1)报警配置信息的录入
这部分比较简单,就是一个简单的管理系统
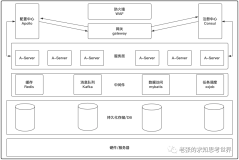
架构如下所示: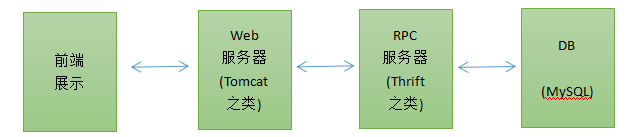
配置信息具体要存什么,看你自己需要,每个人有自己的想法
我之前的思路是:
(0)定义本配置所属的服务,比如web服务,rpc服务,cache缓存服务,mq服务,sql服务。
(1)定义一个采样次数的总数,比如10次采样样本为一次计算单位。
(2)定义一个采样样本不过关的次数,比如4次,也就是10次里面有4次样本不过关就报警。
(2.1)单个样本里的成功率必须>=某个阀值
(2.2)单个样本里的平均耗时必须<=某个阀值
(2.3)单个样本里的最大耗时必须<=某个阀值(可选)
(2.4)单个样本里的最小耗时必须<=某个阀值(可选)
(2.5)单个样本里的TP99数值必须<=某个阀值(可选)
(2.6)其它,你想怎么做就怎么做,规则你自己定,你就是规则之王。
(3)报警周期,就是后面如果报警,多少时间之内同种类型的不再报警,如果你不需要就设置为0,那么有多少报警都会发出去,造成报警短信洪灾。
单个样本到底是啥意思? 客户端调用埋点jar包里的API,会调用很多次,然后如果你定义了6秒钟收割一次进行数据采样汇总,上传到服务器,那就是一个采样样本。
PS:如果在这6秒钟某个API被调用1万次,成功6000次,那么只会上报一条数据给远程服务器,
类似于{key,10000,6000,...其它信息},要弄清楚这个概念,绝对不会上报1万条数据给远程服务器。
好,到此,针对每种服务的报警标准都已经存在mysql数据库了。
有的时候,用户(单位内部各个业务系统)会说,我需要每种服务的参数都要定制,那么你需要自己扩充这些达到定制的需求,
还有说我针对时间段的需求要定制,我针对每个URL的参数要定制,这个你自己举一反三就可以了。
2)业务统计信息上报 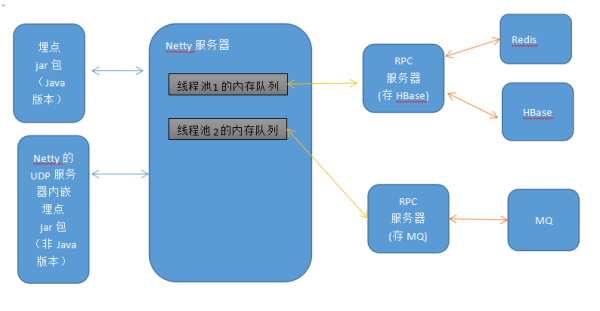
这部分代码在client_metrics里已经实现了,花时间看一下就知道设计思路。
上报的时候要包含以下一些信息
{产品,所属服务,机器ID,key,total调用次数,成功次数,平均耗时,最大耗时,最小耗时,TP99...等其它你想要的信息}
这里解释一下前4个字段的意思。
举个例子:
产品:公司金融产品
服务:因为这个产品会包含一些http服务啊,rpc服务啊,缓存服务啊,sql服务啊,所以你要标记出来。
机器ID:就算你指定了rpc服务,你不会只部署一台吧,你肯定有多台,那你得指定是哪一台啊,不然不知道发生在哪台机器上啊,这个你可以写一个
静态函数获取,比如我们采用了发送时获取{ip:本进程监听端口}这样,以后就不再重新获取,复用这个值。
key:针对http服务,就是你的url; 针对redis服务,就是你的命令;以http服务为例,你的url如果有变化的参数,你要写成模板类型的值,不然key的个数
发生爆炸,比如http://ip:port/a/1/b 这样的,里面的1会发生变化,你不能直接把这个作为key,你得写成http://ip:port/a/xxx/b,大概就这个意思。
有的人说埋点你不能影响我的业务速度,不能影响我的内存,这个在设计时候都要考虑
还有如果监控的数据接收服务器全部宕机了,也不能影响业务,这个请自己看client_metrics,看完了就知道大体思路了,如果你觉得可以优化得更好你自己优化吧。核心思想是异步上传,容许一段时间的数据不是100%准确(发生在所有远程数据接收服务器全部宕机的前提下)
另外我们当时做数据汇总时,以web为例,web可能会有几十个URL的数据,我们上传时就已经做了所有数据的一个综合统计,比如所有url的调用次数,平均耗时,这样后面如果你要看这些数据,直接用这些数据作为计算基础就可以了。
然后我们还做了一个掉0检测,就是如果某个新的key第一次出现时,我们在内存中记住了它,如果它在某个采样周期内没有出现,我们就会上报这个key的数据为0,有些场合可以用来做掉零检测。
另外如果你不是java语言的程序,怎么埋点?一个可行的是你用Netty写一个UDP服务器,内部嵌套上面的java jar包,本质上是做了一个代理
然后所有程序发送UDP数据给你,这里可以优化,思路你自己想,(maybe QUIC协议你可以调研一下)
好,数据到了Netty服务器之后,这里是HTTP协议上报的哈,为什么要一份为2,一式2份呢?
