在众多的人工智能应用中,智能语音交互是大众能够最近距离接触到的一个。从几年前的手机语音助手,到近年来的互联网汽车、智能音箱、电视、IoT设备等,语音交互正以前所未有的深度和广度,融入雨后春笋般涌现的各种智能设备中。国内外各大互联网公司和众多初创企业都瞄准了智能语音交互这一重要领域,并视其为下一个最重要的流量入口和服务分发途径。不仅是在这些新兴领域,智能语音交互还逐步渗透到传统行业内,助力传统服务智能化。本报告将简要介绍智能语音交互的技术现状,以及阿里巴巴在这一领域的已有研究探索和未来展望。
智能语音交互
智能语音交互,是阿里巴巴iDST智能语音交互团队的核心智能产品体系,将人工智能、语音识别、语言理解、语音合成、人机交互、知识图谱、大数据深度学习、声纹识别等等无缝结合,专注于各类智能终端的能力供给,提供“能听、会说、懂你”的智能语音交互体验。

整个东西都是由阿里在自己的平台上,例如基于阿里云计算平台跟大规模弹性服务的平台上进行研发的。我们自己有比较独特的语音深度学习的声学技术,还有比较大规模的语言模型跟解码器技术。语音识别系统是无法为所有场景同时做好服务的,怎么能够在阿里云上做低成本的定制、低成本的服务,这是我们区别于其他单一语音提供商的。我们的产品在阿里内部跟外部都有一些具体的应用。
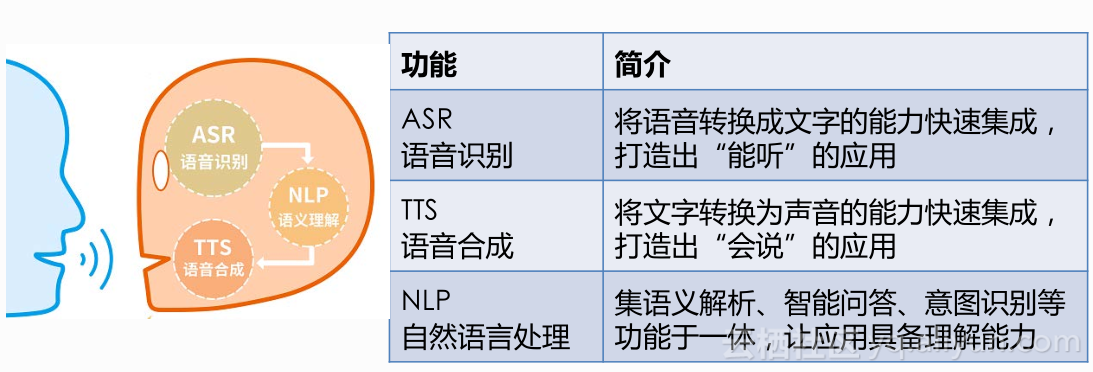
所谓智能语音交互,它不单是语音识别或者语音合成的技术问题,更多是“能听、会说、懂你”的智能人机交互体验,形成一个闭环。那么在这当中,最主要就是三个技术,能听就是语音识别,很多像手淘里面的语音搜索,把你说的话转化成为文字,单单说今天机器把语音转换成文字的过程,完全是听见但并没有听懂的过程,所以后面的人工智能再高一层次,怎么去做这种认知,那就涉及到自然语言处理技术了。但是在语音里面用自然语言技术跟通用的自然语言技术又略有区别,例如语言理解他们叫natural language understanding(NLU),我们现在在语音里面做的事情称为spoken language understanding (SLU),首先语音识别本身会产生错误,比如说有一字之差,或者同音不同字的情况会出现,那怎么能够在有语音识别错误的时候很好的来做理解,这就是做口语理解特有的东西。最后还有语音合成,怎么样让机器能够说话,怎么用技术使得它更自然,更像人的自然表达,能够表达出当时说话时候的情绪。
