摘要:8月24日,阿里云数据库技术峰会到来,本次技术峰会邀请到了阿里集团和阿里云数据库老司机们,为大家分享了一线数据库实践经验和技术干货。在本次峰会上,阿里云数据库技术专家张友东(林青)分享了如何从代码层面做好数据库安全防护,以及如何避免频发的数据库“勒索事件”的发生,帮助大家了解了数据库安全防护需要注意的事项。
以下内容根据演讲嘉宾现场视频以及PPT整理而成。
近年来,数据库安全问题逐渐引起大家的关注和重视,本次分享的主题就是如何去应对数据库安全所面对的问题。本次的分享主要将围绕以下三个方面:
一、2017数据库安全事件及反思
2017年1月,MongoDB赎金事件
在今年的1月份,MongoDB黑客勒索赎金事件在互联网上闹得沸沸扬扬。这个事件大致就是某一天你发现自己的数据库无法访问了,当登陆到数据库上去看时发现数据库中的数据全都没有了,而只有黑客留下的一些记录,里面的内容大概就是“你的数据库已经被我黑掉了,而且我已经对于你的数据库进行了备份,如果你想拿回自己的数据,就需要向某个比特币账户中转一笔钱。”,其实这与现实生活中的绑架勒索的性质基本相同。

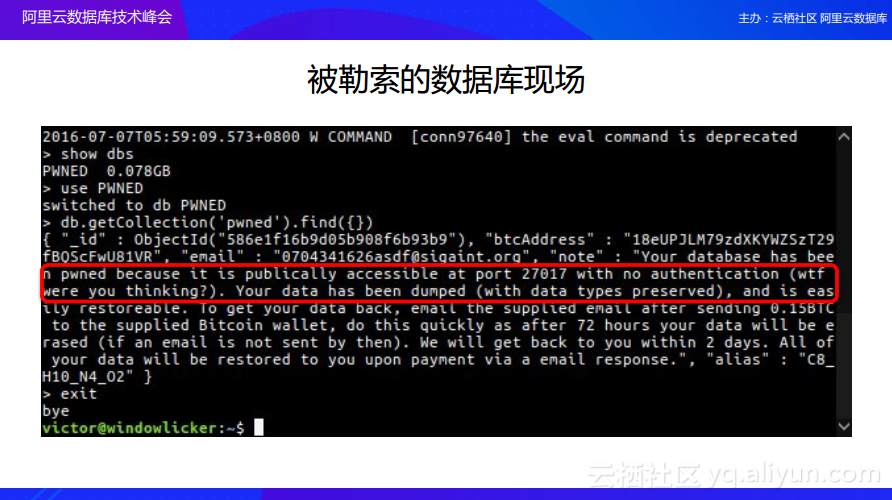
在被勒索的数据库现场,黑客除了将数据库黑掉之外,还会顺便对于数据库的用户鄙视了一番。正如下图中红框中的所显示的,黑客留言告诉数据库用户“你的数据库开放了公网访问并且还没有开启鉴权,你是怎么想的呢?根本就没有把数据当事情”。如果大家在数据库的使用过程中也存在类似的部署情况,那就一定要关注数据库的安全。
自从MongoDB黑客勒索赎金事件发生之后,从1月份到现在的8月份,对于数据库用户产生了什么样的影响呢?下图所展现的是今年1月份的数据统计,这是整个互联网上MongoDB数据库开放公网访问端口的数量统计。在这个数据排行中的前两名分别是美国和中国,其他国家与中美相比而言存在很大差距,其实这也是目前互联网发达程度的一个缩影。在1月份,美国的MongoDB数据库开放公网访问端口数量大概有一万七千个,中国则差不多刚好一万多个。
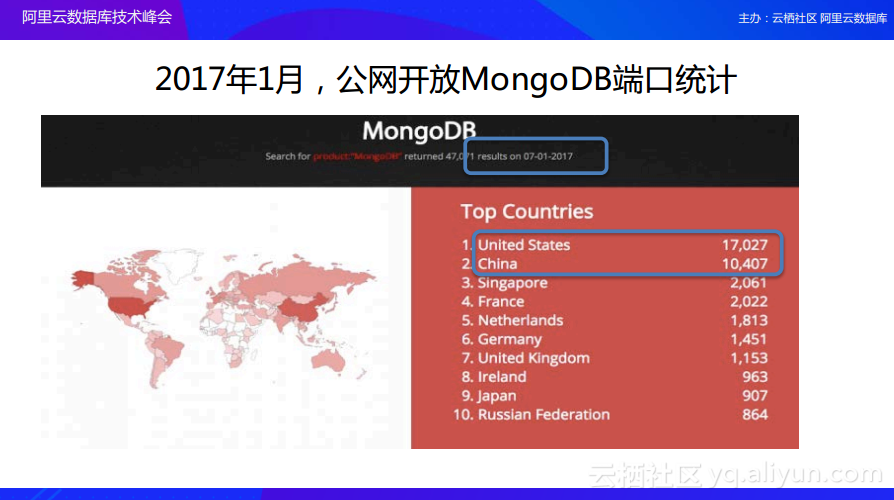
而到了今年8月份,美国的MongoDB数据库开放公网访问端口数量降到了其1月份数量的50%,而在中国则只降到了原本的80%,这充分说明了中国的技术同学在吸取技术经验教训方面还是有所欠缺的,所以我们应该更加重视数据库的安全问题。而且这个数据也只是能够统计到的,可能真实的数字会更多。

针对于MongoDB黑客勒索赎金事件,我们能够从中得到什么样的经验教训呢?
2017年1月,炉石传说数据库故障
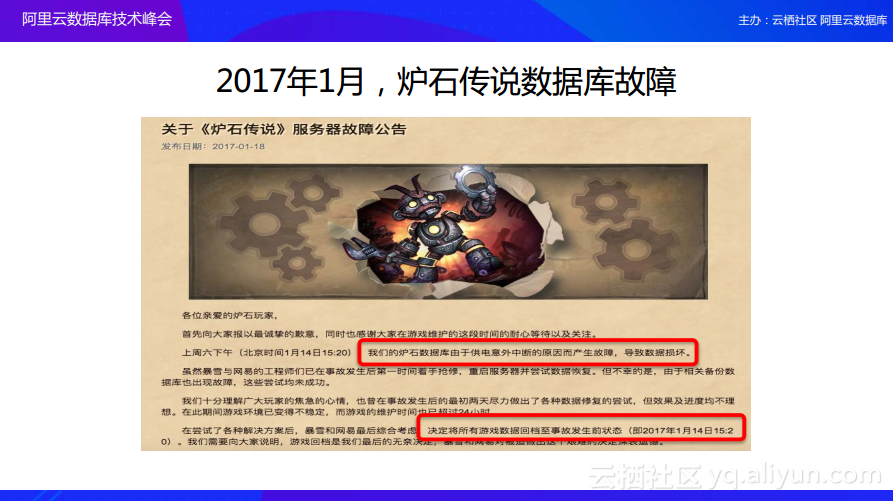
接下来和大家继续探讨2017年1月份的另一起数据库安全事件,也就是炉石传说数据库故障事件。这个事件并没有公布技术细节,只有炉石传说的官方公告。炉石传说在1月14号因为机房断电导致的出现了数据库故障,最终导致整个服务停了四五天,最终在1月18号将数据回滚到14号的某一个时间点。
这个问题虽然没有提供技术细节,但是我们依旧能够从中发现几个问题:
2017年2月,Gitlab数据库误删
在2017年2月份还出现了一起数据库安全事件,就是Gitlab的数据库误删事件。这个事件的发生完全是因为运维同学鏖战到深夜的时候,在已经非常疲劳的情况下把某一个数据库误删掉了。这个事件当时也导致Gitlab的整个服务都停掉了,但是做的比较好的一点是Gitlab将他们对于整个事件的处理过程在互联网上进行了直播,同时将改进的措施通过分成很多个issue来实现。

Gitlab的最大问题就是:对于一个数据库而言,理论上是做了多重的备份,但是在最终进行数据恢复的时候发现很多的数据备份其实是使用不了的。因为数据库的很多数据备份并没有经过验证,所以在需要使用的时候才发现备份数据是无法使用的。

通过上面的几个案例,大家可以发现在数据库安全方面其实存在着很多的威胁。DBA同学鏖战到深夜部署好自己的数据库,以为自己的数据库很安全了,但是事实却并不是这样的。总结而言,数据库安全方面所需要面对的威胁主要可以分为以下几个维度:
二、如何让你的数据库更加安全可靠?
