美中不足
在2010年时,Yelp开源了一个名叫MRJob的框架,是用来在AWS基础设施上运行大MapReduce Job的。Yelp的工程师们用MRJob实现了很多功能,从广告推送到翻译,比比皆是。事实证明,MRJob是一个非常强大的工具,可以在我们当时丰富的数据集合上完成计算和聚集操作。
不幸的是,随着使用MRJob的服务数量巨增,运行和调度任务开始变得越来越复杂。由于很多任务都是要依赖上游任务的,所以就要好好地安排整个系统的拓扑。MapReduce任务并不是用于实时处理的,所以任务的拓扑要每天调度一次。更糟的是,万一上游的任务失败了,下游的也会失败,最终会输出错误的结果。因此就要有非常专业的能力来判断应该从哪个任务开始、以什么顺序重新运行,最终输出正确的结果。
爱思考的人就会问了:我们有没有什么办法来更高效地完成计算和转换任务呢?我们还想支持一个复杂的数据流中不同数据转换操作之间的依赖关系,尤其是要能优雅地处理模式改变及上游的故障。我们还希望系统能实时或者近实时地运行。这样,系统就可以用于业务分析及指标监控。换句话说,我们需要的是一个流处理器。
Storm之类现成的计算系统本来也是非常不错的。但由于许多主流的流处理框架对Python的支持都不太好,因此要把我们的其他后台程序与Storm或者其他现有流处理系统结合起来就会非常痛苦。
我们最先用的是Pyleus,这是一个让开发者可以用Python处理和转换数据的开源框架。Pyleus的底层仍然是使用Storm的,构建耗时比较久,运行得也慢。Twitter Heron宣布开源后,我们发现我们也碰上了许多他们碰到过的问题。Yelp自己有功能非常强大的用于部署服务的Platform-as-a-Service平台PaasTA,相比之下我们更喜欢使用PaaSTA,而不是运行专用的Storm集群。
从2015年7月开始,有一帮工程师们开始研发一种新型的数据仓库,也碰上了典型的扩展和性能问题。最开始时他们想用Pyleus来先清洗数据,再拷贝到Redshift上。后来他们意识到部署一整套Storm集群来运行些简单的Python逻辑实在太没必要了:用Yelp自己的运行服务的平台去部署一套基于Python的流处理器就足够了。我们的流处理器是基于Samza设计的,目的是提供一些简单的接口,用一种“处理消息”的方法来做数据转换。
工程师们在Hackathon 17上构建了运行在PyPy上的流处理器的原型,这样PassStorm就诞生了。
这名字中有什么含义?
PaaStorm的名字其实是PaaSTA和Storm的组合。那PaaStorm到底是干什么的呢?要回答这个问题,咱们先看看数据管道的基本架构:
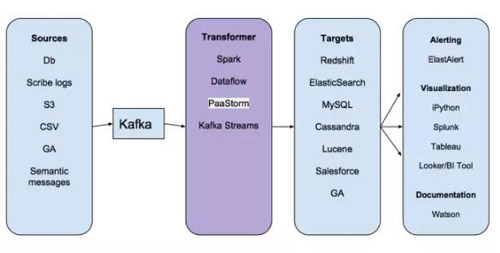
主要看看“Transformer”那一步,就会知道大多数存储在Kafka中的消息都并不能直接被导入目标系统。设想有一套Redshift集群是用来存储广告推送数据的。广告推送集群想存储的只是上游系统的某一个字段(比如某个业务的平均权重),否则它就要保存原始数据并对其进行聚合计算。如果Redhift广告推送集群要存储所有上游数据的话,就会浪费存储空间,导致系统性能降低。
在过去,各个服务都会写复杂的MapReduce任务,在把数据写到目标数据存储之前先进行数据处理。可是,这些MapReduce任务都碰到了上文所述的性能和扩展问题。数据管道给大家提供的好处之一是消费者程序可以拿到它所需要的数据的形式,不管上游数据本来是什么样。