语音识别的核心组件
语音识别技术把语音转换成文字有一个最简单的精度度量,就是识别错误率,在中文里面我们通常计算它的字的识别错误率,当Character Error Rate和Word Error Rate降为零的时候,就是一字不差的准确识别了,通过这个指标我们不断的优化语音识别系统。

数学上来说写上公式如图,我们输入一连串的语音数据,因为语音跟图片不一样,语音是一个连续的信号,所以我们通常都不会识别一个字,都是连续的语音识别,所以你的输入会是一个时间序列,然后输出是一个文本序列。
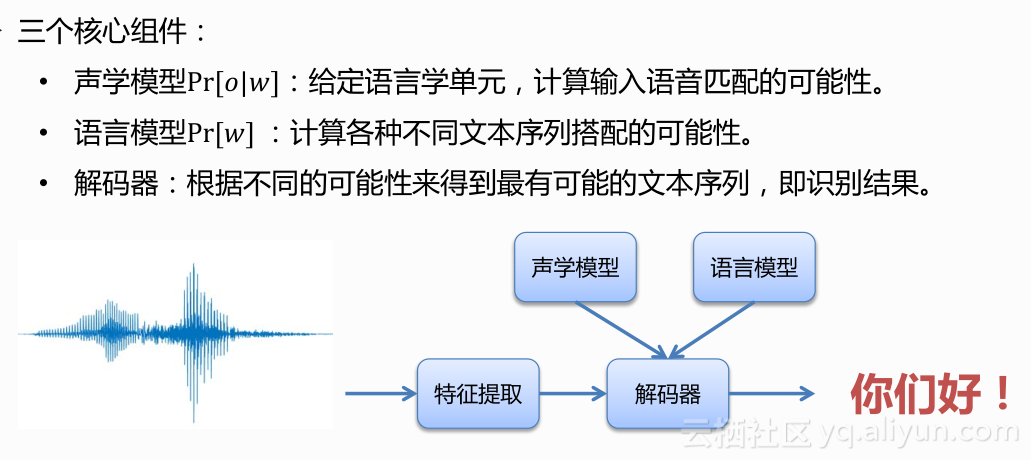
比如说我们用词来作为建模单元,那就有一个词序列。语音识别就是根据input,然后找出一个最大可能的词序列output,用公式写出来就可以转换成三项,声学模型、语言模型,还有在所有的词序列当中搜索出一个最大化概率的模块就叫做解码器。那分别是用做什么用呢?

你有一个语音的特征,通过声学模型就能把这个feature到底是a的概率多一些,还是e的概率多一些刻画出来。现在声学模型在历史上有非常多的数学模型在里面使用。目前最popular的模型就是一些深度学习deep learning 的deep models,就像图中所画,有一个时间信号,每一帧都有它的input feature,然后通过一些DNN或者更复杂的模型,得到声学模型的概率。

语言模型是说一个词序列到底概率多大,比如说可以去算我要去吃饭的概率,我要去洗澡的可能性,如果要去语音识别就不是一句人话,所以这个分就很低,我要去上班比吃饭更被人说的多一些,所以概率是0.4。这些东西可以通过大量的语料收集,通过语言模型对它进行表征,现在在语音识别里面仍然直接从你看到的语料当中把这些概率数出来。
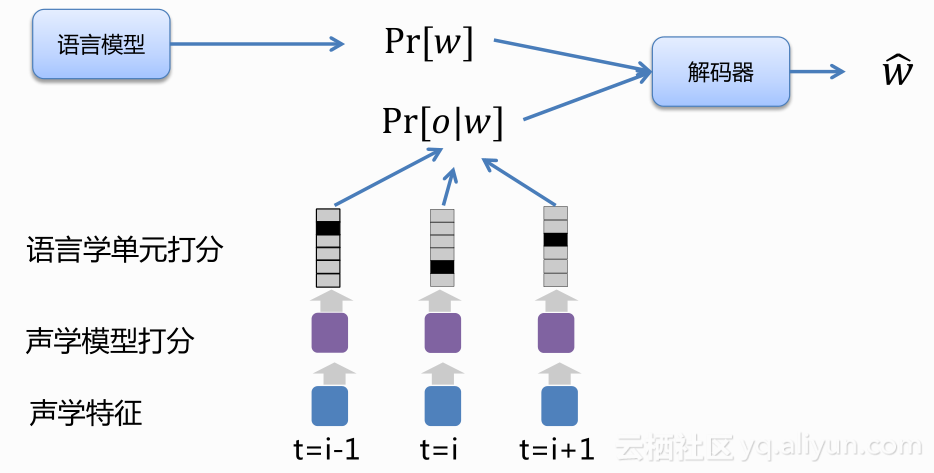
