不仅微博,在twitter中也存在大批的“僵尸粉”。Twitter中的“僵尸粉”不仅能够在无人干预下撰写和和发布推文的程序,并且所产生的推文相当复杂。如何识别这批“僵尸粉”或者说“机器人粉丝”?下面我们将通过Python的Pandas库、自然语言处理学习NLTK和scikit-learn创建分类器对Twitter机器人进行识别。
在本文中,我想要讨论一个互联网现象:机器人,特别是Twitter机器人。
我之所以一直关注Twitter机器人主要是因为它们有趣又好玩,另外也因为Twitter提供了丰富而全面的API,让用户可以访问到Twitter平台信息并了解它们是如何运作的。简而言之,这让Python强大的数据分析能力得到了充分地展示,但也暴露了它相对薄弱的环节。
对于那些不熟悉Twitter的人, 我们先简单介绍一下。Twitter是一个社交媒体平台,在该平台上用户可以发布140字以内的恶搞笑话,称之为“推文”。Twitter根本上区别于其它的社交媒体是因为推文默认是公开的,并且在Twitter上互相关注的人实际上不一定彼此认识。你可以认为Twitter不单单是个人信息流,更像是一个想法交易市场,流通的货币则是粉丝和推文转发。
Twitter另外一个显著的特点是它自身内容的“嵌入式能力”(见上图的搞笑例子)。如今,将推文作为新媒体的一部分是稀疏平常的一件事。主要是因为Twitter开放式的API,这些API能让开发者通过程序来发推文并且将时间轴视图化。但是,开放式的API让Twitter在互联网广泛传播,也对一些不受欢迎的用户开放了门户,例如:机器人。
Twitter机器人是能够在无人干预下撰写和和发布推文的程序,并且所产生的推文相当复杂。其中一些机器人相对不活跃,只是用来增加粉丝和收藏推文的。而另一些会借助复杂的算法来创建具有说服力的推文。所有的Twitter机器人都可能变得让人讨厌,因为它们的出现破坏了Twitter分析的可信度和商业价值,最终甚至会触及底线。
那么Twitter能对这些机器人做些什么呢?首先,要做的是去识别它们,以下是我的方法。
创建标签
核心目标是创建一个分类器来识别哪些账号是属于Twitter机器人的,我是通过监督学习来实现的。“监督”意味着我们需要已有标注的样本数据。例如,在最开始的时候,我们需要知道哪些账号属于机器人,哪些账号属于人类。在过去的研究中,这个费力不讨好的任务已经被研究生的使用(和滥用)完成了。例如:Jajodia 等人通过手动检测账号,并且运用Twitter版本的图灵检测来判断一个账号是否属于机器人,判断推文是否由机器人发布的。问题是我已经不再是个研究生了并且时间宝贵(开玩笑)。我解决了这个问题多亏我的朋友兼同事Jim Vallandingham 提出的绝妙建议,他向我推荐了fiverr,一个花5美元就能获取各类奇特服务的网站。
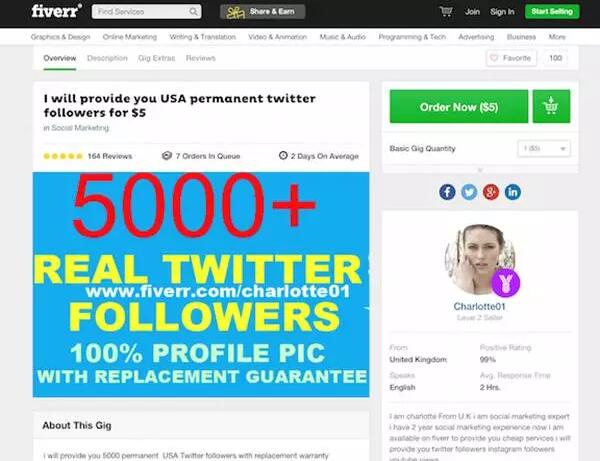
花了5美元,等待24小时之后,我有了5500个新粉丝。因为我知道在机器人关注之前,我的粉丝都有哪些,所以我可以有效地识别哪些是人类,哪些是一夜激增的机器人粉丝。
创建特征
由于Twitter有丰富的REST API(REST指一组架构约束条件和原则,满足约束条件和原则的应用程序设计——译者注),创建特征集是几乎不违反服务条约的行为。我使用Python-twitter模型去查询两个终端指标:GET users/lookup(获取用户信息)和 GET statuses/user_timeline(获取用户状态、时间轴信息)。获取用户信息的终端会返回JSON文本,这些文本中包含了你所希望得到的用户账号信息。例如:用户是否使用了默认的模板配置,关注者/被关注者的数量,发布推文的数量。从获取的用户时间轴信息中,我抓取了数据集中每个用户最新的200条推文。
问题是,Twitter官方不允许你直接大量地收集你所想要的数据。Twitter限制了API的调用频率,这样意味着你只能在需求范围内获取少量的样本数据进行分析,因此,我使用了以下美妙的方法(blow_chunks)来获取数据:
#不要超出API的限制