减少示例代码
本来我们是可以让每个消费者程序自己按自己需要的方式做数据转换的。比如,广告推送系统可以自己写一个转换服务,从Kafka中的业务数据中提取出查看统计量,并自己维护这个转换服务的。这种办法最初工作得很好,但最终系统上规模时我们就碰上问题了。
我们想提供一个转换框架是基于以下考虑:
- 很多转换逻辑是通用的,可以在多个团队之间共享。比如把标志位转换成有意义的字段。
- 这样的转换逻辑通常会需要很多示例代码。比如连接数据源或数据目的、保存状态、监控吞吐量、故障恢复等。这样的代码本来并不需要在各种服务之间拷来拷去。
- 要保证能对数据进行实时处理的话,数据转换操作要尽可能地快,要基于流。
- 减少示例代码最自然的方式就是提供一个转换接口。大家的服务实现接口中完成一次转换操作的具体逻辑,然后,剩下的工作就由我们的流处理框架完成。
把Kafka作为消息总线
最初PaaStorm是一个Kafka-to-Kafka的转换框架,慢慢地才演进成也支持了其他类型的终端节点。把Kafka做为PaaStorm的终端节点简化了很多东西:每个对数据感兴趣的服务都可以注册到Topic上,关注任意转换过的数据或者原始数据,有新消息到来就处理就好了,完全不必在意是谁创建了这个Topic。转换过的数据按Kafka的保留策略持久化。因为Kafka是一个发布-订阅系统,下游系统也可以在任何它想的时候消费数据。
用Storm处理一切
当采用了PaaStorm之后,我们该怎样把我们的Kafka Topic之间的关系可视化呢?因为有些Topic中的数据会按照源到端的方式流向别的Topic,我们可以把我们的拓扑结构当成一个有向无环图:
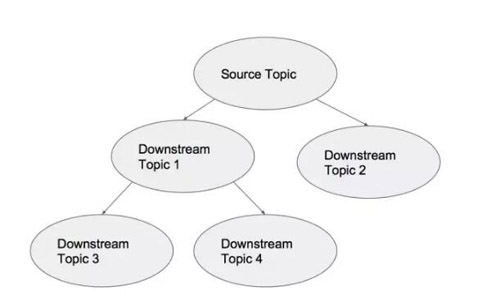
每个节点都是一个Kafka Topic,箭头表示PaaStorm提供的转换操作。这时候“PaaStorm”这个名字就变得更有意义了:象Storm一样,PaaStorm通过转换模块(象Bolt一样)提供对数据流的源(象Spout一样)的实时转换。
PaaStorm内部机制
PaaStorm的核心抽象叫做Spolt(Spout和Bolt的结合物)。象名字表示的一样,Spolt接口也定义了两个重要的东西:一个输入数据源,一种对那个源的消息数据进行的某种处理。
下面例子定义了一个最简单的Spolt:

这个Spolt会处理“refresh_primary.business.abc123efg456”这个Topic中的每一条消息,增加一个字段,保存原始消息中的‘name’字段的大写的值,然后再把这条处理过的新版本的消息发送出去。
值得一提的是数据管道中的所有消息都是不可修改的。要得到一条修改过的消息,就要创建一个新的对象。而且,因为我们在为消息体中增加一个新字段(就是那个增加的“大写字母的name”字段),新消息的模式已经改变了。在生产环境中,消息的模式ID是从来都不能写死的。我们要依靠Schematizer服务来为一条修改过的消息注册并提供合适的模式。
最后提一句,数据管道的客户端库提供了好几种非常相似的用名字空间、Topic名、源名和模式ID的组合来生成“spolt_source”的方法。这样就可以很容易地让某个Spolt去找到它需要的所有源并从中读取数据。要了解更多信息,请参考Schematizer的文章。
与Kafka相关的处理是怎样的?
