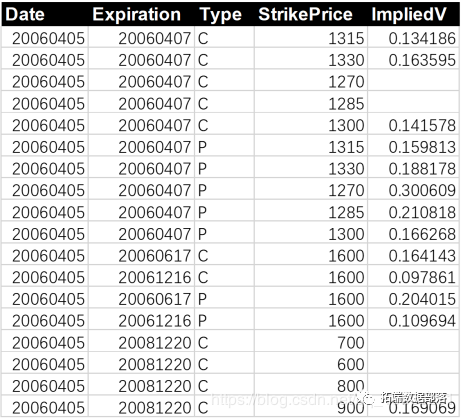
r语言二元期权barrier option实现案例
08.04. 幂集
vue展示json数据,vue-json-viewer的使用
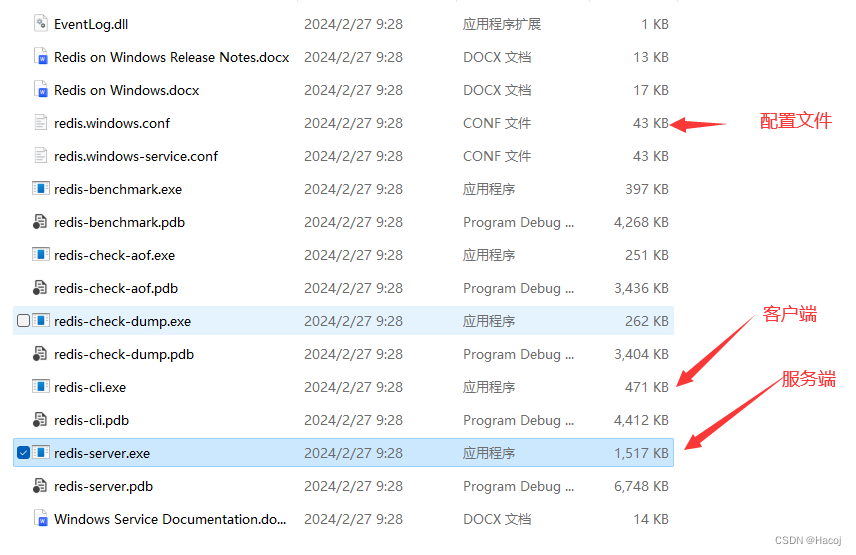
Redis介绍以及日常使用
R语言中如何使用排队论预测等待时间?
什么是虚地址,什么是物理地址?
R语言实现:混合正态分布EM最大期望估计法
CPU的内存分页
什么是TLB
r语言多均线股票价格量化策略回测
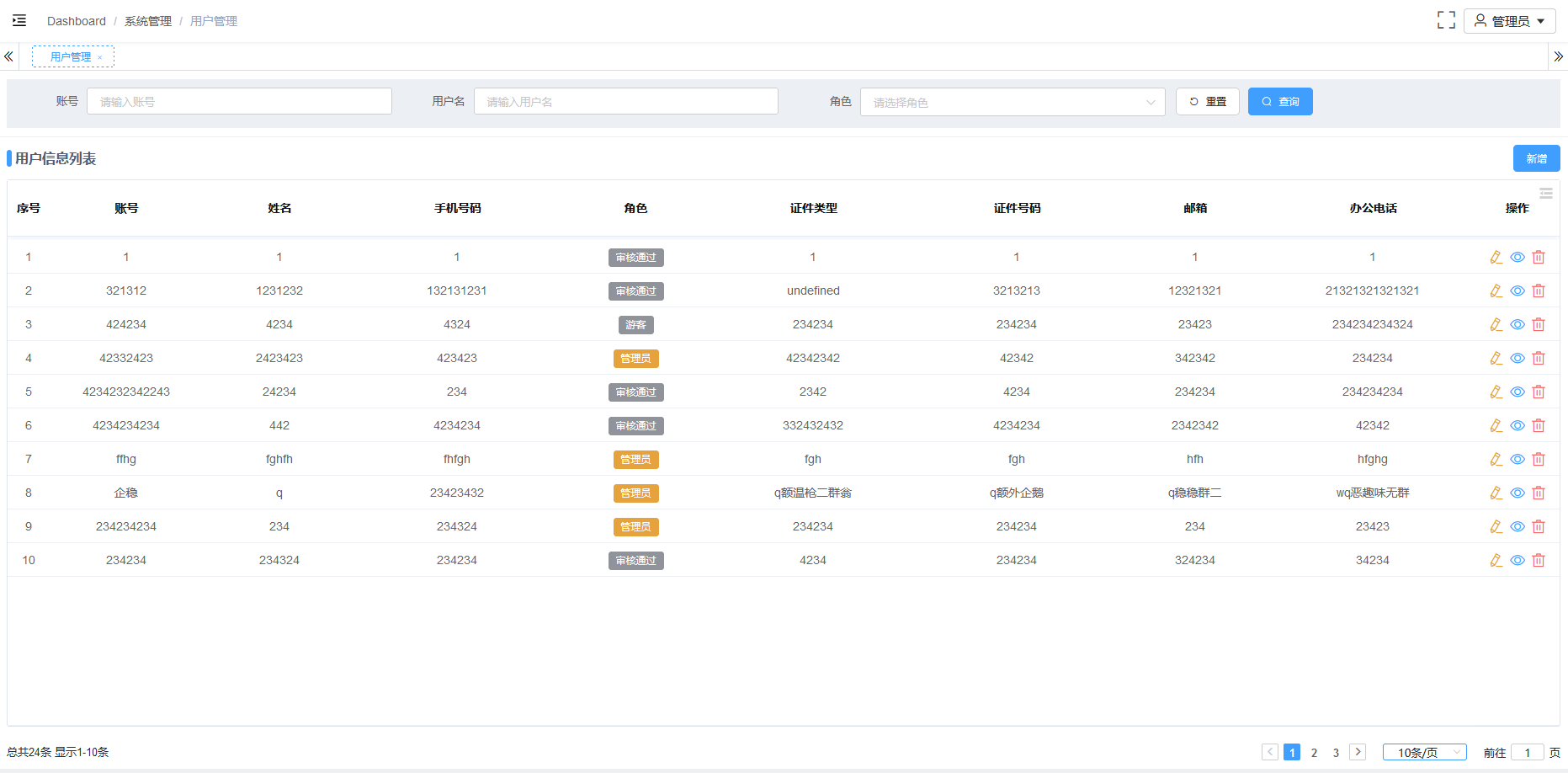
