
携程作为国内OTA领头羊,每天都遭受着严酷的欺诈风险,个人银行卡被盗刷、账号被盗用、营销活动被恶意刷单、恶意抢占资源等。
目前携程利用自主研发的风控系统有效识别、防范这些风险。携程风控系统从零起步,经过五年的不断探索与创新,已经可以有效覆盖事前、事中、事后各个环节。也从原来基于“简单规则+DB”,发展到目前能够支撑10X交易增长的智能化风控系统,基于规则引擎、实时模型计算、流式处理、M/R、大数据、数据挖掘、机器学习等的风控系统,拥有实时、准实时的风险决策、数据分析能力。
Aegis系统体系

图1
主要分三大模块:风控引擎、数据服务、数据运算、辅助系统。
风控引擎:主要处理风控请求,有预处理、规则引擎和模型执行服务,风控引擎所需要的数据是由数据服务模块提供的。
数据服务:主要有实时流量统计、风险画像、行为设备数据、外部数据访问代理,RiskGraph。数据访问层所提供的数据都是由数据计算层提供
数据运算:主要包括风险画像运算、RiskSession、设备指纹、以及实时流量、非实时运算。
数据运算所需的数据来源主要是:风控Event数据(订单数据、支付数据),各个系统采集来的 UBT、设备指纹、日志数据等等。
除了这些,风控平台还有非常完善的监控预警系统,人工审核平台以及 报表系统。
Aegis系统架构
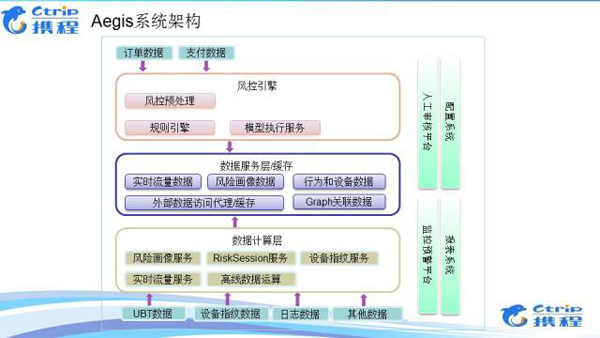

图2
规则引擎
规则引擎包含3大功能,首先是适配层。
由于携程的业务种类非常多,而且每种业务都有其特性,在进入风控系统(Aegis)后,为了便于整个风控系统对数据进行处理,风控前端有一个适配器模块,把各个业务的数据都按照风控内部标准化配置进行转换,以适合风控系统使用。
在完成数据适配后。风控系统要进行数据的合并。
举个例子,当有一笔支付风控校验,支付BU只抛过来支付信息(支付金额、支付方式、订单号等)。但是不包含订单信息,这个时候就必须根据支付信息快速的查找到订单信息,并把这两个数据进行合并,以便规则、模型使用。大家知道,用户从生成订单到发起支付,其时间间隔从秒到天都有可能,当间隔时间短的时候,就会发生要合并的数据还没有处理完,所以订单数据从处理到落地要非常快。第二部就是要快速查找到订单数据,我们为订单信息根据生成 RiskGraph,可以快速精确定位到所需要的订单明细数据。
预处理在完成数据合并后,就开始准备规则、模型所需要的变量、tag数据,在准备数据时,预处理模块会依赖后面我们要讲解的数据服务层。当然,为了提高性能,我们为变量、tag的数据合理安排,优先获取关键规则、模型所需要的变量、tag的数据。
大家知道,欺诈分子的特点就是一波一波的,风控系统需要能够及时响应,当发现欺诈行为后,能及时上规则防止后续类似的欺诈行为。所以,制定规则需要快速、准确,既然这样,那么就需要我们的规则能够快速上线,而且规则人员自己就可以制定规则并上线。还有就是规则与执行规则的引擎比较做到有效隔离,不能因为规则的不合理,影响到整个引擎。那么规则引擎就必须符合这些条件。
我们最后选择了开源 Drools,第一它是开源,第二它可以使用Java语言,入门方便,第三功能够用。 通过使用 规则引擎Drools,使其具有非常高的灵活性、可配置性,并且由于是java语法的,规则人员自己就可以制定规则并迅速上线。