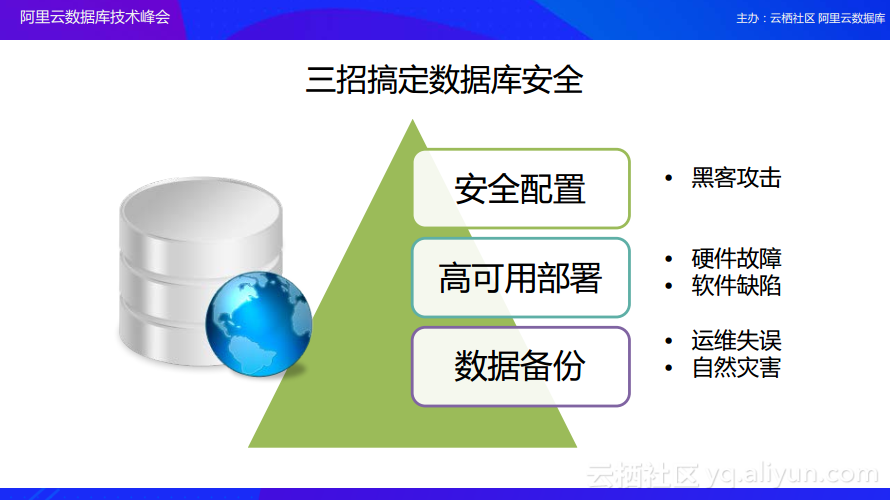
三招搞定数据库安全
面对这么多数据库安全的威胁,我们应该如何去做数据的安全防护呢?其实总结而言,只需要三招就能搞定数据库安全。第一招:安全配置,从单个数据库节点的数据来看,应该尽可能地进行安全方面的配置来避免遭受黑客攻击以及非法访问等。第二招:高可用部署,尽可能地部署多节点来构成的高可用数据库服务,这样就能够应对硬件故障的问题,当单个节点出现问题的时候,可以直接启用备用节点来顶上;当软件出现Bug导致数据库崩溃的时候,也可以通过高可用将故障进行转移。第三招:数据备份,做好数据备份就可以应对运维的失误以及自然灾害等问题。通过以上的三个步骤,就可以使得数据库达到比较安全的状态。
第一招: 数据库安全配置
接下来为大家更加详细地介绍如何使得数据库更加安全可靠。首先分享如何对数据库进行安全配置。因为用户的业务性质往往各不相同,所以对于数据库安全的要求级别也会是不一样的。这里的数据库配置将会分为三个维度进行介绍,分别是基础安全防护工作、进阶模式和更高层级的数据库防护需要做的工作。
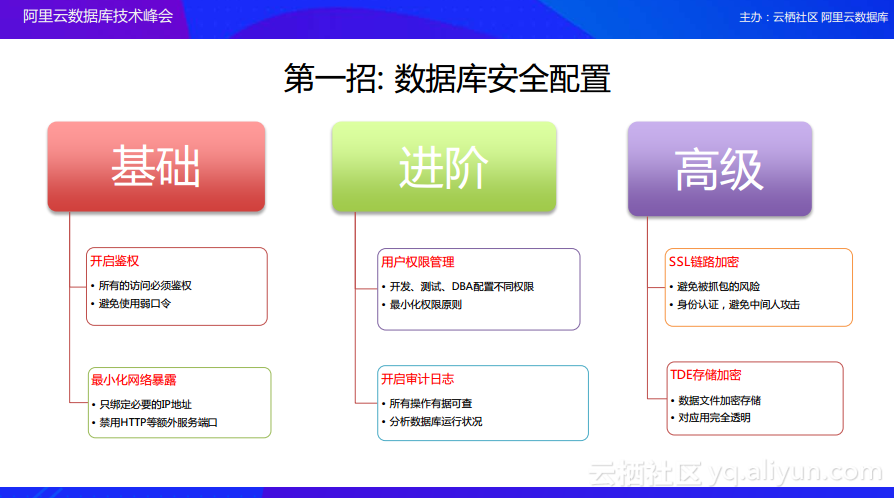
首先,对于基础的数据库安全防护工作而言,这里所需要做的第一件事情就是一定要开启鉴权。无论是通过公网访问数据库还是只在内网中进行访问,鉴权都是必不可少的。当鉴权开启之后,所有的数据库访问都会需要有鉴权的动作,而鉴权的方式也会有很多种,最常规的就是通过用户名和密码的方式进行鉴权。而在鉴权的设计中也应该注意一些问题,比如尽可能不要使用安全性比较弱的口令,在互联网上虽然可能有一些用户开启了鉴权,但是使用像“root-root”或者“root-123456”这样的弱口令的大有人在。基础的配置除了鉴权之外,还应该注意的就是整个数据库服务应该最小化网络的暴露,数据库服务需要部署在物理机器上,机器上可能会有很多块网卡,并且还有很多个IP可以绑定,在这样的情况下,尽量只去绑定需要访问的IP,如果没有必要给公网用户进行访问,那么就没有必要开启公网访问。除了绑定尽量少的IP之外,还需要注意的就是端口,因为有些类似于MongoDB这样的数据库服务,为了方便用户执行一些管理动作还开起了HTTP的端口。但是如果在生产环境进行访问,最好将这些HTTP端口禁用掉。
在基础的安全配置完成之后,就可以更进一步地去实现进阶的配置。进阶的配置主要分为两部分,第一部分是开启鉴权之后,因为有很多个用户需要去访问数据库,而这些用户往往会拥有不同的角色,比如开发、运维、DBA以及测试等等,所以需要尽量地为不同的角色配置不同的操作权限,而不是一股脑地为所有的用户都赋予Root权限,使得所有的用户能执行一切操作。具体给什么权限呢?其实这里应该使用最小化权限原则,用户需要什么样的权限,那就只给用户能够满足需求的最低权限。这样就能够尽量地避免一些误操作,也能够避免在出现数据误删事件之后,各个角色之间相互甩锅,当为不同用户分配了不同的权限之后,这样的问题就可以避免了。同时还可以开启审计日志,审计日志就是可以将所有数据库的操作都记录下来,具体是哪个用户操作的、操作用了多长时间、整个操作的执行计划等都可以详细地记录下来,这样就能将所有的操作都实现有据可查,即使发现数据库的误删动作以及非法访问都可以立即查出是谁做的。而且通过开启审计日志,还可以方便地查看数据库的运行状态是否是健康的。
如果用户想要获得更高级别的数据库安全配置其实可以做两部分的工作,其中一部分工作就是实现SSL链路加密。通过SSL链路加密能够避免数据被抓包的风险,并且在开启SSL链路加密之后,客户端和数据库服务端存在一个相互认证的过程,这样就可以避免遭受中间人攻击。除了链路加密,为了达到更高的数据安全级别,还可以在数据存储的时候进行数据加密,也就是TDE数据加密,这个通常是由数据库存储引擎在将数据存储到磁盘上的时候来做的透明的数据加密。而这样的整个加密过程对于用户而言是完全透明的,用户不需要去修改自己的访问业务代码。