Element多级表格合并处理
全面了解阿里云OSS使用方法
MySQL为什么存在的表显示doesn‘t exist?
Linux联网安装MySQL Server
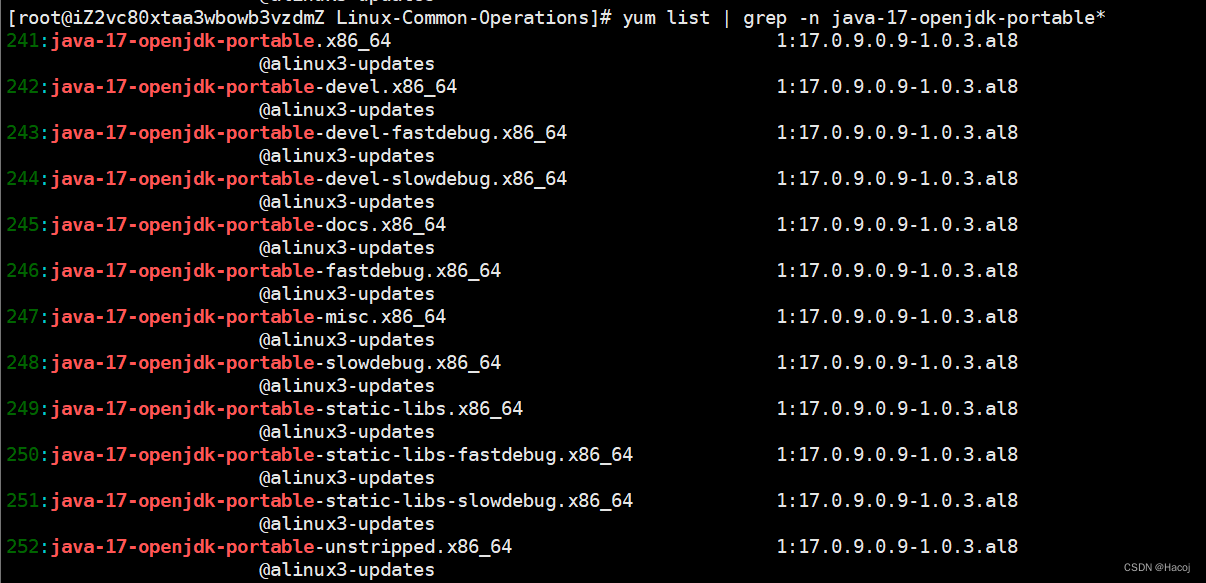
Linux安装Java
去除生产环境的debugger 和console
时间序列建模三部曲
RPM与YUM
R语言中Gibbs抽样的Bayesian简单线性回归
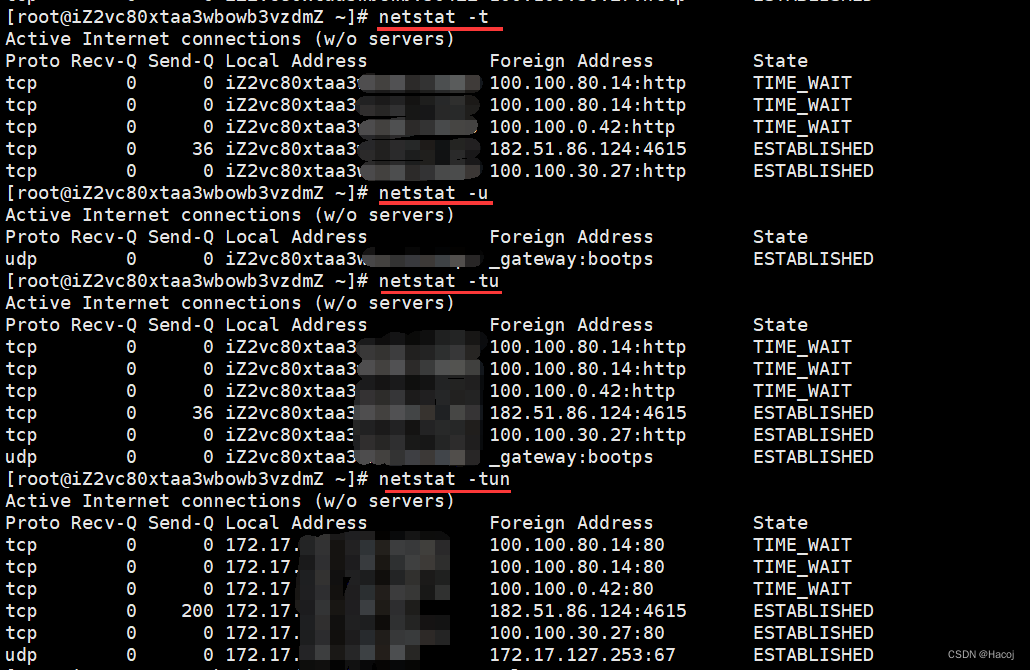
Linux网络状态查看与防火墙管理
