这些知名公司使用推荐提供情境化的、有相关性的用户体验,以提高转化率和用户满意度。这些建议原来一般由每天晚上、每周或每月生成新推荐的批处理作业计算提供。
然而对于某些类型的推荐,响应时间有必要比批量处理作业所需的时间更短,比如为消费者提供基于地理位置的推荐。比如电影推荐系统,若用户先前看过动 作片,但现在要找一部喜剧片,批量推荐很可能会给出更多动作片,而不是最相关的喜剧片。本文将会介绍如何使用Kiji框架,它是一个用来构建大数据应用和 实时推荐系统的开源框架。
Kiji,以实体为中心数据和360度视角
要构建实时推荐系统,首先需要一个能存储360视角客户的系统。此外,我们需要具备迅速获取与指定用户相关数据的能力,以便在用户与网站和移动应用交互时做出推荐。 Kiji是一个构建实时应用的模块化开源框架,它收集,存储和分析这类数据。
一般情况下,一个360度视图所需的数据可以被称为以实体为中心的数据。一个实体可以是任意数量的东西,比如客户、用户、帐户,或者POS系统或移动设备之类更抽象的东西。
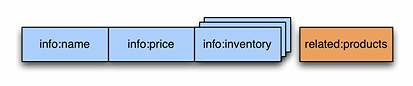
一个以实体为中心的存储系统要能在一行数据中存储与某个特定实体有关的一切信息。这对传统的关系型数据库来说是个挑战,因为这些信息可能既有状态型 数据(如姓名,电子邮件地址等)又有事件流(如点击)。传统的系统需要把这些数据存放在多张表中,处理时再把这些表联接起来,这使得它很难做到实时处理。 为了解决这个问题,Kiji用了Apache HBase,它在四个维度 – 行、列族、列标识和时间戳-存储数据。借助时间戳维度和HBase存储多个版本Cell的能力,Kiji能够存储有更多状态的缓慢变化的事件流数据。
 HBase 是Apache Hadoop使用的一个键-值存储系统,它构建在HDFS之上,为大数据解决方案提供了必需的可扩展性。在HBase上开发应用程序面临的巨大挑战是,它 要求所有进出系统的数据都是字节数组。为了解决这个问题,Kiji的最终核心组件是Apache Avro,被Kiji用来存储易于处理的数据类型,如标准字符串和整数,以及由用户定义的更复杂的数据类型。 读写数据时,Kiji为应用程序做必要的序列化和解序列化处理。
HBase 是Apache Hadoop使用的一个键-值存储系统,它构建在HDFS之上,为大数据解决方案提供了必需的可扩展性。在HBase上开发应用程序面临的巨大挑战是,它 要求所有进出系统的数据都是字节数组。为了解决这个问题,Kiji的最终核心组件是Apache Avro,被Kiji用来存储易于处理的数据类型,如标准字符串和整数,以及由用户定义的更复杂的数据类型。 读写数据时,Kiji为应用程序做必要的序列化和解序列化处理。
开发用在实时中的模型
Kiji为开发模型提供了两套API,Java和Scala,两套API都支持批量和实时组件。如此划分的目的是将模型执行划分为不同阶段。批量阶 段是训练阶段,是一个典型的学习过程,在该过程中,将使用完整的数据集来训练模型。该阶段的输出可能是线性分类器的参数,或者聚类算法的群集位置,或在协 同过滤系统中相互关联条目的相似性矩阵。实时阶段被称为评分阶段,取得经过训练的模型,并将它与实体数据相结合产生衍生信息。关键是这些衍生数据被当作一 等公民,也就是说它可以存回到实体所在的行中,用于推荐,或作为后续计算的输入。
Java API被称为KijiMR, 而Scala API构成了KijiExpress工具的核心。 KijiExpress利用Scalding库提供API来构建复杂的MapReduce工作流,同时避免了大量Java冗余代码,以及串联 MapReduce作业所必需的任务调度和协作。