如果查询的长度大于所允许的最大值,那么将查询分块。调用生成器.next()方式来抓取第一个块并将此需求发往API。然后暂停获取数据,两个数据请求需要间隔16分钟。如果所有的块都发出了,那么生成器将会停止工作并且终止循环。
机器人是怪物
通过快速地清理和整理数据,你会很快发现不正常的数据。通常情况下,机器人的关注量是1400,而人类的关注量是500。机器人的粉丝分布具有很大的差异性,而人类的粉丝分布差异性较小。有些人的人气很高,有一些却没那么高,大多数人是介于两者之间。相反,这些机器人的人气非常低,平均只有28个粉丝。
将推文变成数据
当然,这些机器人在账号信息层面上看起来很奇怪,但是也有很多人的人气很低,而且账号中几乎空荡荡的,只有一张头像。那么他们发布的推文是怎样的呢?为了将推文数据加入到分类器中,一个账号的推文信息需要被汇总成一行数据。有一种摘要度量方式建立在词汇多样性之上,就是每个特定词汇数量占文档总词汇数量的比例。词汇多样性的范围是从0到1,其中0代表这个文档中没有任何词汇,1代表该文档中所有词都只出现过一次。可以将词汇多样性作为词汇复杂性的度量方法。
我用Pandas 来快速优雅地运用归纳函数,例如词汇多样性,对推文进行处理。首先,我把每个用户的所有推文放进一个文档,并进行标记,这样我会得到一个词汇列表。然后,我再利用NLTK(自然语言处理技术)移除所有标点符合和间隔词。
通过Pandas在数据集上使用自定义函数是极其方便的。利用groupby,我通过账户名将推文分组,并且在这些分组推文中应用词汇多样性函数。我钟爱这个语法的简洁和灵活,可以将任何类别的数据分组并且适用于自定义的归纳函数。举个例子,我可以根据地理位置或者性别分类,并且仅仅根据分组的变量,计算所有组的词汇多样性。

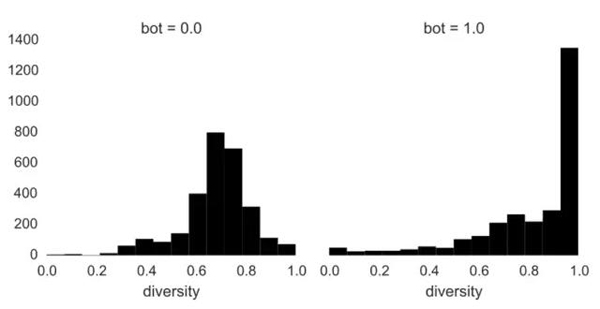
同样的,这些机器人看上去很怪异。人类用户有着一个美得像教科书一般的正态分布,其中大部分的词汇多样性比例集中在0.7。而机器人的却很极端化,词汇多样性接近于1。语义差异性为1,这意味着每个词在文档中都是独特的,也就是说机器人要么几乎不发推文,要么只是发随机文字。
建模
我利用stickit-learn,Python中最重要的机器学习模块,进行建模和校验。我的分析计划差不多是这样的,因为我主要关注预测精准度,为什么不试试一些分类方法来看看哪个更好呢?Scikit-learn的一个强项是简洁,同时在构建模型与管道时与API兼容,这样易于测试一些模型。
我试了3个分类器,分别是朴素贝叶斯、逻辑回归和随机森林分类器。可以看到这三种分类方法的语法是一样的。在第一行中,我拟合分类器,提供从训练集和标签为y的数据中得到的特征。然后,简单地通过将来自测试集的特征传入模型来预测,并且从分类报告查看精确度。