第二招: 数据库高可用部署
以上所提到的三个层次的数据安全配置方式是需要根据用户自身业务的不同需求来进行配置的。单个节点的安全配置可能主要是为了防止数据库被黑客入侵,但是如果发生了硬件故障或者软件故障导致数据库崩溃,想要实现数据库的安全转移,就需要实现数据库的高可用部署。那么如何实现整个数据库集群的高可用部署呢?总结而言,数据库的高可用部署主要可以分为三种模式,分别是外部支持、内建高可用以及通过计算和存储分离将数据库的数据存储到共享存储之上,让共享存储来负责数据库的安全。这三种模式中,外部支持常见的有MySQL的MHA、Redis的Redis-sentinal,以及PGPool和Keepalived等都是实现的外部支持的高可用。在内建支持高可用方面,像MySQL Group Replication、MongoDB Replica Set以及阿里云最新上线的MySQL金融版都提供了内置的高可用策略。而在共享存储方面,主要有一些比如将数据放到SAN存储上,或者使用DRBD共享磁盘存储,而且阿里云即将上线的PolarDB数据库也实现了类似的共享存储模式。

外部支持示例:MHA for MySQL
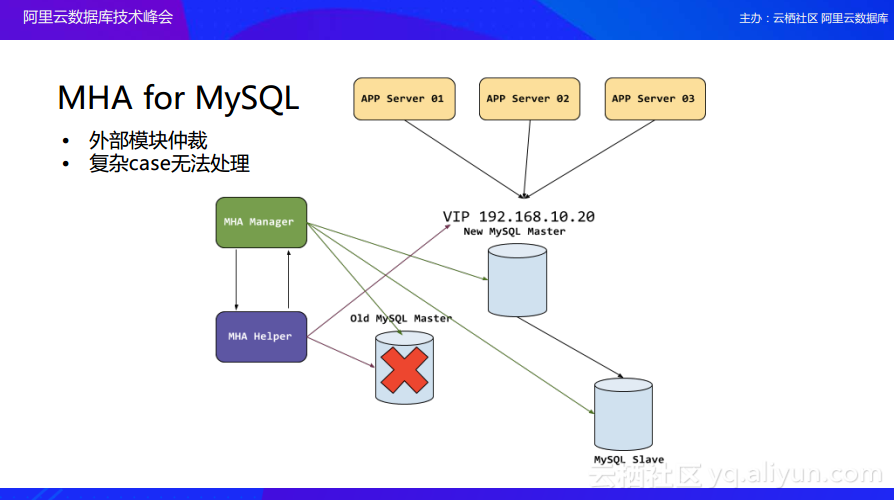
本文中针对数据库高可用部署的三种模式分别选取一个例子进行详细介绍。首先分享外部支持的高可用应该如何去实现,这里以MHA for MySQL为例。比如MySQL部署了一主两备的三节点集群,这时会存在一个MHA的Manager不停地去探索三节点集群的运行状态,当发现主节点故障的时候,MHA的Manager会自动将备节点切换为主节点。这样的策略是非常直观的,而且也是在目前在生产环境中使用最多的策略。那么对于这样的策略而言,又有什么缺点呢?首先这个策略需要一个外部模块进行仲裁,那么就会出现一个问题:外部模块的高可用又由谁来实现呢?除此之外,因为外部模块和数据库系统其实是两个系统,它们之间通过网络交互来实现可用性的探测,但是对于复杂的场景而言,这种方式是无法处理的。比如MHA与整个MySQL的三节点的网络如果隔离了,那么MHA就无法处理了。
内建高可用示例:MySQL Group Replication
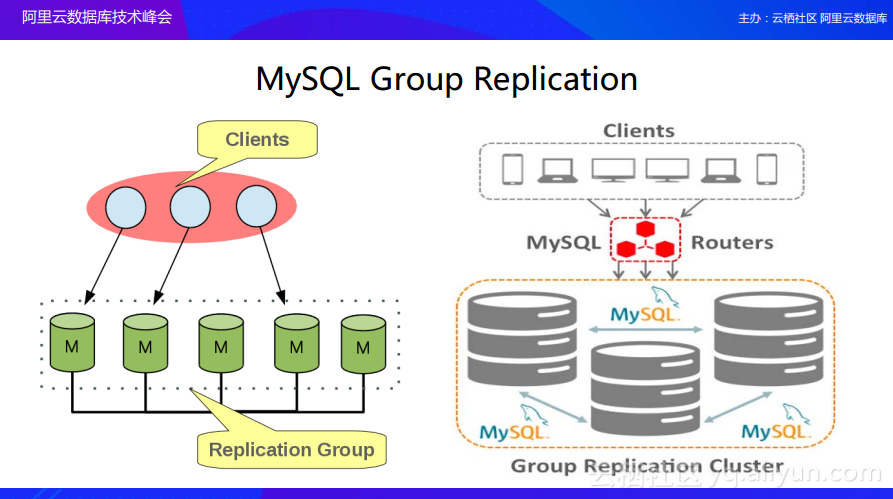
而上述的问题可以通过数据库内建高可用解决。接下来就为大家分享数据库内建高可用的MySQL Group Replication的例子。这个例子中就解决了在之前提到的模式下需要外部模块来仲裁的情况,现在就是将高可用做到集群中去,比如MySQL Group Replication其实会有N个节点,这里以三个节点为例。那么在Group Replication里面,可以采用每个节点都是主节点的模式,也可以采用一主两备的模式。如果所有的节点都为主节点,那么所有的节点都可以进行写入操作,在这些节点中间通过Paxos协议进行选举并且实现数据库强一致性的同步。当其中的一个节点出现故障的时候,集群可以实现自动的故障转移让可用的节点来提供服务。目前的趋势也是使用三节点,不光是Group Replication,包括阿里云数据库金融版也默认使用三节点,在三个节点之间通过Raft协议来进行选举以及数据一致性的同步。在有了这样支持的前提之下,对于生产环境下的三节点服务而言,只要大多数节点存活,那么整体的数据库服务就不会受到影响。
共享存储案例:阿里云PolarDB
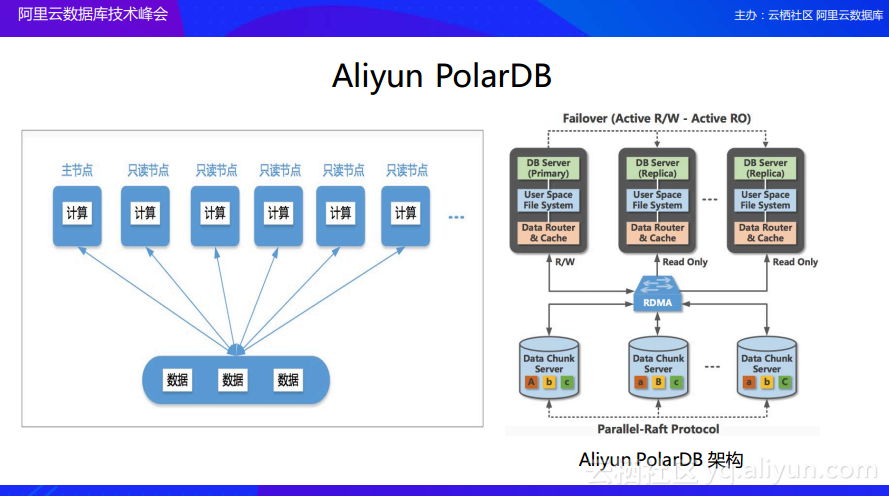
