Druid 是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。
Druid 具有以下主要特征:
- 为分析而设计——Druid 是为 OLAP 工作流的探索性分析而构建,它支持各种过滤、聚合和查询等类;
- 快速的交互式查询——Druid 的低延迟数据摄取架构允许事件在它们创建后毫秒内可被查询到;
- 高可用性——Druid 的数据在系统更新时依然可用,规模的扩大和缩小都不会造成数据丢失;
- 可扩展——Druid 已实现每天能够处理数十亿事件和 TB 级数据。
当业务中出现以下情况时,Druid 是一个很好的技术方案选择:
- 需要交互式聚合和快速探究大量数据时;
- 需要实时查询分析时;
- 具有大量数据时,如每天数亿事件的新增、每天数 10T 数据的增加;
- 对数据尤其是大数据进行实时分析时;
- 需要一个高可用、高容错、高性能数据库时。
查询操作中数据流和各个节点的关系如下图所示:
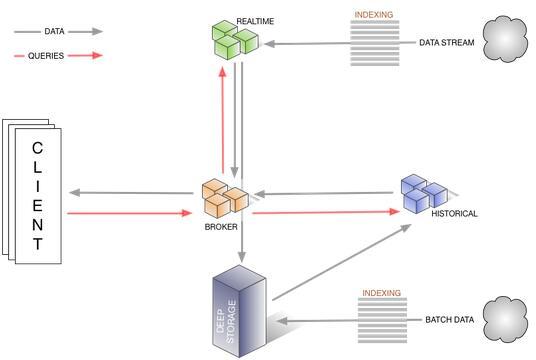
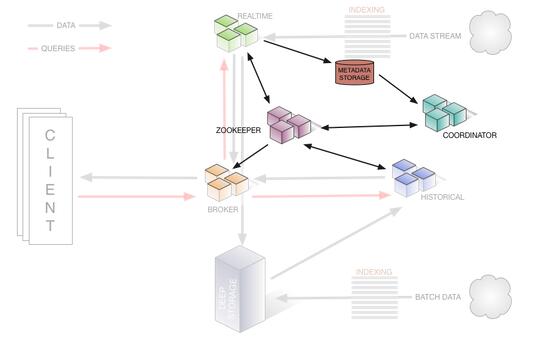
如下图是 Druid 集群的管理层架构,该图展示了相关节点和集群管理所依赖的其他组件(如负责服务发现的ZooKeeper集群)的关系:
本文作者:佚名
来源:51CTO