个体与总体
之所以要划分出批量训练和实时评分两个阶段,是因为Kiji观察到总体趋势变化缓慢,而个体趋势的变化迅速。
比如一个包含上千万次购买记录的用户总体数据集。多一次购买不太可能对总体趋势的好恶造成重大影响。但对于一个只有10次购买记录的特定用户而言, 第11次购买将对系统判断用户兴趣产生巨大影响。鉴于这种主张,应用程序只需在收集到足以影响总体趋势的数据时再重新训练它的模型。但对于特定用户而言, 我们可以通过实时响应用户的行为来改善推荐的相关性。
实时给模型评分
为了做到实时评分,KijiScoring模块提供了一个惰性计算系统,应用程序可以只为经常与其交互的活跃用户生成最新推荐。通过惰性计 算,Kiji应用程序不必为那些不经常光顾或再没回来过的用户生成推荐。这还有些额外的好处,Kiji可以在推荐时考虑像移动设备的位置之类的情境信息。
KijiScoring的主要组件叫Freshener。Freshener实际上是另外两个Kiji组件的组 合:ScoringFunctions和FreshnessPolicies。正如前面提到的,一个模型包括训练和评分两个阶段。 ScoringFunction是一段代码,描述了如何把经过训练的模型和单一实体的数据组合起来产生一个分数或建议。FreshnessPolicy定 义数据变得陈旧或过时的时间。比如说,普通的FreshnessPolicy会指出超过一个小时后数据就过期了。更复杂的策略可能会在实体经历过一定次数 的事件后将其标记为过期,比如点击或产品访问等事件。最后,ScoringFunction和FreshnessPolicy被附着在Kiji表中特定的 列上,在必要时被触发来刷新数据。
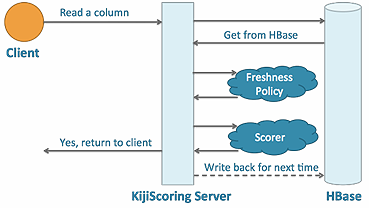 进 行实时评分的应用程序中包含一个服务器层,被称为KijiScoring服务器,它是负责刷新陈旧数据的执行层。当用户与应用程序交互时,请求将被传递到 KijiScoring服务器层,它直接与HBase集群通信。KijiScoring服务器将会请求数据,并且在获取到数据后根据 FreshnessPolicy检查数据是否是最新的。如果是最新的数据,它将其直接返回给客户端。如果是过时的数据, KijiScoring服务器将为发出请求的用户运行指定的ScoringFunction。你需要掌握的要点是它只为发出请求的用户刷新数据或推荐;而 不是执行批处理操作,刷新所有用户的数据。这样Kiji就可以只是做那些有必要做的工作。数据刷新完成后会被返回给用户,同时写回HBase以备后用。
进 行实时评分的应用程序中包含一个服务器层,被称为KijiScoring服务器,它是负责刷新陈旧数据的执行层。当用户与应用程序交互时,请求将被传递到 KijiScoring服务器层,它直接与HBase集群通信。KijiScoring服务器将会请求数据,并且在获取到数据后根据 FreshnessPolicy检查数据是否是最新的。如果是最新的数据,它将其直接返回给客户端。如果是过时的数据, KijiScoring服务器将为发出请求的用户运行指定的ScoringFunction。你需要掌握的要点是它只为发出请求的用户刷新数据或推荐;而 不是执行批处理操作,刷新所有用户的数据。这样Kiji就可以只是做那些有必要做的工作。数据刷新完成后会被返回给用户,同时写回HBase以备后用。
一个典型的Kiji应用程序将包括一定数量的KijiScoring服务器,它们是可以向外扩展的无状态Java进程,并能够运行使用单一实体的数 据作为输入的ScoringFunction。Kiji应用程序通过KijiScoring服务器过滤客户端请求,由它决定数据是否是最新的。若有必要, 它会在把所有推荐传回客户端之前运行ScoringFunction进行刷新,并将重算后的数据写到HBase中,以备后用。