如果你去穷举所有的word sequence,运算量是巨大的,甚至是不可能的,怎么能够很高效的把你说的话能够解码出来,解码器现在还没有任何一个开源的解码器,可以跟真正的工业界的解码器比拟,所以这也是整个工业界做语音识别门槛比较高的原因之一,就是解码器技术还没有一个特别好用的工具被广泛的开源出来,这里面会有很多工作需要在大规模的问题当中去锤炼。
语音识别准确率
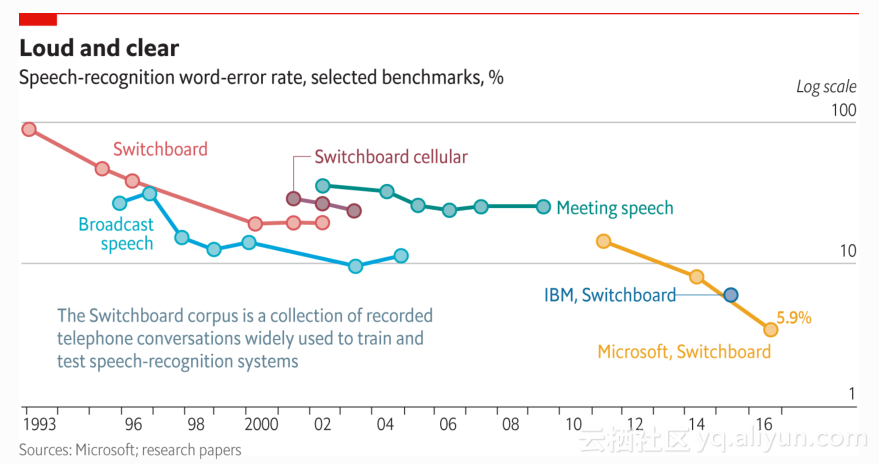
语音识别的准确率也是一个螺旋上升的过程,有的年代因为一些突破性的技术被提出,所以一下就会把错误率给降下来,有的年代一直没有什么好的技术突破,所以准确率是拉平的,图中是两个人打电话交谈的时候,怎么把两边人说的话转换成英文的word,这个录音就是在电话局的交换机地方录的,所以你会得到两个录的输入信号,两个人在交谈,所以这个任务就叫switchboard,错误率越低越好,1993年的时候错误率近乎是100%,那个年代无法做大词汇量的连续语音识别,2000年左右基本上能够做到20多的准确率,这条线连续的变成直线好多年,将近10年的时间没有特别好的技术提出来。
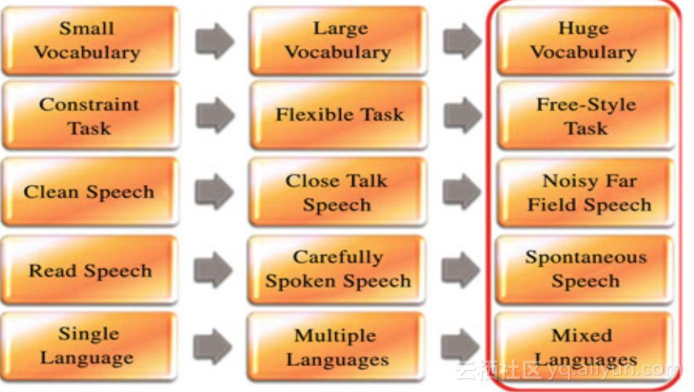
直到2010年代以后,deep learning技术被微软从学术界学过来,然后不同的研究组都开始关注它,然后DNN模型本身就带来了一个非常大的improvement,当年就从20几的错误率直接拉到了10几的错误率,这是非常大的进展,在微软最新的公布number,他们已经把任务从10几又拉到了5.9这样的程度,当然用了很多模型的combination,跟别的一些技术在一起,整个就是一部逐渐下降的历史。哪些上面有了进步呢?比如说以前的词汇量比较小,就是说能认识的词可能数千个,那现在可能是数十万到一百万个词汇量,以前是比较有限制的一些任务,现在基本上可以随便说,比较自然的讲话,语音识别系统都能够很好的来识别,一开始只能做比较干净的语音,现在我们基本上可以做比较正常的带有一定噪声的语音识别。最开始的时候必须像朗读一样,像老师讲课一样非常好的读出来,那现在可以做比较连续自由的语音。之前是单一语言,现在我们也可以做一些中英文混合的。