也许你已经发现上面的Spolt中没有什么代码是与Kafka Topic相交互的。这是因为在PaaStorm中,所有真正的Kafka接口相关处理都是由一个内部实例(恰好也叫PaaStorm)完成的。PaaStorm实例会把一个特定的Spolt与对应的源和目的关联起来,并把消息送给Spolt处理,再把Spolt输出的消息发布到正确的Topic上去。
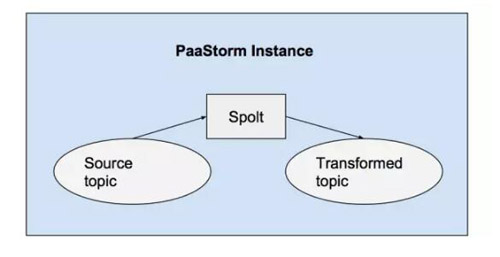
每个PaaStorm实例都用一个Spolt初始化。比如,下面的命令就用上文中定义的UppercaseNameSpolt开启了一次处理:
- PaaStorm(UppercaseNameSpolt()).start()
这就意味着所有有意写一个新转换器的人都可以简单地定义一个新的Spolt子类,压根不用修改任何PaaStorm运行体相关的东西。
从内部来看,PaaStorm运行体的主方法也是惊人的简单,伪码如下:

这个运行体先做了一些设置:初始化了生产者和消费者,以及消息计数器。然后,它一直等待上游Topic中的新数据。如果有新数据到来,就用Spolt处理它。Spolt处理之后会输出一条或多条消息,生产者再把它发布到下游的Topic。
另外简单提一下,PaaStorm运行体也提供了比如消费者注册、心跳机制(名叫“tick”)等。比如某个Spolt要经常性地清空它的内容,那就可以用tick来触发。
关于状态保存
PaaStorm保证可以可靠地从故障中恢复。万一发生了崩溃,我们就该从正确的偏移位置开始重新消费。但不幸的是,这个正确的偏移量一般情况下都并不是我们从上游的Topic中消费的最后那一条消息。原因是虽然我们已经消费了它,但事实上我们还没来得及把转换后的版本发布出去。
所以重新启动时正确的位置应该是上游Topic与已经成功发布到下游的最后一条消息对应的位置。在知道发到下游的最后一条消息的情况之后,我们需要知道它对应的上游的消息是哪一条,这样就可以从那里恢复了。
为了方便实现这个功能,PaaStorm的Spolt在处理一条原始消息时,会把与这条原始消息相对应的在上游Topic中的Kafka偏移量也加到转换后的包里。转换后的消息随后会在生产者的回调函数中把这个偏移量传回来。这样,我们就可以知道与下游Topic中最后一条消息对应的上游Topic的偏移量了。因为回调函数只有在生产者成功地把转换后的消息发布出去之后才会调用,也就意味着原始消息已经被成功处理了,在这种情况下,消费者就可以很放心的在那个回调函数中提交这个偏移量了。万一发生崩溃,我们可以直接从还没有被完全处理的上游消息那里开始继续处理。
从上面的伪码中可以看到,PaaStorm也会统计消费掉的消息数和发布的消息数。这样,感兴趣的用户可以检查上游和下游Topic中的吞吐量。这让我们很轻松地有了对任意转换操作的监控和性能检查功能。在Yelp,我们是把我们的统计信息发给SignalFX的:
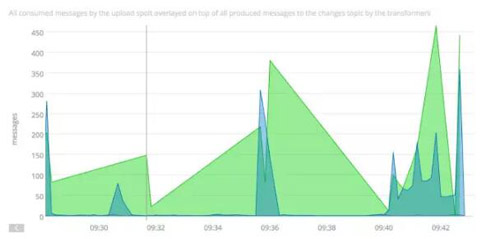
SignalFX图可以显示出在一个PaaStorm实例中生产者和消费者的吞吐量。在这个例子中,输入输出消息量并不匹配。
在PaaStorm中对生产者和消费者分开做统计的好处之一是我们可以把这两个吞吐量放在一起,看看瓶颈是在哪里。如果到不了这个粒度,是很难发现管道中的性能问题的。
PaaStorm的未来
PaaStorm提供了两个东西:一个接口,并实现了一套框架来支持这个接口。尽管我们并不希望PaaStorm的接口很快就被改动,但已经有一些孵化项目在计划解决“转换并连接”的问题了。在将来,我们希望能把PaaStorm的内部换成Kafka Stream或者Apache Beam,主要的障碍是对Python的支持程度如何,我们尤其看重的是对终端节点的支持。总之,在有开源的Python流处理项目成熟之前,我们会一直把PaaStorm用下去。
我们系列的下一篇
我们已经讨论了PaaStorm是如何从源到目的做数据的实时转换的。PaaStorm的最初设计是做一个Kafka-to-Kafka的系统,可事实上许多内部服务并不是要把数据输出到Kafka的,它们可能会把数据导入Redshift或MySQL之类的数据存储然后再做业务相关的东西。即使数据已经被转成了需要的格式,也还需要进一步:数据要被上传到目标数据存储中。
回顾一下上文的内容就会发现,PaaStorm的Spolt接口其实并没有限定必须输出到Kafka中。事实上,只需要少量的改动,Spolt就可以直接把消息发布到Kafka之外的系统中。在后续的文章里,我们会谈谈Yelp的Salesforce Connector:一个用PaaStorm来大量、高效地把数据从Kafka导入Salesforce的服务。
本文作者:Matt K
来源:51CTO