数据分析工作每天要面对各种各样的数据,每种数据都有其特定的含义、使用范围和分析方法,同一个数据在不同环境下的意义也不一样,因此我们想要选择正确的分析方法,得出正确的结论,首先要明确分析目的,并准确理解当前的数据类型及含义。统计学中的变量指的是研究对象的特征,我们有时也称为属性,例如身高、性别等。每个变量都有变量值,变量值就是我们分析的内容,它是没有含义的,只是一个参与计算的数字,所以我们主要关注变量的类型,不同的变量类型有不同的分析方法。
变量主要是用来描述事物特征,那么按照描述的粗劣,有以下两种划分方法:
按基本描述划分
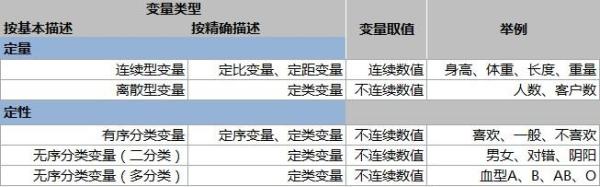
【定性变量】:也称为名称变量、品质变量、分类变量,总之就是描述事物特性的变量,目的是将事物区分成互不相容的不同组别,变量值多为文字或符号,在分析时,需要转化为特定含义的数字。
定性变量可以再细分为:
有序分类变量:描述事物等级或顺序,变量值可以是数值型或字符型,可以进而比较优劣,如喜欢的程度:很喜欢、一般、不喜欢
无序分类变量:取值之间没有顺序差别,仅做分类,又可分为二分类变量和多分类变量 二分类变量是指将全部数据分成两个类别,如男、女,对、错,阴、阳等,二分类变量是一种特殊的分类变量,有其特有的分析方法。 多分类变量是指两个以上类别,如血型分为A、B、AB、O
【定量变量】:也称为数值型变量,是描述事物数字信息的变量,变量值就是数字,如长度、重量、产量、人口、速度和温度。
定量变量可以再细分
连续型变量:在一定区间内可以任意取值,其数值是连续不断的,相邻两个数值可作无限分割,即可取无限个数值。如身高、绳子的长度等。
离散型变量:值只能用自然数或整数单位计算,其数值是间断的,相邻两个数值之间不再有其他数值,这种变量的取值一般使用计数方法取得。
按照精确描述划分
【定类变量】
测量事物类别或属性,各类支架没有顺序或等级,实际上也就是上面说的无序分类变量,所包含的数据信息很少,只能计算频数和频率,是最低层次的一种变量
【定序变量】
测量事物之间的等级或顺序,就是上述的有序分类变量,由于它的变量值可以是数值型或字符型,并且可以反映等级之间的优劣,除了可以计算频数和频率之外,还可以计算累计频率,因此数据包含的信息多于定类变量。
【定距变量】
测量事物的类别或顺序之间的间距,它不但具有定类和定序变量的特点,还能计算类别之间的差距,可以进行加减运算,数据包含的信息高于前两种
【定比变量】 测量事物类别比值,和定距变量相比,它不但可以进行加减运算,还可以进行乘除运算,包含的数据信息最多,是最高级的变量。
上面这四种变量可以从浅到深精确的描述事物,四种变量级别从低到高,高层次变量可以向低层次转化,代价是损失部分数据信息,但是低层次变量无法向高层次转化,这会得出错误结果。
按照变量的取值划分
前面两种分类方法都是从变量对事物的描述角度出发进行分类,一旦对事物描述确定下来,那么变量的取值也就相应确定下来了,比如定性变量的取值只能是某属性下的计数,比如人数、客户数等,因此只能取特定的值,数值是离散的。而定量变量可以取某属性下的任意值,变量值即可连续也可离散,比如身高、体重、销售额等。连续型数值和离散型数值的分析方法是不同的,因此从统计学角度,又经常划分为连续型变量和定性变量(分类变量)
关于变量的类型及取值方法,可以归纳为下表
本文作者:佚名
来源:51CTO