目的是为了数据上传入HBase和数据入MQ互相不干扰,也就是说,hbase全部宕机不影响数据进MQ,MQ全部宕机不影响数据入hbase.
hbase:用来存储海量历史数据,这样如果你收到了报警信息,你可以查啊,调出那个时候的数据看是不是真的有问题,用于历史回溯。
mq: 用于存数据,作为实时计算的数据源啊,不然谁来发送报警短信和邮件呢?
然后hbase那里有一个redis.这个是干嘛的?因为每个数据里面的产品我可以实现定义在配置库里,但是服务,机器ID,key这些是完全动态的啊
所以每一条数据来了后,要需要先查redis是否存在,不存在的话,要相应的维护到hbase里的表里,这样慢慢构建好这个产品的这些信息,回头在界面上才可以调出来。所以redis就是起加速作用,不然每一条信息来了,你也不知道服务和机器id,key是不是已经存在了的,然后插入到hbase,很慢啊,量大了你肯定扛不住。
3)报警信息实时计算 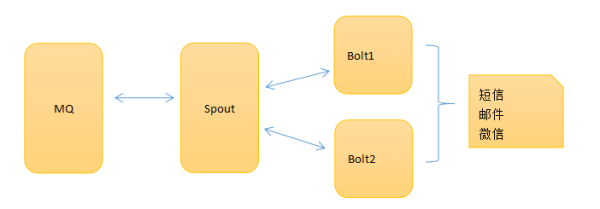
具体的技术很多,storm,flink,heron都可以的,你熟悉哪个用哪个。
保证同一个[产品,服务,机器ID]的数据肯定是到同一个bolt就行,这样才好做计算,否则如果分散了,那就不好计算了。
计算的标准怎么拿?从步骤1的报警配置信息库里拿啊,所以每个bolt启动时从sql库里拿,
建议在1)的架构里开一个HTTP API接口,这样bolt每次启动前初始化先拿取相关的配置信息,然后后面定时拉取更新本地配置
这样你如果修改了配置信息,自然会更新到bolt里,不用重启storm程序。
实际上有很多需要注意的细节
比如如果HTTP接口调用失败怎么办,那就继续保持原有的配置信息不需要替换。
如果新的配置跟老的配置有冲突怎么办,比如老的是10条数据有6次失败就报警,目前已经有了8条数据,还差2条,然后刷新了新的报警配置是6条数据3次失败就报警
,你怎么解决就看你自己了,合理就行。
我们当时做报警邮件的时候,邮件内容一部分是用户定的报警标准,下面是每一条信息的具体数值,然后告诉你这条数据是否达标。
(死也得让你知道为啥死的 :)
这里报警的时候,就用到了你的参数里的报警周期,这个参数怎么用?比如你定义[产品,服务,机器ID]这个组合1分钟只能报警1次,假设服务是web的话,就算有很多个URL都报警了,我也只会在这1分钟内报警1次,具体怎么玩你自己定,否则业务一下子收到几十个报警短信,他会觉得很无助,其实也没必要发这么多条,你懂我的意思就好。游戏规则自己定吧。
注意每一个细节,力求完美。
4)最终的架构图
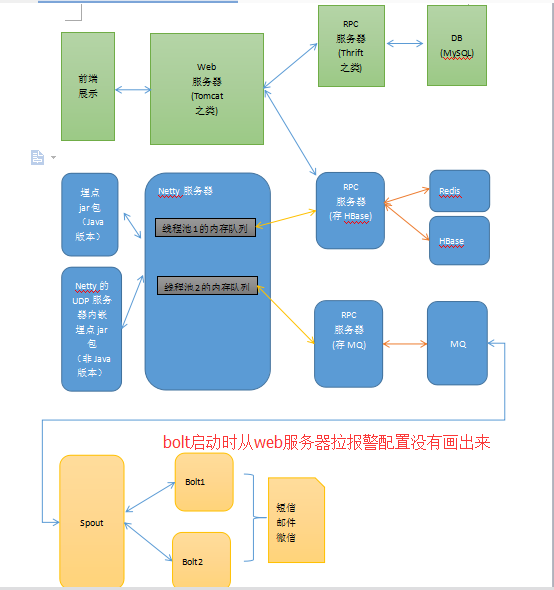
最终完整的架构图如上所示。
5)细节和性能分析
有人会问,如果业务越来越多,我怎么知道我的监控系统是否要扩容?
