
前言
这几天学校开始选毕业设计,选到了数据脱敏系统设计的题目,在阅读了该方面的相关论文之后,感觉对大数据安全有了不少新的理解。
介绍
随着大数据时代的到来,大数据中蕴藏的巨大价值得以挖掘,同时也带来了隐私信息保护方面的难题,即如何在实现大数据高效共享的同时,保护敏感信息不被泄露。
数据安全是信息安全的重要一环。当前,对数据安全的防护手段包括对称/非对称加密、数据脱敏、同态加密、访问控制、安全审计和备份恢复等。他们对数据的保护各自有各自的特点和作用,今天我主要说数据脱敏这一防护手段。
许多组织在他们例行拷贝敏感数据或者常规生产数据到非生产环境中时会不经意的泄露信息。例如:
1.大部分公司将生产数据拷贝到测试和开发环境中来允许系统管理员来测试升级,更新和修复。
2.在商业上保持竞争力需要新的和改进后的功能。结果是应用程序的开发者需要一个环境仿真来测试新功能从而确保已经存在的功能没有被破坏。
3.零售商将各个销售点的销售数据与市场调查员分享,从而分析顾客们的购物模式。
4.药物或者医疗组织向调查员分享病人的数据来评估诊断效果和药物疗效。
结果他们拷贝到非生产环境中的数据就变成了黑客们的目标,非常容易被窃取或者泄露,从而造成难以挽回的损失。
数据脱敏就是对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。在涉及客户安全数据或者一些商业性敏感数据的情况下,在不违反系统规则条件下,对真实数据进行改造并提供测试使用,如身份证号、手机号、卡号、客户号等个人信息都需要进行数据脱敏。
数据脱敏系统设计的难点
许多公司页考虑到了这种威胁并且马上着手来处理。简单的将敏感信息从非生产环境中移除看起来很容易,但是在很多方面还是很有挑战的。
首先遇到的问题就是如何识别敏感数据,敏感数据的定义是什么?有哪些依赖?应用程序是十分复杂并且完整的。知道敏感信息在哪并且知道哪些数据参考了这些敏感数据是非常困难的。
敏感信息字段的名称、敏感级别、字段类型、字段长度、赋值规范等内容在这一过程中明确,用于下面脱敏策略制定的依据。
一旦敏感信息被确认,在保持应用程序完整性的同时进行脱敏的方法就是最重要的了。简单地修改数值可能会中断正在测试,开发或升级的应用程序。例如遮挡客户地址的一部分,可能会使应用程序变得不可用,开发或测试变得不可靠。
脱敏的过程就是一个在安全性和可用性之间平衡的过程。安全性是0%的系统中,数据不需要进行脱敏,数据库中都是原来的数据,可用性当然是100%;安全性是100%的系统中,大概所有的数据全都存一个相同的常量才能实现。
所以需要选择或设计一种既能满足第三方的要求,又能保证安全性的算法就变得特别重要了。
选定了敏感数据和要施加的算法,剩下的就是如何实现了,在什么过程中进行脱敏呢?
难题的解决方案
1.如何识别敏感数据
现在有两种方式来识别敏感数据。第一种是通过人工指定,比如通过正则来指定敏感数据的格式,Oracle公司开发的Oracle Data Masking Pack中就使用了这一种方法来指定。
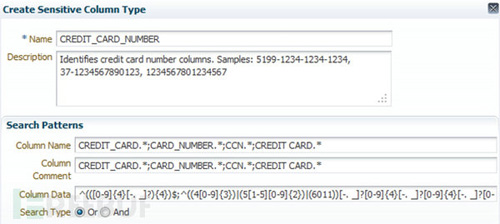
第二种方式就是自动识别了,在文献[2]中,作者给出了基于数据特征学习以及自然语言处理等技术进行敏感数据识别的自动识别方案(没有具体的实现,只提出了模型)。
具体的实现在gayhub上找了一个java实现的工程,chlorine-finder,看了下源码具体原理是通过提前预置的规则来识别一些常见的敏感数据,比如信用卡号,SSN, 手机号,电子邮箱,IP地址,住址等.