使用共享存储的策略并不是意味着不需要做高可用了,而是将计算和存储进行分离,但是最终对于存储还是需要实现高可用的。上图中右侧是阿里云PolarDB的例子,其上层是计算,下层是存储。大家可以看到在PolarDB的存储层是通过Raft实现了高可用的一致性数据同步,也就是说将整个数据同步下沉到存储层,而之前往往都是在计算层实现的。那么这样做有什么好处呢?因为存储和计算的整个生命周期是不一样的,比如数据库是一个写多读少的场景,可能数据库除了能够提供线上服务还可以提供离线的数据分析服务,所以需要部署很多的数据节点。如果按照现在的架构,可能每个节点都存储了一份数据,在实现共享存储之后,可能只存储了三份数据,而计算节点可以根据访问需求进行无限地扩展,达到了计算和存储分开管理的目的。
第三招: 数据库备份
以上的三个例子介绍了目前数据库的高可用是怎样实现的,接下来介绍如何实现数据库的备份。很多人对于数据库的备份存在着一个疑问:之前已经实现了数据库三节点了,通过三节点已经将数据存储了三份了,那么为什么还需要去做数据备份呢?其实一定是需要做备份的。这里就需要谈到做数据备份究竟有什么样的好处了,假设刚才实现了三节点数据库的部署,这样所能够应对的场景就像三节点的其中一个节点的硬件出现故障了,这时候可以自动fail over,或者其中某一个节点因为软件Bug导致整个数据库崩溃了,但是还有多个节点可用,这样整个数据库服务仍旧是处于可用状态。而备份所解决的问题却是:对于刚才的场景,假如运维同学对于三节点数据库做了误操作,向主节点发送了“drop database”删除数据库的操作,这样整个数据库就会从主节点删除掉了,同时这个删除动作也会同步到备节点上去,也就是对于像误删这样的场景,所有的节点上的数据都是会丢失的。还有就是类似于误删的黑客删库攻击,也会将整个数据库都删除掉,而且这将会是无法恢复的。除此之外,如果发生了自然灾害,或者整个机房出现了故障,数据也都会丢失,这时如果进行了数据库的备份,以上的场景就都能够覆盖了。

而在制定具体的备份策略的时候应该考虑两点:第一点就是业务能够容忍多长时间的数据丢失,如果能够接受一天的数据丢失,那么每天做一次全量的数据库备份就可以了;如果对于数据丢失完全是零容忍的,那么就需要去做任意时间点的数据备份,也就是说可以通过数据备份把数据恢复到任意一个时间点。除了数据能够恢复到什么程度,另外一点考量就是数据库备份需要多长时间才能够恢复,也就是所谓的RTO指标,这个指标决定了具体在做备份的时候是通过读数据库的文件做逻辑备份还是通过直接备份物理文件去实现物理备份。在做备份的时候有两点比较重要的注意事项:首先,因为备份需要有一个对于数据库的持续读取过程,有时候可能会因为备份影响到数据库的正常线上服务,也就是需要注意备份对于正常业务的影响;除此之外,备份的终极目标是当出现因为线上出现故障而需要使用备份数据的时候一定能够恢复,所以在做了数据库备份之后,一定要去做备份恢复的演练,来检验一下数据在备份之后到底能不能恢复。
全量备份方法
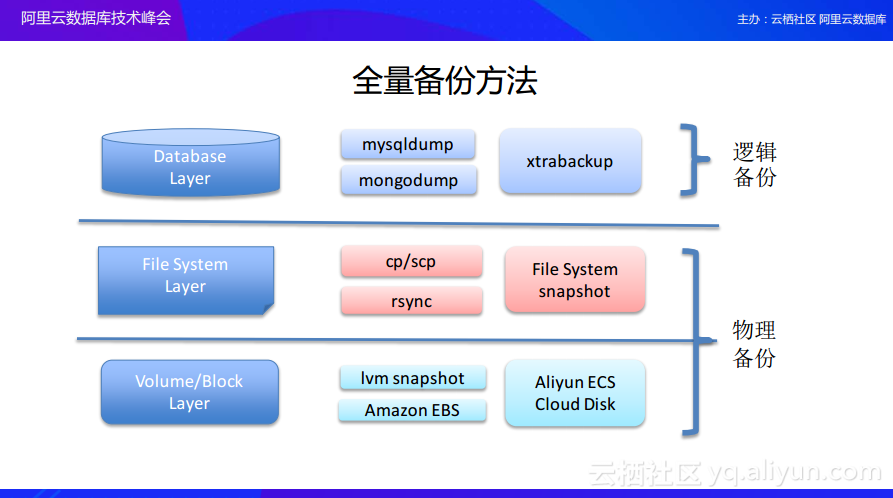
接下来介绍具体的备份策略,首先介绍上面所提到的全量备份,通过每天做一次全量备份就可以实现将数据恢复到一天的某个时间点。那么全量备份应该如何实现呢?从整个数据库的多个层次来介绍,上图中的最上层是数据库的逻辑层,其下层是文件系统层,最下面一层就是块设备以及卷管理层,这三层中的每一层都可以去做数据备份。首先,在数据库逻辑层面做备份,其实就是将数据库中的数据全部读取并且存储下来,这就是通常所说的逻辑备份,目前开源数据库已经可以提供很多工具来帮助实现逻辑全量备份。在文件系统层面,可以拷贝整个数据库的数据目录,把数据目录中的数据存储下来做物理备份。再往底层到卷管理和块设备层,如果使用的是LVM可以直接使用其卷管理的snapshot功能,如果使用的是云主机,各大云厂商也提供相应的snapshot功能,比如阿里云的ECS就提供了snapshot功能,通过这样功能实现定期的全量备份也是非常容易的。
