大数据的生态系统如今已经非常庞大,涌现大量主流数据处理框架如Hadoop、Spark、Flink、Google的Tensorflow以及其他不计其数的Apache开源项目(最受欢迎的十个开源大数据技术)。
今天我们要推荐的五个“非主流”开源大数据技术项目,在某些特定的应用场合,往往能助您出奇制胜。
一、Luigi
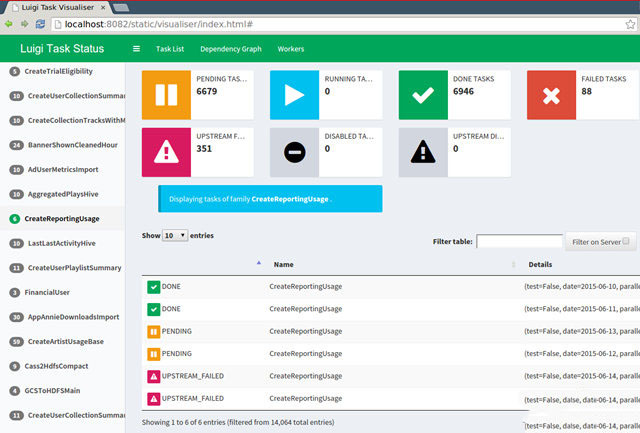
Luigi是Spotify开发的数据管线批处理工具,热度正在不断飙升。Luigi的定位不是取代底层数据处理工具如Hive或者Pig,而是在众多任务间创建工作流。Luigi原生支持Hadoop,这对于很多用户来说非常有吸引力。
近日创业公司Mortar就将Spotify开发的开源大数据工具Luigi搬上云端,在亚马逊云上提供复杂的,涉及大量工具和数据库的大数据流水线处理服务,不论是否使用Hadoop,用户都可以用Luigi管理复杂的大数据工作流。
二、Lumify
Lumify是一个开源大数据分析和可视化平台,开发者Altamira认为当前的大数据分析工具并不完善,因此开发了Lumify来聚合、管理和洞察数据,此外,Lumify还可以用来分析数据内部之间的关系,进行地理图形数据分析,并实时组织和协调数据。Lumify的官网由比较完整的文档和介绍视频,还提供了了一个在线应用示例。
三、Google 云平台Hadoop互操作工具

这个技术项目来自Google Cloud Platform的官方Github账号,描述如下:
为实现Hadoop相关开源软件、Google云平台之间互操作的代码库和工具集。如果你打算在Google云平台上运行基于HDFS数据的Map-Reduce任务,那么这些工具值得投资。
四、Presto

Presto是一个分布式的大数据SQL查询引擎,支持所有数据源格式,以及从GB到PB级别的数据规模。Presto主打的卖点是速度和可扩展性,如果你想提升SQL查询速度又不愿对数据源存储系统进行投资或改动,或者需要对存储在多个平台的数据源进行查询,Presto都是值得考虑的选择。Presto的官网由比较详细的资料,这里还有一个Teradata的五分钟视频介绍(youtube),以及Facebook的Presto设置应用指南(youtube)。
五、Clusterize
来自Denis Lukov的这个项目是今天介绍的“非主流”中的非主流,与前面介绍的四个后端数据科学/工程工具不同,Clusterize是一个Javascript写成的前端开发小项目,目的是提高大数据集的浏览效率,降低延迟,这算得上是一个大数据工具吗?也许吧,至少对于很多开发者来说是如此。
本文作者:Cashcow
来源:51CTO