毫无疑问,随机森林表现得最好,整体精度为0.9,而朴素贝叶斯的是0.84,逻辑回归的是0.87。令人惊讶的是,利用现有的分类器,我们识别机器人的准确率可以达到90%,但是我们是否可以做得更好?答案是:可以。事实上,利用GridSearchCV可以非常容易地调试分类器。GridSearchCV采用了一种分类方法和一系列的参数设置进行测试。其中,这一系列参数是一个键入了该模型配置参数的字典。GridSearchCV最好的一点是可以像对待刚才我们看到的分类方法一样地对待它。也就是说,我们可以使用.fit()和.predict()函数。

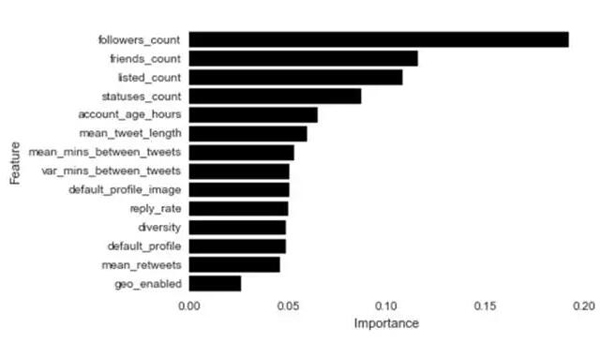
啊哈,更加精确了!简单的调试步骤产生了一个新格局,预测的准确率提高了2%。为调试过的随机森林检查变量重要性策略产生了一些惊喜。朋友数量和粉丝数量是机器人识别中最重要的变量。
但是,我们需要更好的工具来开发迭代模型
Scikit-learn还有很大的提升空间,特别是生成模型诊断和模型比较应用上的功能性。一个说明我的意思的例子是,我想带你走进另一个世界,那里不用Python,而是R语言。那里也没有scikit-learn,只有caret(Classification and Regression Training,是为了解决分类和回归问题的数据训练而创建的一个综合工具包——译者注)。让我告诉你一些caret的,在scikit-learn里可以被复制的强项。
以下是confusionMatrix函数的输出结果,与scikit-learn分类报告的概念等价。你会注意到有关comfusionMatrix函数输出的准确度报告的深度。有混淆矩阵(confusion matrix)和大量将混淆矩阵作为输入的准确度测量维度。大多数时候,你也许只会使用到一个或者两个测量维度,但是如果它们都可用是最好的,这样,可以在你所处的环境下使用效果最好的,而无需增加额外代码。

Caret最大的一个优势是提取推理模型诊断的能力,而这在scikit-learn中是看似不可能完成的。以拟合一个回归方法为例:你自然想看看回归系数,样本满意度,P值和拟合优度。即使你仅仅对预测准确性感兴趣,理解模型的原理和知道模型是否满足假设条件也是有用的。为了在Python中复制这样的输出,需要在与statsmodels类似的地方改装模型,这样会造成建模过程的浪费和繁琐。

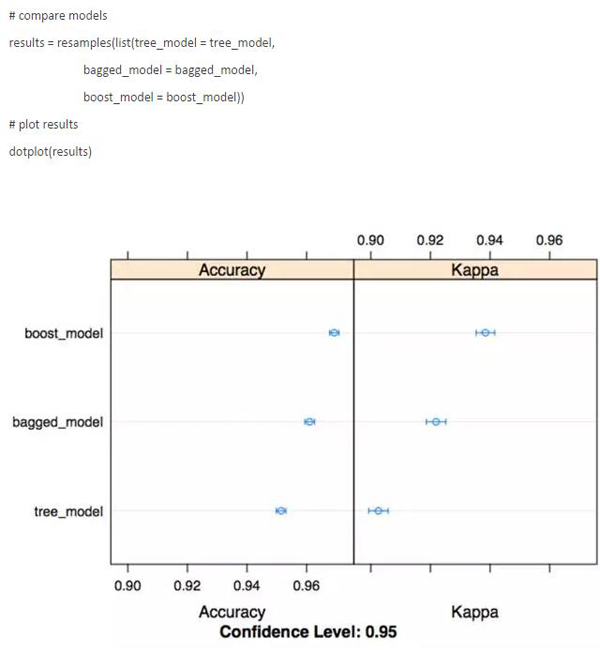
但是,我认为R语言中caret包最大的特点是能够容易地比较不同的模型。使用 resamples 函数,可以很快地生成可视化效果来比较我选择的指标模型的性能。这种类型的效用函数在建模过程中是超级有用的,也让你在不想花费大量时间来制作图的终稿的时候可以就早期的结果进行交流。
对于我而言,这些功能产生了所有的差异,这也是R语言仍然是我建模首选语言的主要原因。
本文作者:rin Shellman
来源:51CTO