2、界面的视觉交互,是获取信息的主入口

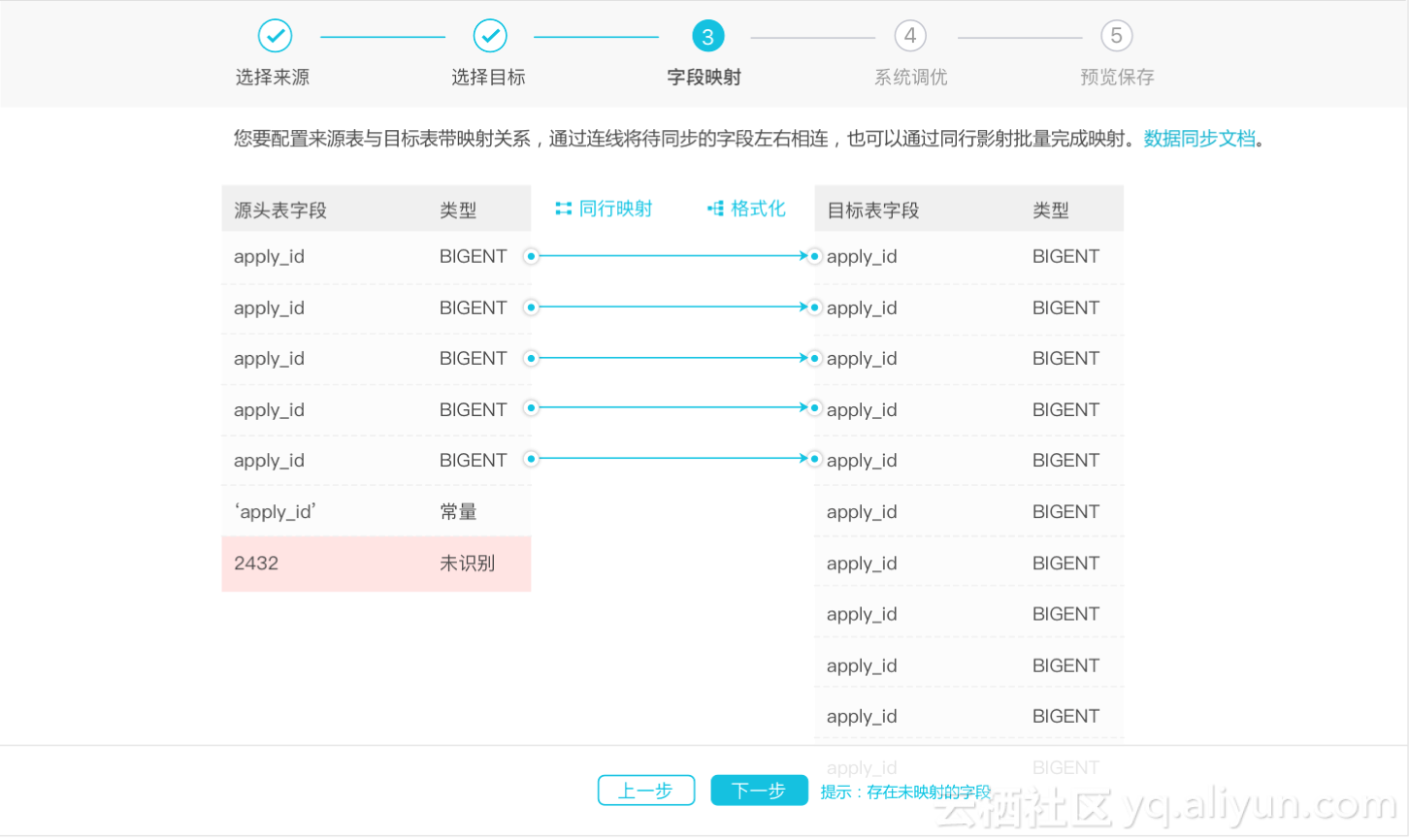
3、依据用户的使用场景,字段映射忽略的源端与目的端的字段大小写,提高效率
4、容易出错的地方给予明显提示:如新增的字段格式未识别,映射关系没有连线的情况
5、 一键建表后,自动帮用户选择已建好的的表,提高工作效率
6、针对常发的找不到数据集成的情况,在数据开发套件首页,增加数据集成的入口
7、运行日志,增加右键复制功能
文档在使用中做为问题量化的重灾区,必不可少。
针对网络问题,将用户的数据源划分为阿里云产品数据源、ECS自建数据源、本地自建的有公网IP的数据源、本地自建的无公网IP的数据源,分别提供不同的数据同步策略,特别是针对本地IDC机房数据上云:
1、提供安全加密的agent同步方案;
2、针对用户的大批量同步需求,提供批量的任务配置、管理,一键化同步过程,提升用户同步数据的效率;
3、数据集成升级下一代,将会和Dataworks(数据工场)的数据地图产品紧密结合,不仅提供数据的物理移动,也提供元数据的同步,同步的元数据展现在数据地图之上,方便用户先盘点、了解数据,再进一步决定移动哪些物理数据;
4、数据集成将新增客户端App、html网站日志数据一键采集至用户自己的大数据中心,用户可以基于这部分日志数据,与用户的其他数据结合进行商业分析。
以上两大部分内容正是产品团队&用户体验团队通过用户反馈梳理出来。进行用户走访,与用户进行深入沟通交流,整理出的上百条产品建议,以此进行了一系列的优化,通过产品界面引导,文档说明,以及在数据源文档中增加通过数据集成导入导出的说明,极大的方便了用户进入最佳实践,触达用户的效率提升,进而提升了用户使用数据集成产品的效率。
但以上问题优化后的结果,是否能达到用户的满意,真的符合用户的使用场景?这就需要用户一起参与其中进行验证。也更希望用户能在使用后,把相关的使用体验通过聆听平台提交上来,以便于产品进行更加符合用户使用场景的优化。
同时我们希望这不只是一段文字的描述。我们更希望有场景描述,相关操作流程,操作截图,或者是操作视频上传,更加详细的展示相关信息。
如果您也想与其它客户一起交流相关使用经验,我们也特地为大家建立了数据集成交流钉钉群,可随时与其它小伙伴交流与分享经验,说不定还能找到志同道合的人。