很简单,你把2)步骤里面的netty服务器里面的2个内存队列的size做监控信息采集,同样上报给后端,同时在1)里面设置好报警参数
也就是你做了一个自监控,一旦内存队列的size超过了阀值,说明输入的速度>输出的速度啊,嗯,跟老板申请扩容吧
可以是加web服务器,也可以是提高后面的处理速度,自己分析吧。
招一个好一点的大数据人员,维护好hbase,storm这些,这套系统就可以水平扩展了,
不管你一天有多少T的数据量,照单全收,毫无压力。
另外附上我们之前生产环境的数值:每天300G数据,没办法,不是大公司,没这么多的产品,而且很多中台产品都是1分钟上报1次,频率有点低,其实几秒钟上报1次都是可以的,这样很快可以发现哪个业务出了问题,也可以做到秒级感知啊 :) 。
PS:因为时间有限,最近在研究别的东西,这个项目的代码不会经常更新,附上架构图给各位网友,
以此为蓝本,加上你的自由发挥的能力,没问题。
另外有兴趣做HDFS数据入库的可以看看我的另外一个项目MyHDFS,从前同事得知最新的数据是 5000万条数据/单日(其实写几个亿丝毫没有问题)
附录:
http://git.oschina.net/qiangzigege/MyEye 里面谈到了每种技术具体可以用的技术选型,就看你熟悉哪个了
http://git.oschina.net/qiangzigege/MyHDFS
大牛很多,只敢抛砖引玉,肯定有设计不当和不周的地方,还请各位大牛轻喷,谢谢!
MyEye官方讨论群 120734278 想做监控的可以内部自由讨论。
另外最近看到阿里的监控,除了常规数据统计和报警外,给我印象最深的是智能监控,我只能说阿里人才就是多啊 :)
这套系统是15年9月份开始写的第一行代码,15年10月中旬第1版上线使用,只花了1个半月。
我做总体架构设计和API设计,物理库设计,code review,只有1个小弟负责代码编写.
当时2个人没有任何杂念的全身心投入到这个产品中,经常回家都在思考白天的代码有没有问题。这段时间也是很怀念的。其实在做这个监控系统之前我从来没有做过监控,当时领导让我设计监控的时候我真是一脸懵逼,到处问人有没有经验可以借鉴,问了一圈发生公司没有任何一个人可以帮到我,于是定下心来自己完全琢磨每个细节该怎么设计,开发过程中小弟也提出来一些很好的建议,后来发现一些想法在别的开源软件中也是存在的,所以说这个系统没有参考任何一款软件,最后开发出来并且非常平稳的运行了1年半时间我还是挺高兴的。
实际上,公司内部任何需要监控的信息点,只要稍微转换下,都可以用同一个API来上报信息
所以我们当时也做了平台部门MQ消息中间件的负载监控,大数据部门的信息采集指标健康监控。
https://my.oschina.net/qiangzigege/blog/600441
是当时给公司上面汇报用的PPT。
后记: 当时做完这套监控系统的时候,压根还不知道有调用链这个东西的存在,也没有领导和同事提出这个需求,否则当时肯定也直接给加上去了,后来把zipkin的源码翻完之后才发现调用链比做监控更简单,以后有时间再讲讲调用链的本质以及以 zipkin为例子如何上报调用信息。
作者:强子哥哥
来源:51CTO