node.js递归拼凑成树形结构
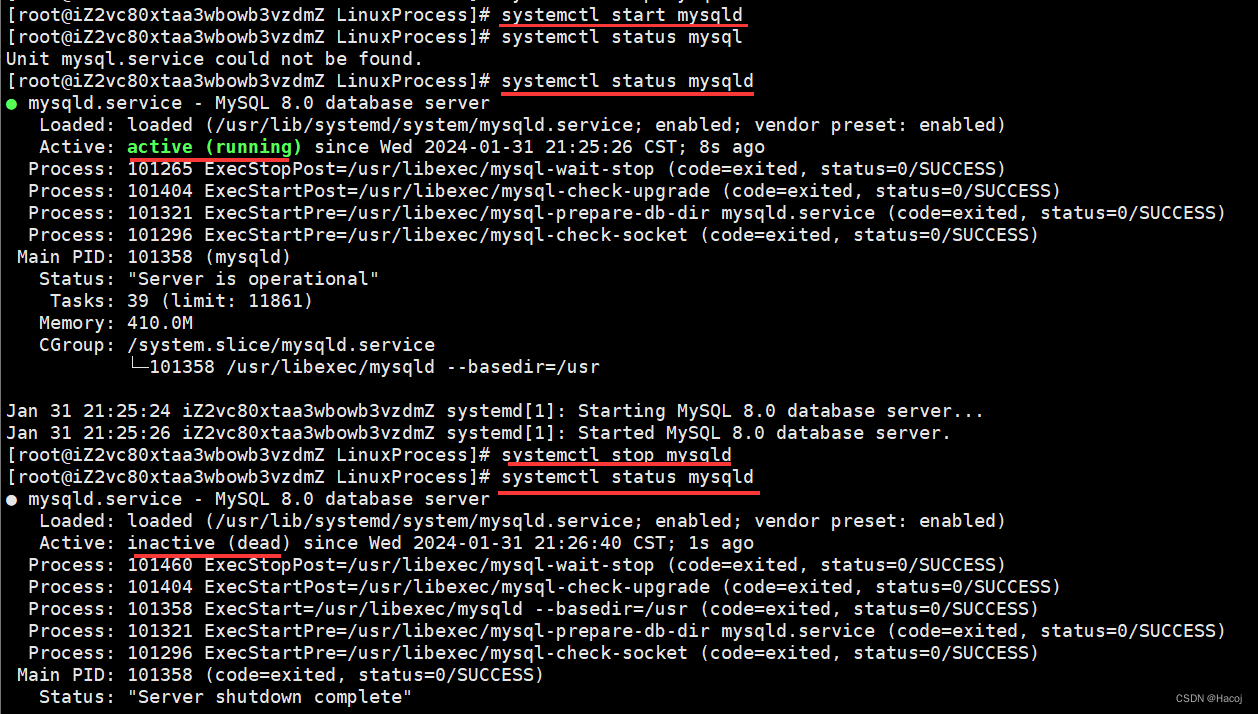
Linux服务详解
vue3.0 vite引入SVG iconfont
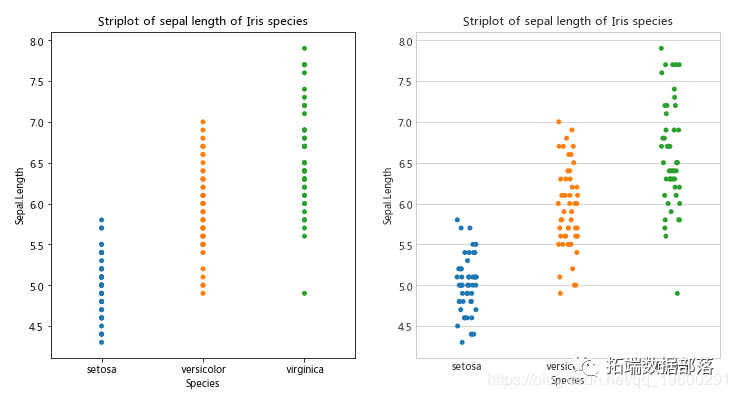
Python数据可视化-seaborn Iris鸢尾花数据
【leetcode】剑指 Offer II 105. 岛屿的最大面积-【深度优先DFS】
Linux进程详解
Linux定时任务调度--crontab与at
Linux管道符号和与管道符号常一起用的命令