由于每个风控Event请求,都需要执行数百个规则,以及模型,这时,风控引擎引入了规则执行路径优化方法。建立起并行+串行,依赖关系+非依赖关系的规则执行优化方法,然后再引入短路机制,使上千个规则的运行时间控制在100ms。
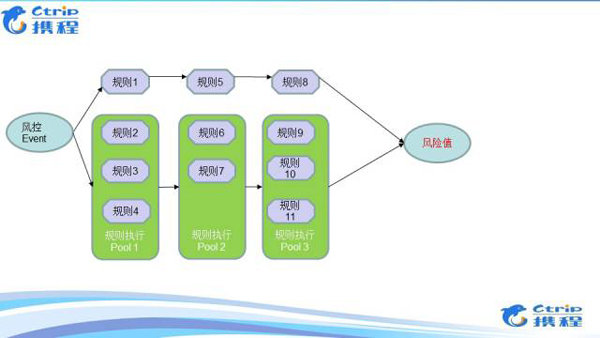
图3
规则的灵活性非常强,制定、上线非常快,但是单个规则的覆盖率比较低,如果要增加覆盖率就需要非常多的规则来进行覆盖,这个时候规则的维护成本就会很高,那么这个时候就需要使用模型了,模型的特点就是覆盖率覆盖率可以做到比较高,其模型逻辑可以非常复杂,但是其需要对其进行线下训练,所以携程风控系统利用了规则、模型的各自特点进行互补。
在目前的风控系统中主要使用了:Logistic Regression、Random Forest。两个算法使用下来,目前情况为:LR训练变量区分度足够好的情况下,加以特征工程效果比较好。RF当变量线性区分能力较弱的时候,效率比较高。所以使用RF的比例比较多。
数据服务层
数据服务层,主要功能就是提供数据服务,我们知道在风控引擎预处理需要获取到非常多的变量和tag,这些变量和tag的数据都是由数据访问层来提供的。该服务层的最重要的目的就是响应快。所以在数据服务层主要使用Redis作为数据缓存区,重要、高频数据直接使用Redis作为持久层来使用。
数据服务层的核心思想就是充分利用内存(本地、Redis)
1、本地内存(大量固定数据,如ip所在地、城市信息等)
2、充分利用Redis高性能缓存
由于实时数据流量服务、风险画像数据服务的数据是直接存储在Redis中,其性能能够满足规则引擎的要求,我们这里重点介绍一下数据访问代理服务。
数据访问代理服务,其最重要的思想就是该数据被规则调用前先调用第三方的服务,把数据保存到Redis中,这样当规则请求来请求的时候,就能够直接从Redis中读取,既然做到了预加载,那么其数据的新鲜度及命中率就非常重要。我们以用户相关维度的数据为例,风控系统通过对用户日志的分析,可以侦测到哪些用户有登陆、浏览、预定的动作,这样就可以预先把这些用户相关的外部服务数据加载到Redis中,当规则、模型读取用户维度的外部数据时,先直接在redis中读取,如果不存在然后再访问外部服务。
在某些场景下,我们还结合引入DB来做持久化,当用户某些信息发生变化的时候,公共服务会发送一个Message到Hermes,我们就订阅该信息,当知道该用户的某些信息发生修改,我们就主动的去访问外部服务获取数据放入Redis中,由于风控系统能够知道这些数据发生变化的Message,所以这些数据被持久化到DB中也是ok的,当然,这些数据也有一个TTL参数来保证其新鲜度。在这种场景下,系统在Redis没有命中的情况下,先到DB中查找,两个地方都不存在满足条件的数据时,才会访问外部服务,这个时候,其性能、存储空间就可以得到优化。
Chloro系统Chloro系统是数据分析服务也是整个风控系统的核心,数据服务层所使用到的数据,都是由Chloro系统计算后提供的。
主要分析维度主要包括:用户风险画像,用户社交关系网络,交易风险行为特性模型,供应商风险模型。
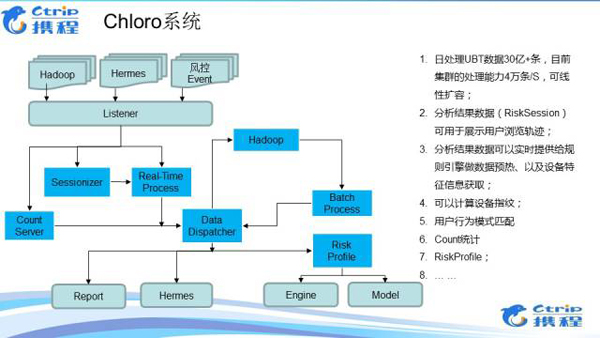
图4