归结起来,技术的进步带来准确率的突飞猛进,把语音识别从一个实验室里面的技术,变成一个大众科技,我觉得总结下来有以下三点是最重要的:
- 第一点就是数据闭环。以前我们做语音识别,数据的获得是很不易,你要从街上拉人到录音棚里面去录,然后才能采集数据,但是现在有手机,有各种各样的便携式设备。我们的用户在手机淘宝语音搜索的时候,直接可以把这些数据收上来,一旦做过了标注以后,对语音识别本身的提升非常大。
- 第二点就是深度学习的进步。
- 第三点就是要有好的运算能力来支撑。
Switchboard才300小时的训练数据而已,后面有学术界的人给它扩充到了2000小时,现在工业界入门的门槛可能已经是2万小时了,这就是跟数据来源的更广泛、更易得很有关系。

我们拥有更大更复杂的模型,尤其是深度学习模型的引入,使得在传统年代到现在年代整个的准确率在不断的提升,错误率在不断的下降,在这里面阿里也有自己一些独特的技术,比如LC-BLSTM特别适合于做语音识别任务,阿里很早把这个模型推上线,而且现在大家用手机淘宝里面的语音搜索,云栖大会上所有演讲的实时字幕,这些都是用这个模型产出的语音识别结果。
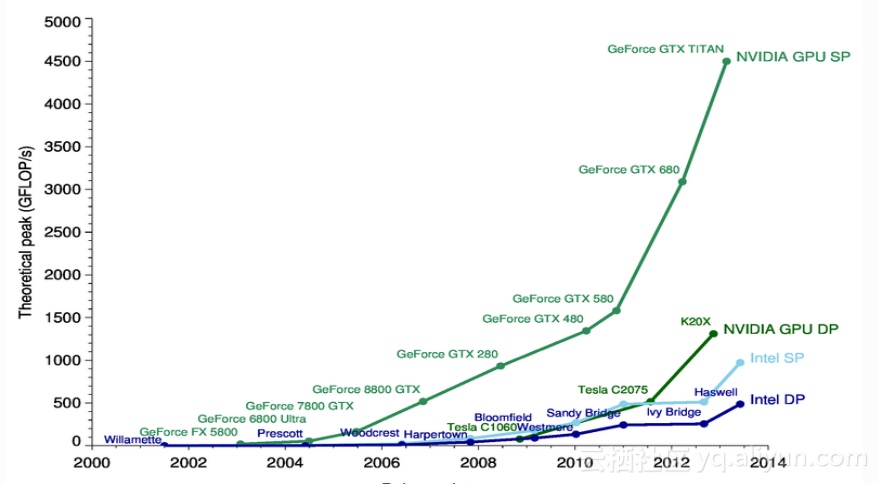
运算能力也发展的更强大,比如摩尔定律、GPU,对整个图像领域的deep learning有很大的助力,不管是语音识别还是合成,现在都是用相似的技术来做的。
有了这些东西以后才能够加快迭代速度,迭代时间直接关系到产品、业务的迭代周期,关系到提高业务性能和扩张产品的时间周期。怎么能够快速提升产品的体验效果,尤其在语音识别上,首先用自己收集的数据,不管你从哪里去找,然后有第一版的模型上线,然后迅速的根据数据闭环,用户在不停的使用,有live数据源源不断的上来,然后马上进行标注,标注完了以后就要有一个部分高效的learning,不管是算法也包括机器本身,怎么在一个分布式的大规模GPU的cluster里面把你的model迅速的建出来,然后马上去换掉线上模型,通过这个过程,你会发现一开始语音识别准确率的提升会是非常明显的,对于图像别的领域也是一样,就是怎么从你的实验室数据进化到用真实数据,然后迅速迭代模型做替换。