【nodejs进阶之旅(2)】:使用koa2+mysql 实现列表数据分页
CTF中的一些做题姿势
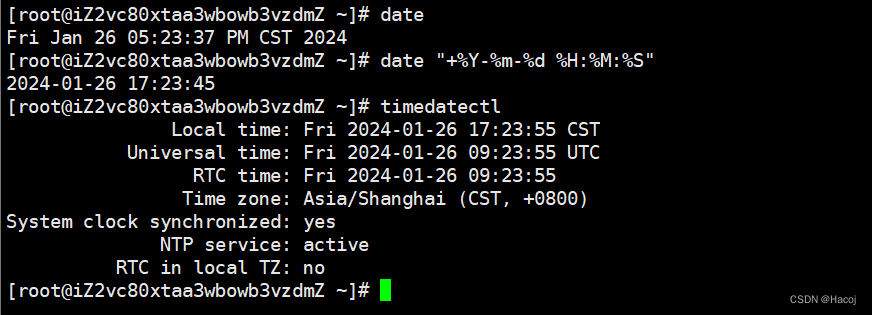
Linux常用指令-date,cal,histroy,find
Linux压缩&解压缩
Linux文件常用操作
linux安装pm2全过程
Linux用户管理
vite+typescript从入门到实战(三)
matlab脉冲响应图的时域特征
R使用LASSO回归预测股票收益
php特性
Vim基础
Python时间序列选择波动率预测指数收益算法分析案例
vite+typescript从入门到实战(二)