可以看到数据的来源主要有hermes、hadoop、以及前端抛过来的各种风控Event数据。Listener是用来接收各类数据,然后数据就会进入 CountServer 和 Real-Time Process系统,其中和RiskSession的数据就先进入Sessionizer ,该模块可以快速进行归约Session处理,根据不同的key归约成一个session,然后再提交给 实时处理系统进行处理。
当Real Time Process 和 CountServer对数据处理好后,这个时候分成了两部分数据,一部分是处理的结果,还有一份是原数据,都会提交给Data Dispatcher,由它进行Chloro系统内部的数据路由,结果会直接进入到RiskProfile提供给引擎和模型使用。而原始数据会写入到Hadoop集群。
Batch Process就利用Hadoop集群的大数据处理能力,对离线数据进行处理,当Batch Process处理好后,也会把处理结果发送给Data Dispatcher,由它进行数据路由。
Batch Process还可以做跨Rsession之间的数据分析。

图5
RiskSession的定义:量化、刻画 用户的行为,任何人通过任何设备访问携程的第一个event开始,我们认为Rsession start了,到他离开的最后一个event后30分钟之内没有任何痕迹留下,我们认为Rsession end。
风控系统通过比较用户信息:Uid, 手机号, 邮箱,设备信息:Fp(Fingerprint), clientId, vid, v, deviceId来判断其是否是同一个用户,通过其行为信息:浏览轨迹, 历史轨迹来判断其行为相似度。
比如:用户在PC端下单、然后在手机APP里完成支付,这个对于Chloro是一个会话,这个会话我们称之为风控Session,通过Risksession的定义,风控系统使用户的行为可以量化,也可以刻画。这样Risksession实际上可以作为用户行为的一个 Container。使用RiskSession就可以做到跨平台,更加有利于分析用户特征。
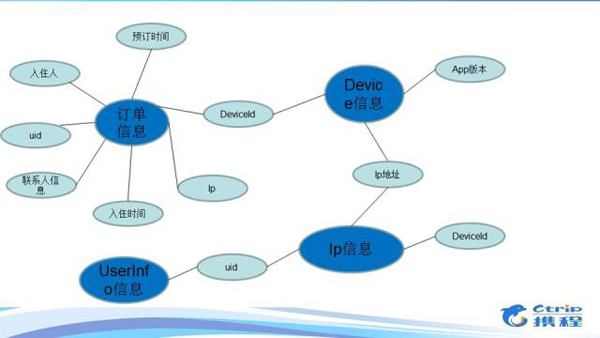
图6
Risk Graph 是根据携程风控系统的特点开发出来的,Risk Graph是一个基于HBase进行为存储介质的系统,比如,以用户为节点其值就是HBase用户表的key,其每个列就是特性,然后根据用户的某个特性再创建一个hbase表,这样就创建了一个基于HBase的类Graph的架构。
所以该系统的一个核心思想是先创建各个维度的数据索引,然后根据索引值再进行内容的查找。目前风控系统已经创建了十几个维度的快速索引。
Aegis其它子系统

图7
Aegis还有配置系统,用户可以在上面进行各种配置,如规则、规则运行路径,标准化、tag、变量定义、已经数据清洗业务罗辑等等,当然监控系统也是非常重要的,风控研发秉承着监控无处不在的设计理念,使其能够在第一时间发现系统的任何细小变化。
展望
携程风控在3.0中通过引入规则引擎、在Chloro系统中大量使用开源的基于大数据处理的架构,配合模型取得了非常好的效果,在4.0中,将在机器学习、人工智能、行为特征等方向继续发力,进一步提高风控系统识别能力,对于技术将继续拥抱开源技术,下一步会引入Spark等提高风控系统的数据处理能力。
本文作者:郁伟
来源:51CTO