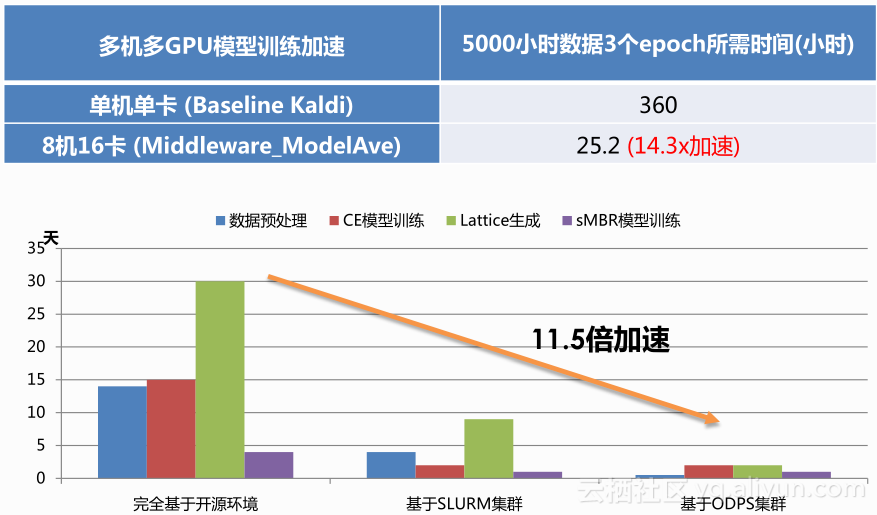
我们有一个多GPU模型训练加速,阿里有一个ODPS的分布式系统,它不光是做CPU的分布式运算,也有GPU的分布式运算跟调度,所以我们基于此做了一个大规模的分布式多机多卡的machine learning的system,然后专门把它用在语音识别上面。我们现在可以做到接近于线性的一个训练加速,当你用16块卡的时候可以得到一个14.3倍的加速,原来用单块卡训一个模型,可能5千小时还是不能算大的训练数据量,那整个多机多卡的训练上去以后,就可能把时间压缩到一天多一点,周期就被大大的加速了,所以我们可以比较快的迭代我们的模型,让用户的体验越来越好。
影响语音识别率的主要因素
现在的语音识别仍然没有那么完善,有些因素可以把它变得很差。
- 声学模型方面:比如环境因素,像噪音,在非常吵的环境下仍然是一个问题;近远场,如果你对着一个设备在3到5米的距离上面,当距离变长以后,也会很大的影响语音识别的准确率;还有混响,在会议室里面说话的时候就能通过各种墙面跟镜面的反射,有多条路径会把你说的话送到你的麦克风里面,就会有很强的混响,这件事情也会带来语音识别准确率非常大的下降。比如人的因素也是一个方面,方言、口音也是一个比较棘手的问题。
- 语言模型方面也同样,语音识别其实是一个强的跟领域相关的通用模型,但它用到例如说医疗领域的时候,那些药的名称、疾病名称,各种专业术语它都是完全不懂的,所以需要很多自动跟半自动的方式,去做一个语言模型上面的提升。
- 多语言混读方面,虽然现在部分能解,但是中英文混读仍然是一个非常难的东西,现在还没有一个特别好的方法能够完全解决。