将模型部署到生产系统中
能够轻松迭代其底层的预测模型是实时推荐系统的一个重要目标,避免因为要将新的或改进过的模型部署到生产环境而停掉应用程序。Kiji为此提供了 Kiji模型库,它结合了描述模型以及用来训练模型和给模型评分的代码如何执行的元数据。KijiScoring服务器需要知道什么样的列访问会触发刷 新,要用的FreshnessPolicy,以及将在用户数据上执行的ScoringFunction,以及所有经过训练的模型的位置,或给模型评分所必 需的外部数据。元数据也存在一个Kiji系统表中,只是另一种最底层的HBase表。此外,模型库在受管的Maven库中为已注册的模型存储代码工件。 KijiScoring服务器为新登记或未登记模型定期轮询模型库,按需加载或卸载代码。
整合到一起
使用协同过滤是一种非常常用的推荐提供方式。协同过滤算法通常会建立一个大型的相似矩阵,用来存放一个产品跟产品目录中其它产品的关联信息。矩阵中的每一行代表一个产品Pi,每一列代表另一种产品Pj。(Pi,Pj)中的值就是两个产品之间的相似度。
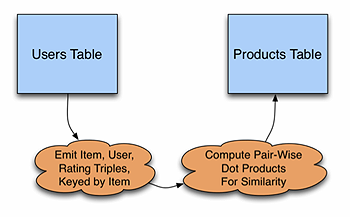 在 Kiji中,相似矩阵是通过批量训练过程计算出来的,然后被存储在文件或Kiji表中。相似矩阵中的每一行都会被存放在Kiji产品表中某一行的单独列 中。在实践中,这一列可能会变得非常大,因为其中放的是目录中所有产品的清单和相似性。通常情况下,批处理作业也会挑出相似度最高的条目存到表中。
在 Kiji中,相似矩阵是通过批量训练过程计算出来的,然后被存储在文件或Kiji表中。相似矩阵中的每一行都会被存放在Kiji产品表中某一行的单独列 中。在实践中,这一列可能会变得非常大,因为其中放的是目录中所有产品的清单和相似性。通常情况下,批处理作业也会挑出相似度最高的条目存到表中。
 相似矩阵在评分时是通过KeyValueStore API访问的,这个API可以访问外部数据。对于无法完全放在内存中的大型矩阵,可以把它们放在分布式的表中,这样应用程序可以只请求计算必需的数据,从而大幅降低对内存的需求。.
相似矩阵在评分时是通过KeyValueStore API访问的,这个API可以访问外部数据。对于无法完全放在内存中的大型矩阵,可以把它们放在分布式的表中,这样应用程序可以只请求计算必需的数据,从而大幅降低对内存的需求。.
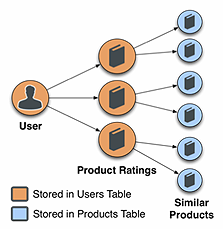
既然我们在评分阶段之前已经做了很多繁重的工作,那么评分自然成了一种相当简单的操作。如果我们想基于被查看的条目展示推荐信息,一个通用的评分函数只是从产品表中查找相关产品,并显示它们。
将该过程再推进一点并对结果做个性化处理是一个相对简单的任务。在个性化系统中,评分函数将会取得用户最近对产品的评级,并使用 KeyValueStore API查找与用户评价过的产品相似的产品。结合评级和存储在产品表中的产品相似度,应用程序可以预测用户给相关条目下的评级,并将预测评级最高的产品推荐 给用户。通过限制所用评级和所有已评级的相似产品的数量,系统在用户与应用程序进行交互时可以很轻松地处理上述操作。
结论
在本文中,我们可以了解到如何用Kiji开发一个可以实时刷新推荐的推荐系统。利用HBase进行低延迟处理,用Avro存储复杂的数据类型,使用MapReduce和Scalding处理数据,应用程序能够在实时情境中给用户提供相关推荐。
本文作者:Jon Natkins
来源:51CTO