逻辑备份 vs 物理备份
逻辑备份和物理备份的区别以及对于数据的影响存在多大的差异呢?我们又应该如何选择数据库备份策略的时候呢?下图就为大家进行了简单对比,从五个维度来对于逻辑备份和物理备份进行对比。
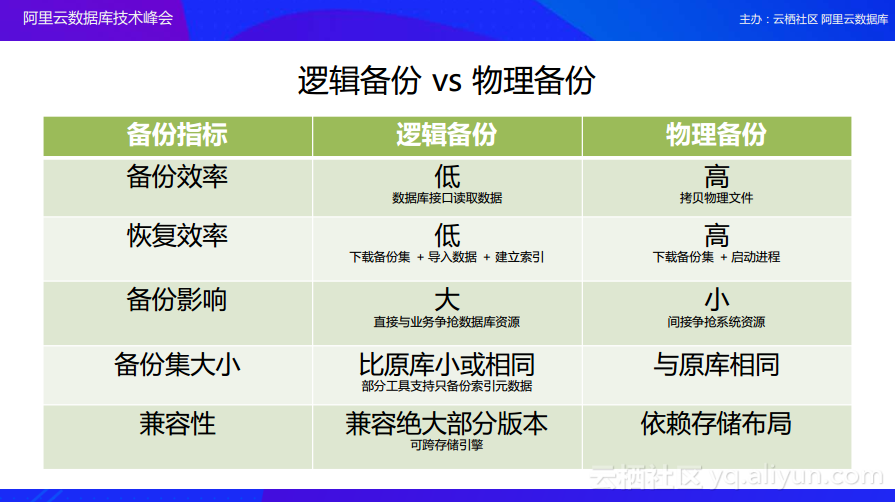
首先,从备份效率上来看,逻辑备份因为需要调用数据库的接口来逐条地读取数据库中的数据使得整个效率比较低,而物理备份则是直接拷贝数据库文件,所以其备份效率是相对比较高的。从恢复效率上进行对比,也就是对比进行数据恢复的时候所需要的时间,逻辑备份如果是将整个备份集存储到云端,那么在恢复的时候就需要将备份集下载下来并且逐条地导入到数据库中去,而如果使用的是物理备份方法则只需要将数据目录下载下来并且启动整个进程就可以了,所以在恢复效率方面也是物理备份比较高。从备份影响上来看,因为逻辑备份会需要直接与数据库的访问竞争资源,所以其整个影响是比较大的,而物理备份的影响是比较间接地,因为它是从在另外一个进程里面进行数据拷贝,所以其影响相对较小。对于备份集而言,其规模越大,保存这些备份数据所需要的成本也越高。从备份集的大小来看,逻辑备份通常会与整个数据库的大小一致或者比数据库更小,因为对于数据库而言,不仅仅有数据还会有索引等其他内容,而对于索引这样的内容,其实可以只对于一些元数据进行备份,在进行数据恢复的时候可以根据这些元数据建立索引,而不是将所有的索引数据都进行备份,这样可以使得整个备份集比原来的数据库小一些,而物理备份的备份集大小却一定是与原来数据库大小一致的。最后,对于备份兼容性而言,逻辑备份的整体兼容性是比较好的,因为数据库访问接口是全向兼容的,所以使用逻辑备份即使跨数据库版本也是可以恢复的,而使用物理备份时,因为数据库随着版本升级,可能数据库存储的布局发生了变化,这样低版本的数据备份到了高版本数据库中就可能无法恢复。根据以上五个方面的对比,用户可以根据自己的需求来选择数据备份策略。
增量备份方法
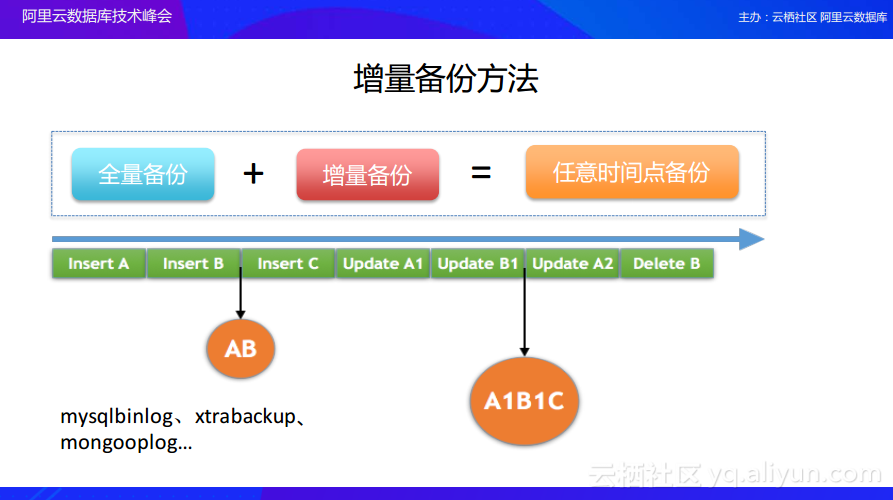
接下来分享增量备份方法。增量备份其实就可以帮助我们将自己的数据恢复到某一个时间点,如果业务能够接受一天或者几个小时的数据恢复,其实采用全量备份就足够了。如果想要达到任意时间点的恢复,就还需要做增量备份,将增量备份和全量备份配合起来就可以实现任意时间点的备份。增量备份方法的原理也比较简单,首先每天做一次数据库的全量备份,之后把对于数据库的每条更改的binlog都备份下来,接下来如果需要进行恢复的话,就可以使用最近的一次全量备份数据并且重放binlog一直到所需要恢复到的时间点就可以实现任意时间点的恢复。这部分的数据备份也存在很多工具,所以有需求的同学可以更加深入地研究。
三、阿里云数据库为你的数据保驾护航
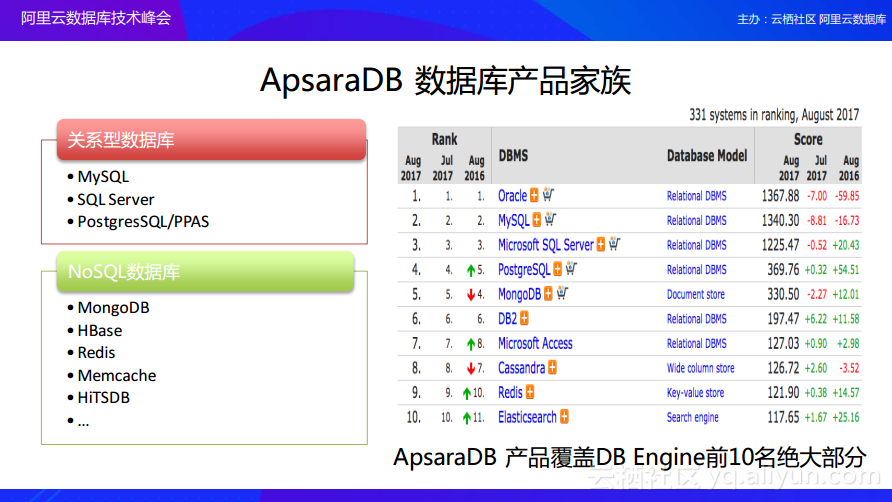
接下来介绍阿里云的数据库是如何实现数据安全防护的,其实阿里云数据库安全防护也是基于上述的安全配置、高可用部署以及数据备份这三个策略。阿里云数据库——ApsaraDB目前的数据库产品已经支持了整个DB Engine排名前十的绝大部分数据库,比如关系型数据库的MySQL、SQL Server、PG以及NoSQL数据库中的MongoDB、Redis以及HBase等。
ApsaraDB 安全体系总览
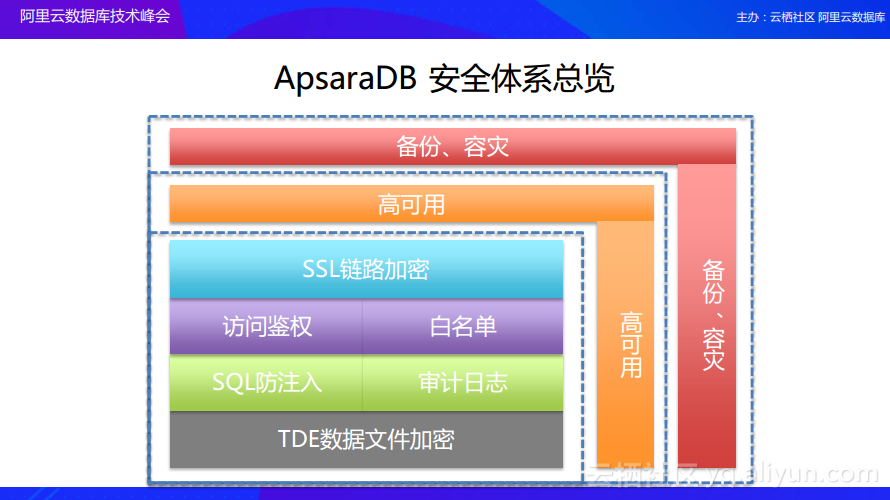
