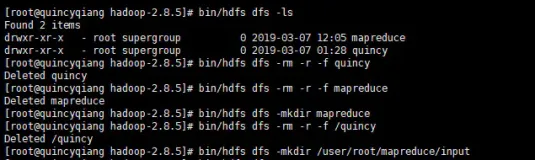
1、HDFS文件的权限以及读写操作
HDFS文件的权限:
- 与Linux文件权限类似
- r: read; w:write; x:execute,权限x对于文件忽略,对于文件夹表示是否允许访问其内容
- 如果Linux系统用户zhangsan使用hadoop命令创建一个文件,那么这个文件在HDFS中owner就是zhangsan
- HDFS的权限目的:阻止好人错错事,而不是阻止坏人做坏事。HDFS相信,你告诉我你是谁,我就认为你是谁
HDFS文件的读取:
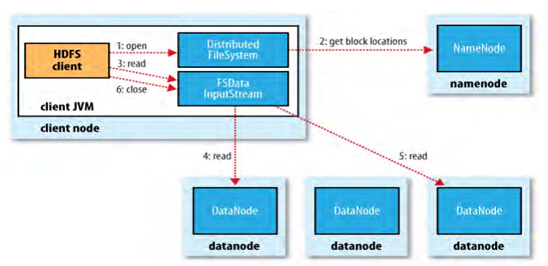
HDFS文件的写入:
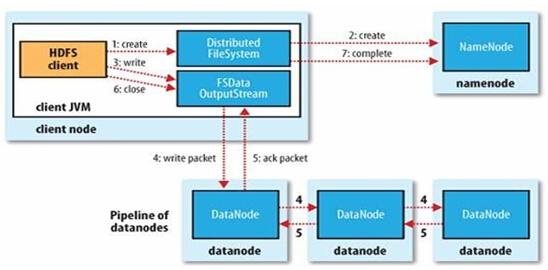
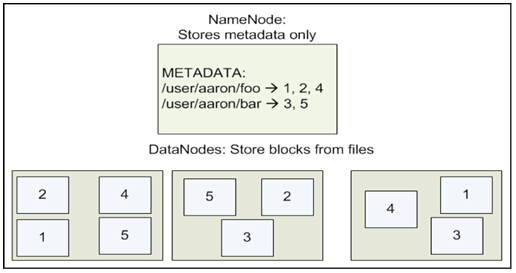
HDFS文件存储:
两个文件,一个文件156M,一个文件128在HDFS里面怎么存储?
–Block为64MB
–rapliction默认拷贝3份
HDFS文件存储结构:
2、HDFS下的文件操作
(1)列出HDFS文件
通过“-ls”命令列出HDFS下的文件
- wu@ubuntu:~/opt/hadoop-0.20.2$ bin/hadoop dfs -ls

(2)列出HDFS目录下某个文档中的文件
此处展示的是“-ls 文件名”命令浏览HDFS下名为in的文档中的文件
- wu@ubuntu:~/opt/hadoop-0.20.2$ bin/hadoop dfs -ls in

(3)上传文件到HDFS
此处展示的是“-put 文件1 文件2”命令将hadoop-0.20.2目录下的test1文件上传到HDFS上并重命名为test
- wu@ubuntu:~/opt/hadoop-0.20.2$ bin/hadoop dfs -put test1 test
注意:在执行“-put”时只有两种可能,即是执行成功和执行失败。在上传文件时,文件首先复制到DataNode上,只有所有的DataNode都成功接收完数据,文件上传才是成功的。
(4)将HDFS中的文件复制到本地系统中
此处展示的是“-get 文件1 文件2”命令将HDFS中的in文件复制到本地系统并命名为getin:
- wu@ubuntu:~/opt/hadoop-0.20.2$ bin/hadoop dfs -get in getin
(5)删除HDFS下的文档
此处展示的是“-rmr 文件”命令删除HDFS下名为out的文档:
- wu@ubuntu:~/opt/hadoop-0.20.2$ bin/hadoop dfs -rmr out
执行命令后,查看只剩下一个in文件,删除成功:

(6)查看HDFS下的某个文件
此处展示的是“-cat 文件”命令查看HDFS下in文件中的内容:
- wu@ubuntu:~/opt/hadoop-0.20.2$ bin/hadoop dfs -cat in/*
输出:
- hello world
- hello hadoop
PS:bin/hadoop dfs 的命令远不止这些,但是本文的这些命令很实用,对于其他的操作,可以通过“-help commandName”命令所列出的清单来进一步的学习
3、管理与更新
(1)报告HDFS的基本统计信息
通过“-report”命令查看HDFS的基本统计信息
- wu@ubuntu:~/opt/hadoop-0.20.2$ bin/hadoop dfsadmin -report
执行结果如下所示:
- 14/12/02 05:19:05 WARN conf.Configuration: DEPRECATED: hadoop-site.xml found in the classpath. Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, mapred-site.xml and hdfs-site.xml to override properties of core-default.xml, mapred-default.xml and hdfs-default.xml respectively
- Configured Capacity: 19945680896 (18.58 GB)
- Present Capacity: 13558165504 (12.63 GB)
- DFS Remaining: 13558099968 (12.63 GB)
- DFS Used: 65536 (64 KB)
- DFS Used%: 0%
- Under replicated blocks: 1
- Blocks with corrupt replicas: 0
- Missing blocks: 0
- ————————————————-
- Datanodes available: 1 (1 total, 0 dead)
- Name: 127.0.0.1:50010
- Decommission Status : Normal
- Configured Capacity: 19945680896 (18.58 GB)
- DFS Used: 65536 (64 KB)
- Non DFS Used: 6387515392 (5.95 GB)
- DFS Remaining: 13558099968(12.63 GB)
- DFS Used%: 0%
- DFS Remaining%: 67.98%
- Last contact: Tue Dec 02 05:19:04 PST 2014
(2)退出安全模式
NameNode在启动时会自动进入安全模式。安全模式是NameNode的一种状态,在这个阶段,文件系统不允许有任何的修改。安全模式的目的是在系统启动时检查各个DataNode
上数据块的有效性,同时根据策略对数据块进行必要的复制和删除,当数据块的最小百分比数满足配置的最小副本数条件时,会自动退出安全模式。
- wu@ubuntu:~/opt/hadoop-0.20.2$ bin/hadoop dfsadmin -safemode leave
(3)进入安全模式
- wu@ubuntu:~/opt/hadoop-0.20.2$ bin/hadoop dfsadmin -safemode enter
(4)添加节点
可扩展性是HDFS的一个重要的特性,向HDFS集群中添加节点是很容易实现的。添加一个新的DataNode节点,首先在新加的节点上安装好hadoop,要和NameNode使用相同的配置,修改HADOOP_HOME/conf/master文件,加入NameNode主机名。然后在NameNode节点上修改HADOOP_HOME/conf/slaves文件,加入新节点主机名。再建立到新节点无密码SSH连接,运行启动命令:
$ bin/start-all.sh
通过http://(主机名):50070可查看到新的DataNode节点添加成功
(5)负载均衡
用户可以使用下面的命令来重新平衡DataNode上的数据块的分布:
$ bin/start-balancer.sh
本文作者:佚名
来源:51CTO