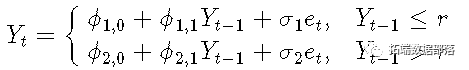热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
C语言中大小写字母的转化
客户关系智慧:CRM系统五大功能助力企业发展
R语言时间序列TAR阈值自回归模型(下)
Python语法高亮库Pygments
深度学习赋能智能监控:图像识别技术的革新与应用
R语言时间序列TAR阈值自回归模型
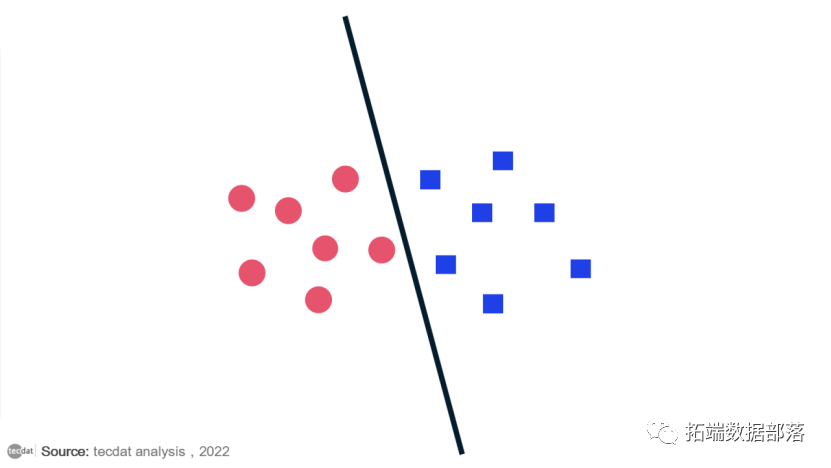
【视频】支持向量机SVM、支持向量回归SVR和R语言网格搜索超参数优化实例
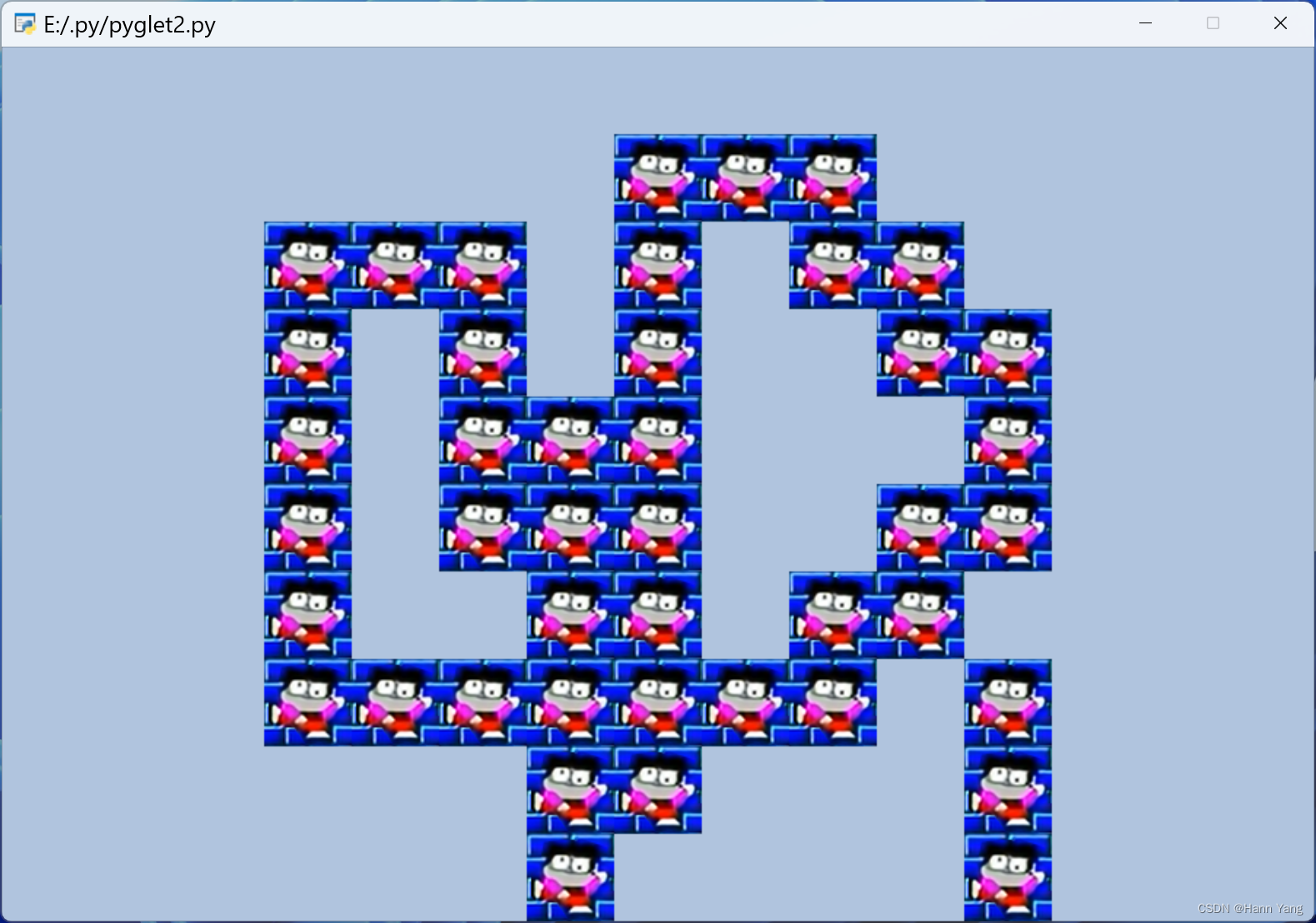
Pyglet综合应用|推箱子游戏之关卡图片载入内存
超级实用的python代码片段汇总和详细解析(16个)(下)
R语言中使用多重聚合预测算法(MAPA)进行时间序列分析
七人拼团互助模式开发系统方案搭建
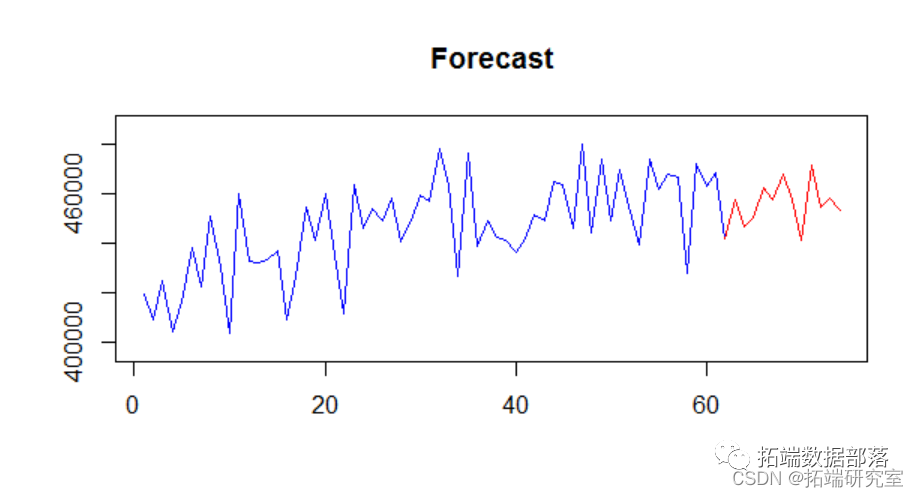
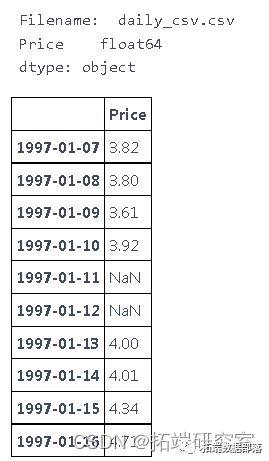
数据分享|PYTHON用KERAS的LSTM神经网络进行时间序列预测天然气价格例子
网络防线的构筑者:深入网络安全与信息保护
【牛客网算法】NP17 生成列表
区块链技术在供应链管理中的应用
超级实用的python代码片段汇总和详细解析(16个)(上)
探索人工智能在医疗诊断中的应用
【视频】Copula算法原理和R语言股市收益率相依性可视化分析(下)
【牛客网算法】NP16 发送offer
【牛客网算法】NP15 截取用户名前10位
网络安全与信息安全:防御前线的技术与意识