下图是ApsaraDB安全体系的总览,主要分为了三个维度:最内侧的框表示的是ApsaraDB在单节点上所做的安全工作,比如链路加密、访问鉴权以及防止SQL注入等;这一层往上就是在单节点实现了安全配置之后的高可用部署,最外面一层就是在高可用基础之上做的数据备份以及机房容灾工作。
ApsaraDB 数据安全特性
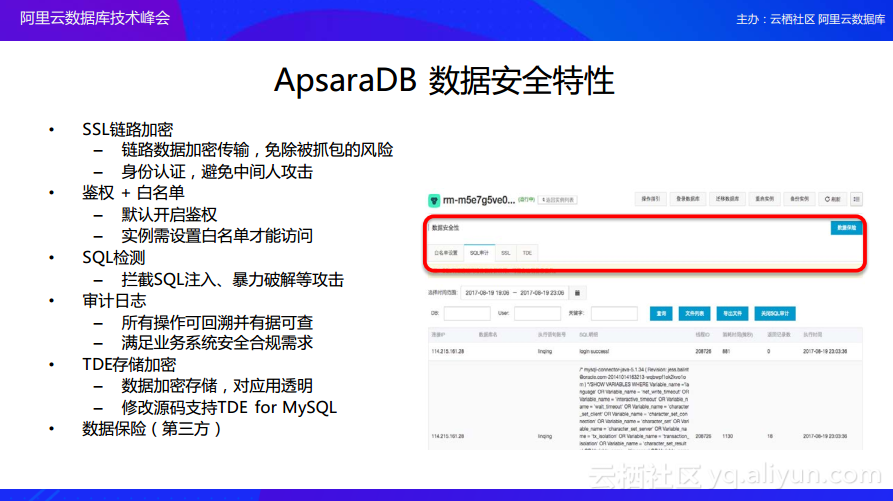
首先,对于单个节点的数据库安全配置而言,目前ApsaraDB支持如下的特性:
总结而言,对于整体安全策略而言,在故障发生之前,通过SSL、鉴权等策略尽量避免非法请求进入数据库。当访问进来之后,通过SQL检测,在事中对于安全策略进行加固,尽量地避免攻击。在事后,通过审计日志将访问请求都记录下来,更好地发现攻击以及误删等问题。最后,通过第三方数据保险使得用户在数据丢失时获得一定的经济补偿,来弥补所受到的损失。以上这些就是阿里云ApsaraDB单节点上的数据库安全特性。
ApsaraDB 高可用
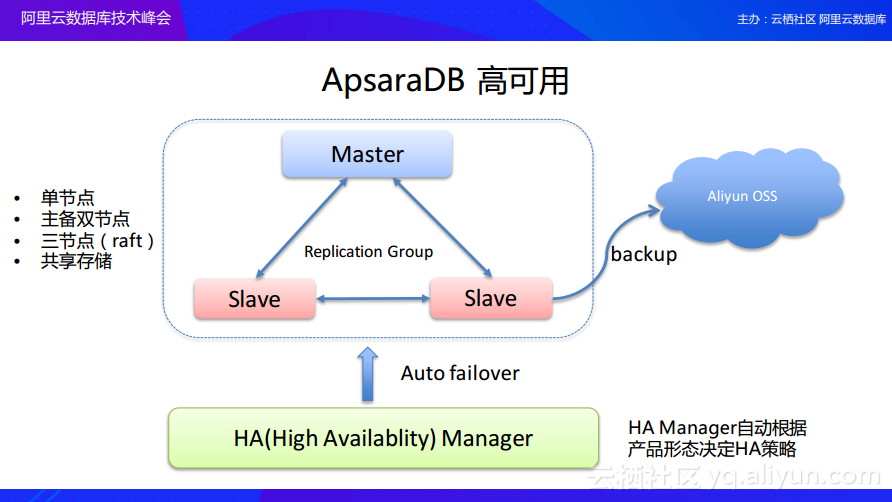
接下来介绍在单节点安全配置完成之后ApsaraDB如何实现高可用。ApsaraDB的产品形态是非常丰富的,有建议在测试环境使用的单节点、主备高可用的双节点产品、针对金融场景的三节点产品以及即将上线的共享存储产品,那么针对如此之多的产品形态,实现高可用的策略也将会是不一样的。这里会有一个统一的HA Manager来做所有数据库产品的高可用,而HA Manager本身也是一个高可用的系统,它会根据不同的产品形态进行可用性探测,比如对于主备双节点数据库产品而言,当发现主节点故障的时候把备节点切换成为主节点,而如果是三节点数据库集群,则可以自己通过Raft达到高可用,并且通过自身实现fail over。对于这样的情况,HA Manager则不需要做太多的工作,只需要把整个集群状态做一个同步就可以了,共享存储也会有对应的策略。通过全局的HA Manager来达到ApsaraDB的高可用,最终的目的就是实现当节点出现故障的时候,能够在秒级实现故障转移。在实现高可用的同时,无论是单节点还是主备节点,都会默认配置数据备份动作。
ApsaraDB 任意时间点备份恢复
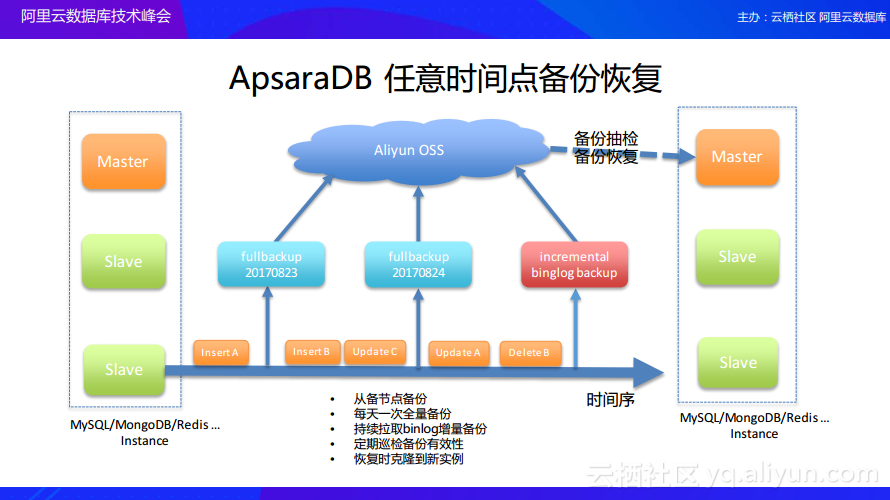
上图所展现的就是ApsaraDB在任意时间点进行数据备份恢复的系统架构。ApsaraDB会默认对于用户的数据库实例进行全量备份,同时还会持续地采集用户数据库的每一条变更的Binlog以及操作日志,这样就可以实现任意时间点的恢复。在备份的时候,为了尽量减少数据备份对于线上服务的影响,所有的备份都默认地从备节点执行的。之前提到的Gitlab的案例,其数据做了备份,但是从来没有演练过,最终导致备份数据不能使用,而在阿里云上存在专门的数据库备份恢复演练系统,它会持续地针对线上的实例来定期地做数据备份演练,这样就不至于出现当数据库出现故障时无法通过备份恢复的尴尬情况。
ApsaraDB 容灾
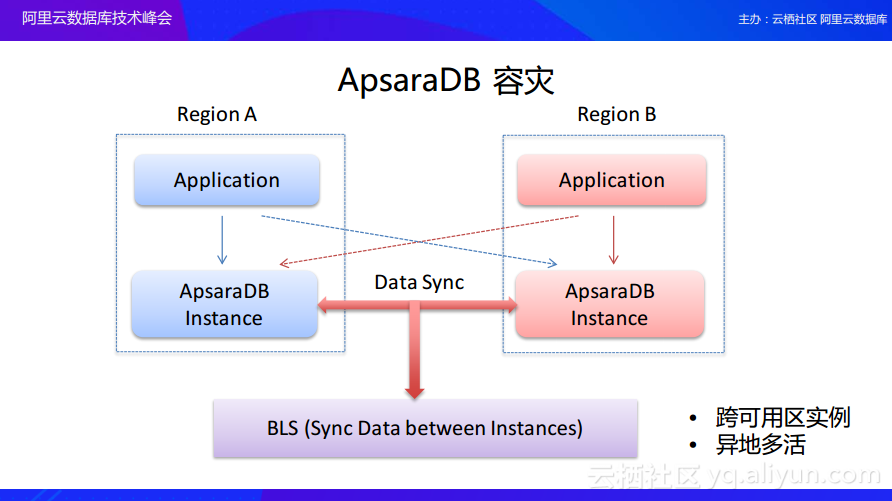
除了实现数据备份,ApsaraDB还提供了容灾策略。这里提供了两种策略,第一种是ApsaraDB支持跨可用区的实例,也就是一个一主多备的数据库实例可以跨多个可用区进行部署。这样即使单个可用区的机房出现故障的时候,其他可用区的机房也不会受到影响,可以把整个服务转移到另外的可用区。而一主多备的策略可以保证在某一个时刻至少有一个节点是活跃的。除了这个策略,ApsaraDB最近还推出了异地多活的容灾模式,用户可以在多个Region里购买数据库实例,阿里云在后台将通过数据库同步服务自动地保持Region之间数据库实例的数据处于同步状态。同步的状态就是可以配置一个为主节点一个为备节点,也可以配置两个都为主节点并使他们之间数据相互同步,这样就能够达到两个机房的主数据双活的状态,即便一个机房出现故障的时候,整个业务也可以切换到另外的机房来实现实时的容灾,从而可以避免像之前提到的炉石传说因为机房故障所造成的服务停止。