2.使用怎样的数据脱敏算法
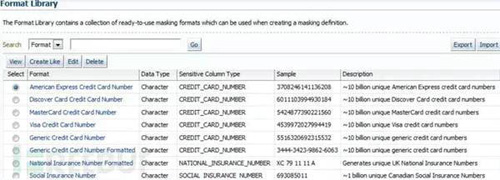
在比较常见的数据脱敏系统中,算法的选择一般是通过手工指定,像Oracal的数据脱敏包中就预设了关于信用卡的数据选择什么算法进行处理,关于电话的数据怎么处理,用户也可以进行自定义的配置。
脱敏方法现在有很多种,比如k-匿名,L多样性,数据抑制,数据扰动,差分隐私等。
k-匿名:
匿名化原则是为了解决链接攻击所造成的隐私泄露问题而提出的。链接攻击是这样的,一般企业因为某些原因公开的数据都会进行简单的处理,比如删除姓名这一列,但是如果攻击者通过对发布的数据和其他渠道获得的信息进行链接操作,就可以推理出隐私数据。
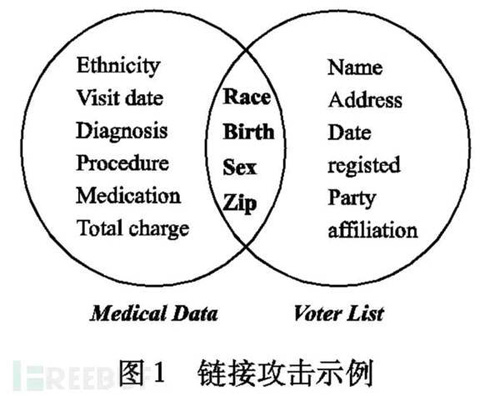
k-匿名是数据发布时保护私有信息的一种重要方法。 k-匿名技术是1998 年由Samarati和Sweeney提出的 ,它要求发布的数据中存在至少为k的在准标识符上不可区分的记录,使攻击者不能判别出隐私信息所属的具体个体,从而保护了个人隐私, k-匿名通过参数k指定用户可承受的最大信息泄露风险。
但容易遭受同质性攻击和背景知识攻击。
L-多样性
L多样性是在k-匿名的基础上提出的,外加了一个条件就是同一等价类中的记录至少有L个“较好表现”的值,使得隐私泄露风险不超过 1/L,”较好表现“的意思有多种设计,比如这几个值不同,或者信息熵至少为logL等等..
但容易收到相似性攻击。
数据抑制
数据抑制又称为隐匿,是指用最一般化的值取代原始属性值,在k-匿名化中,若无法满足k-匿名要求,则一般采取抑制操作,被抑制的值要不从数据表中删除,要不相应属性值用“ ** ”表示。
- >>> s = "CREDITCARD">>> s[-4:].rjust(len(s), "*")'******CARD'
数据扰动
数据扰动是通过对数据的扰动变形使数据变得模糊来隐藏敏感的数据或规则,即将数据库 D 变形为一个新的数据库 D′ 以供研究者或企业查询使用,这样诸如个人信 息等敏感的信息就不会被泄露。通常,D′ 会和 D 很相似,从 D′ 中可以挖掘出和 D 相同的信息。这种方法通过修改原始数据,使得敏感性信息不能与初始的对象联系起来或使得敏感性信息不复存在,但数据对分析依然有效。
Python中可以使用faker库来进行数据的模拟和伪造。
- from faker import Factory
- fake = Factory.create()
- fake.country_code()# 'GE'fake.city_name()# '贵阳'fake.street_address()# '督路l座'fake.address()# '辉市哈路b座 176955'fake.state()# '南溪区'fake.longitude()# Decimal('-163.645749')fake.geo_coordinate(center=None, radius=0.001)# Decimal('90.252375')fake.city_suffix()# '市'fake.latitude()# Decimal('-4.0682855')fake.postcode()# '353686'fake.building_number()# 'o座'fake.country()# '维尔京群岛'fake.street_name()# '姜路'
相关技术有:一般化与删除,随机化,数据重构,数据净化,阻碍,抽样等。
差分隐私
差分隐私应该是现在比较火的一种隐私保护技术了,是基于数据失真的隐私保护技术,采用添加噪声的技术使敏感数据失真但同时保持某些数据或数据属性不变,要求保证处理后的数据仍然可以保持某些统计方 面的性质,以便进行数据挖掘等操作。
差分隐私保护可以保证,在数据集中添加或删除一条数据不会影响到查询输出结果,因此即使在最坏情况下,攻击者已知除一条记录之外的所有敏感数据,仍可以保证这一条记录的敏感信息不会被泄露。
想要体验的同学可以去Havard的Differential Privacy实验室,他们做了一个DP的原型实现.
想要详细了解的同学可以看一下知乎上的这个问题 <点击文末阅读原文查看链接>
关于动态脱敏系统的实现,现在一般有两种,一种是重写数据库程序代码,在权限判决后对请求语句进行重写,从而查询数据;另一种是用户的sql语句通过代理后,代理会对其中关于敏感信息的部分进行语句的替换,并且在返回时会重新包装为与原请求一致的格式交给用户。
总结
经过上面的分析,看来实现一个全自动的准确率高的脱敏系统难度相当大啊,希望自己能够圆满完成任务。
本文作者:佚名
来源:51CTO