【视频】Copula算法原理和R语言股市收益率相依性可视化分析(上)
【牛客网算法】NP13 格式化输出(三)
代码之美:从功能实现到艺术创作
【牛客网算法】NP4 格式化输出(二)答案
Spring Cloud 常用各个组件详解及实现原理(附加源码+实现逻辑图)
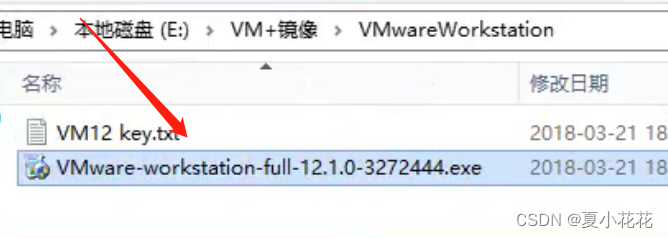
Vmware workstation 安装教程
vue 动态改变css样式
css flex布局两个元素水平居中垂直居中
swiper 去掉轮播图上的小点点 小圆圈(完美解决方案)
uniapp读取(获取)缓存中的对象值(微信小程序)
css 设置div阴影样式
css 设置无背景色
mybatis 调用修改SQL时 出现了一个问题 没有修改成功也没有报错
R语言单变量和多变量(多元)动态条件相关系数DCC-GARCH模型分析股票收益率金融时间序列数据波动率
vue element ui 打开弹窗出现黑框问题
python文件读写操作的三大基本步骤
数据分享|逻辑回归、随机森林、SVM支持向量机预测心脏病风险数据和模型诊断可视化(下)
怎样使用Pyglet库给推箱子游戏画关卡地图
数据分享|逻辑回归、随机森林、SVM支持向量机预测心脏病风险数据和模型诊断可视化(上)
初步探索Pyglet库:打造轻量级多媒体与游戏开发利器
数据分享|R语言逻辑回归(Logistic Regression)、回归决策树、随机森林信用卡违约分析信贷数据集
python常用pandas函数nlargest / nsmallest及其手动实现
Centos7安装docker并部署halo建站
掌握Spring Boot中的@Validated注解
【视频】风险价值VaR原理与Python蒙特卡罗Monte Carlo模拟计算投资组合实例