ApsaraDB 源码能力 + 专家服务

面对软件故障,其实可以通过高可用来实现故障转移。而数据库也是软件,有时也会遇到一些导致数据丢失的Bug,而很多用户却没有那么强大的技术能力来修复数据库源码级别的Bug,而阿里云数据库团队具有强大的源码能力,能够进行数据库源码的开发,这里包括了开源数据库的源码开发以及像基于MySQL的AliSQL这样的自研数据库的源码开发。除此之外,阿里云数据库团队还能够提供专家服务,当用户在使用阿里云数据库时出现了问题可以联系专家服务团队的同学帮助解决。总而言之,阿里云数据库拥有一套完备的数据安全防护体系,当你遇到自己无法解决的问题时,阿里云数据库背后的强大技术团队可以为你提供技术支撑。
以下内容根据演讲嘉宾现场视频以及PPT整理而成。
近年来,数据库安全问题逐渐引起大家的关注和重视,本次分享的主题就是如何去应对数据库安全所面对的问题。本次的分享主要将围绕以下三个方面:
- 2017数据库安全事件及反思
- 如何让你的数据库更加安全可靠?
- 阿里云数据库为你的数据保驾护航
一、2017数据库安全事件及反思
2017年1月,MongoDB赎金事件
在今年的1月份,MongoDB黑客勒索赎金事件在互联网上闹得沸沸扬扬。这个事件大致就是某一天你发现自己的数据库无法访问了,当登陆到数据库上去看时发现数据库中的数据全都没有了,而只有黑客留下的一些记录,里面的内容大概就是“你的数据库已经被我黑掉了,而且我已经对于你的数据库进行了备份,如果你想拿回自己的数据,就需要向某个比特币账户中转一笔钱。”,其实这与现实生活中的绑架勒索的性质基本相同。
- 这些数据库之所以会被黑客攻击,一个原因是这些数据库开放了公网访问,使得任何一台连接到公网的机器都能够访问到。除此之外,这些数据库也没有开启鉴权,所以导致黑客能够轻松地访问用户的数据库,造成了用户的数据损失。
- 受到影响的用户对于数据的备份不够重视,因为如果用户对于数据进行了备份,即使黑客将数据删除了,用户也可以通过备份数据来进行恢复。
2017年1月,炉石传说数据库故障
接下来和大家继续探讨2017年1月份的另一起数据库安全事件,也就是炉石传说数据库故障事件。这个事件并没有公布技术细节,只有炉石传说的官方公告。炉石传说在1月14号因为机房断电导致的出现了数据库故障,最终导致整个服务停了四五天,最终在1月18号将数据回滚到14号的某一个时间点。
- 炉石传说并没有做高可用的机房容灾,因为整个机房挂了,于是服务就停了。
- 整个数据恢复使用了四五天的时间,所以在数据恢复方面的工作还是存在一定欠缺的。
2017年2月,Gitlab数据库误删
在2017年2月份还出现了一起数据库安全事件,就是Gitlab的数据库误删事件。这个事件的发生完全是因为运维同学鏖战到深夜的时候,在已经非常疲劳的情况下把某一个数据库误删掉了。这个事件当时也导致Gitlab的整个服务都停掉了,但是做的比较好的一点是Gitlab将他们对于整个事件的处理过程在互联网上进行了直播,同时将改进的措施通过分成很多个issue来实现。
- 黑客攻击,黑客攻击存在不同层面,也有很多种攻击方法。
- 硬件故障,如果数据库服务只部署了单个节点,当单个节点挂掉之后,整个数据库就无法提供服务了。
- 软件缺陷,数据库服务毕竟是软件系统,当软件存在Bug的时候,也往往会造成安全问题。
- 运维失误,类似于刚才提到的Gitlab事件,数据库往往是由运维同学管理的,而运维同学可能会发生一些运维的失误,这也可能造成数据的丢失。
- 自然灾害,类似于之前的炉石传说的机房断电以及其他可能的自然灾害导致机房数据无法恢复。
二、如何让你的数据库更加安全可靠?