如果大家关注这个领域,现在97%被认为是一个good number,还有人讲匹敌人类甚至说超越人类这样的判断,阿里始终有一个观点,就是脱离具体场景谈准确率都是耍流氓,语音识别到今天的发展仍是一个非常脆弱的东西,你可以有很高的识别率,在更多的实际应用场景下,当那些不利因素都进来的时候,完全可以从97%变到0%,甚至语音识别的准确率可以是负的。因为所有的增删改都是错,如果你没有说话,语音识别系统因为噪音的关系或者别的关系仍然可以出识别结果,那这个时候去计算准确率会是负的。所以公平来说,现在的语音识别的确取得了非常大的进步,在很多以前不能做的场景下,已经做的非常好了,但是仍然有更多的场景,现在还达不到大家所期望的高准确效果。
智能语音交互@阿里巴巴iDST
阿里在2014年底的时候决定很严肃的来看待语音这件事情,过去用PC买淘宝,今天大家更多的用移动设备买淘宝,会不会有一天买淘宝的入口变成物联网IoT,比如说电视、冰箱、音响、汽车,会不会跟互联网的交流不再通过手机而通过更多的设备,所以语音显然是里面一个重要模态。
我们一开始在集团内部构建基础服务能力,服务于阿里内部各种各样的语音需求,服务完内部以后,都会通过阿里云对外输出,所以现在越来越多的服务外部客户。我们特别重视数据算法跟计算的有机结合,关注交互智能和服务智能。
手淘里面有一个服务助手叫阿里小蜜的语音识别等都是我们的技术在后面做支撑。还有云栖大会就有专门的上汽荣威互联网汽车的展示,整个车里面的语音交互、导航、听歌等等,现在整个车的业都在向智能化方向发展,例如你开到某一个商场附近,它知道你快到目的地,它就会弹出一个语音消息来问你,例如说某个地方有什么活动,某个停车场今天是免费的,或者说某一个加油站今天92号汽油直降5毛等等,你就跟它说带我去吧,它就真的带你去了,还有一些跟支付相关加油不下车,语音交互显然就是其中能够实现车跟人互动的必由之路。
什么叫服务智能呢?我们试着把我们的传统行业例如客服的呼叫中心做一些智能化的升级,这是从阿里内部开始做的,阿里跟蚂蚁的客服中心其实每天接的电话数是非常大的,常年雇佣上万人自营跟外包小二在接电话,而且双十一用工量都是陡增的。对此,我们做了智能质检,就是当你有几万人在听电话的时候,你根本不知道你的员工有没有按照你的服务规范在做很好的服务,当时他们只能做到千分之几的抽检。智能质检上线以后,基本上每一通电话都会被机器自动识别下来,后面就有规则跟模型去判断服务是不是满足了客户的需要,问题回答的是否是对的等等。
比如客户说了谢谢,小二没有说不客气,就会被纠出来,这其实也是很好的心理作用,当小二知道有人在听的时候,他会更注意自己的服务质量,提升自己的业务水平。还有智能电话客服,今天大家打95188,第一个接起你电话的并不是真人,而是一个机器人。
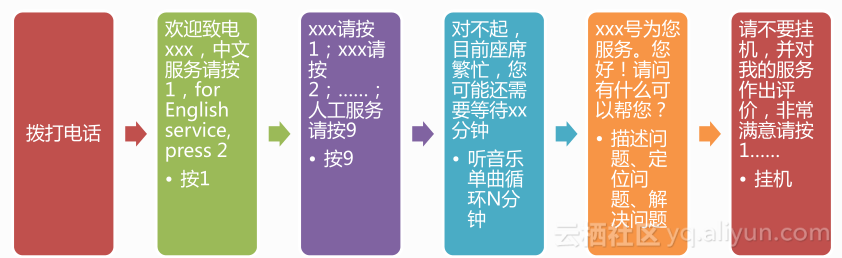
传统客服中心IVR业务,拨打电话-欢迎致电支付宝-中文服务请按1、英文服务请按2,然后通常我们都会略过,就听人工服务到底是按9还是按0。然后可能对不起、座席繁忙,可能还需要等待XX分钟,然后听音乐单曲循环,然后多少工号为你服务,最后还不放过你,让你对服务做出评价,因为只有这样他才能收集出小二有没有回答你的问题,这是一个非常郁闷的一个过程。
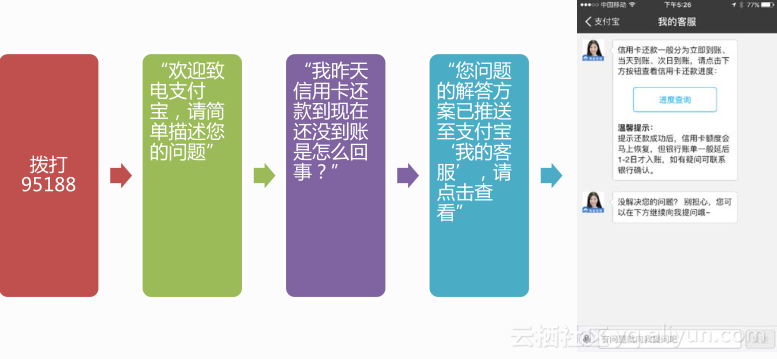
智能问答机器人降低人工坐席压力,我们做了95188,它会欢迎致电支付宝,你可以用非常自然的语言描述你的问题,然后机器人就会告诉你这类它能够解答的问题,它就会告诉你问题解决方案已经推送至支付宝我的客服。除非它回答不了的问题才会转给人工,转给人工的时候,它会初步判断应该转给哪一个技能组。
阿里巴巴iDST语音能力通过阿里云对外输出
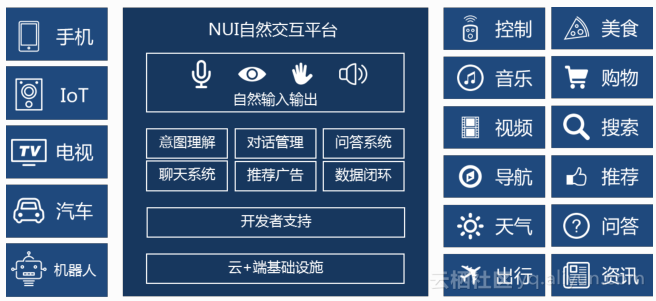
所有这些能力,现在都在阿里云上输出,外面的合作伙伴拿着阿里云半成品的技术去做自己真正的产品。比如我们在法院里面,现在有我们的阿里云生态伙伴用这个技术去做法院里面的语音识别,去帮助书记员更快的整理庭审报告。现在我们比较重视NUI自然交互平台产品,就是使得各种各样的端更好的连接上各种各样的互联网服务,端也不是我们做,服务也不是我们做,但是我们做中间层,这一层把人、用户从这些端上来的自然交互的意图转化为对这些服务的诉求,能够使我们的服务触达我们的用户,也使得我们做端的厂商一旦接入了服务以后,就有很多的互联网上的服务跟内容可以一下就传达到你的用户。