三招搞定数据库安全
面对这么多数据库安全的威胁,我们应该如何去做数据的安全防护呢?其实总结而言,只需要三招就能搞定数据库安全。第一招:安全配置,从单个数据库节点的数据来看,应该尽可能地进行安全方面的配置来避免遭受黑客攻击以及非法访问等。第二招:高可用部署,尽可能地部署多节点来构成的高可用数据库服务,这样就能够应对硬件故障的问题,当单个节点出现问题的时候,可以直接启用备用节点来顶上;当软件出现Bug导致数据库崩溃的时候,也可以通过高可用将故障进行转移。第三招:数据备份,做好数据备份就可以应对运维的失误以及自然灾害等问题。通过以上的三个步骤,就可以使得数据库达到比较安全的状态。
第一招: 数据库安全配置
接下来为大家更加详细地介绍如何使得数据库更加安全可靠。首先分享如何对数据库进行安全配置。因为用户的业务性质往往各不相同,所以对于数据库安全的要求级别也会是不一样的。这里的数据库配置将会分为三个维度进行介绍,分别是基础安全防护工作、进阶模式和更高层级的数据库防护需要做的工作。
在基础的安全配置完成之后,就可以更进一步地去实现进阶的配置。进阶的配置主要分为两部分,第一部分是开启鉴权之后,因为有很多个用户需要去访问数据库,而这些用户往往会拥有不同的角色,比如开发、运维、DBA以及测试等等,所以需要尽量地为不同的角色配置不同的操作权限,而不是一股脑地为所有的用户都赋予Root权限,使得所有的用户能执行一切操作。具体给什么权限呢?其实这里应该使用最小化权限原则,用户需要什么样的权限,那就只给用户能够满足需求的最低权限。这样就能够尽量地避免一些误操作,也能够避免在出现数据误删事件之后,各个角色之间相互甩锅,当为不同用户分配了不同的权限之后,这样的问题就可以避免了。同时还可以开启审计日志,审计日志就是可以将所有数据库的操作都记录下来,具体是哪个用户操作的、操作用了多长时间、整个操作的执行计划等都可以详细地记录下来,这样就能将所有的操作都实现有据可查,即使发现数据库的误删动作以及非法访问都可以立即查出是谁做的。而且通过开启审计日志,还可以方便地查看数据库的运行状态是否是健康的。
如果用户想要获得更高级别的数据库安全配置其实可以做两部分的工作,其中一部分工作就是实现SSL链路加密。通过SSL链路加密能够避免数据被抓包的风险,并且在开启SSL链路加密之后,客户端和数据库服务端存在一个相互认证的过程,这样就可以避免遭受中间人攻击。除了链路加密,为了达到更高的数据安全级别,还可以在数据存储的时候进行数据加密,也就是TDE数据加密,这个通常是由数据库存储引擎在将数据存储到磁盘上的时候来做的透明的数据加密。而这样的整个加密过程对于用户而言是完全透明的,用户不需要去修改自己的访问业务代码。
第二招: 数据库高可用部署
以上所提到的三个层次的数据安全配置方式是需要根据用户自身业务的不同需求来进行配置的。单个节点的安全配置可能主要是为了防止数据库被黑客入侵,但是如果发生了硬件故障或者软件故障导致数据库崩溃,想要实现数据库的安全转移,就需要实现数据库的高可用部署。那么如何实现整个数据库集群的高可用部署呢?总结而言,数据库的高可用部署主要可以分为三种模式,分别是外部支持、内建高可用以及通过计算和存储分离将数据库的数据存储到共享存储之上,让共享存储来负责数据库的安全。这三种模式中,外部支持常见的有MySQL的MHA、Redis的Redis-sentinal,以及PGPool和Keepalived等都是实现的外部支持的高可用。在内建支持高可用方面,像MySQL Group Replication、MongoDB Replica Set以及阿里云最新上线的MySQL金融版都提供了内置的高可用策略。而在共享存储方面,主要有一些比如将数据放到SAN存储上,或者使用DRBD共享磁盘存储,而且阿里云即将上线的PolarDB数据库也实现了类似的共享存储模式。
外部支持示例:MHA for MySQL
内建高可用示例:MySQL Group Replication
共享存储案例:阿里云PolarDB
第三招: 数据库备份
以上的三个例子介绍了目前数据库的高可用是怎样实现的,接下来介绍如何实现数据库的备份。很多人对于数据库的备份存在着一个疑问:之前已经实现了数据库三节点了,通过三节点已经将数据存储了三份了,那么为什么还需要去做数据备份呢?其实一定是需要做备份的。这里就需要谈到做数据备份究竟有什么样的好处了,假设刚才实现了三节点数据库的部署,这样所能够应对的场景就像三节点的其中一个节点的硬件出现故障了,这时候可以自动fail over,或者其中某一个节点因为软件Bug导致整个数据库崩溃了,但是还有多个节点可用,这样整个数据库服务仍旧是处于可用状态。而备份所解决的问题却是:对于刚才的场景,假如运维同学对于三节点数据库做了误操作,向主节点发送了“drop database”删除数据库的操作,这样整个数据库就会从主节点删除掉了,同时这个删除动作也会同步到备节点上去,也就是对于像误删这样的场景,所有的节点上的数据都是会丢失的。还有就是类似于误删的黑客删库攻击,也会将整个数据库都删除掉,而且这将会是无法恢复的。除此之外,如果发生了自然灾害,或者整个机房出现了故障,数据也都会丢失,这时如果进行了数据库的备份,以上的场景就都能够覆盖了。
全量备份方法
逻辑备份 vs 物理备份
逻辑备份和物理备份的区别以及对于数据的影响存在多大的差异呢?我们又应该如何选择数据库备份策略的时候呢?下图就为大家进行了简单对比,从五个维度来对于逻辑备份和物理备份进行对比。
增量备份方法
三、阿里云数据库为你的数据保驾护航
接下来介绍阿里云的数据库是如何实现数据安全防护的,其实阿里云数据库安全防护也是基于上述的安全配置、高可用部署以及数据备份这三个策略。阿里云数据库——ApsaraDB目前的数据库产品已经支持了整个DB Engine排名前十的绝大部分数据库,比如关系型数据库的MySQL、SQL Server、PG以及NoSQL数据库中的MongoDB、Redis以及HBase等。
ApsaraDB 安全体系总览
下图是ApsaraDB安全体系的总览,主要分为了三个维度:最内侧的框表示的是ApsaraDB在单节点上所做的安全工作,比如链路加密、访问鉴权以及防止SQL注入等;这一层往上就是在单节点实现了安全配置之后的高可用部署,最外面一层就是在高可用基础之上做的数据备份以及机房容灾工作。
ApsaraDB 数据安全特性
- 在数据库接收请求开始就支持SSL链路加密,也就是说可以配置数据库使得所有请求的网络数据都是加密的,这样可以免除数据被抓包的风险,还能避免中间人攻击。
- 当加密的数据到达数据库,开始处理用户请求之后,还提供了鉴权以及白名单策略。首先鉴权是默认开启的,如果用户希望使更多的服务器能够访问数据库就需要去开启白名单,通过鉴权+白名单这两个策略来尽量地避免非法访问。
- 在通过了鉴权和白名单之后还会进行SQL检测,因为SQL访问可能包含像SQL注入这样的攻击,所以需要对于用户的SQL进行防止注入的检测。
- 同时,如果配置了审计日志就会把所有的访问都记录到审计日志里面,有了审计日志之后,所有的请求以及所有数据库的操作都是有据可查的并且是可以回溯的。
- 在最底层数据存储到磁盘的时候还可以配置TDE存储加密,这样使得最终的数据以密文的形式存储到磁盘中,这样即使对方拿到数据文件也无法读取其中的数据。
- 最后,阿里云还会提供数据保险服务,用户可以为自己的数据库购买保险,当出现黑客攻击、数据库被破坏的情况发生时,可以获得一定的赔付。
总结而言,对于整体安全策略而言,在故障发生之前,通过SSL、鉴权等策略尽量避免非法请求进入数据库。当访问进来之后,通过SQL检测,在事中对于安全策略进行加固,尽量地避免攻击。在事后,通过审计日志将访问请求都记录下来,更好地发现攻击以及误删等问题。最后,通过第三方数据保险使得用户在数据丢失时获得一定的经济补偿,来弥补所受到的损失。以上这些就是阿里云ApsaraDB单节点上的数据库安全特性。
ApsaraDB 高可用
ApsaraDB 任意时间点备份恢复
ApsaraDB 容灾
ApsaraDB 源码能力 + 专家服务