本文章我们使用hadoop2.6.0版本配置Hadoop集群,同时配置NameNode+HA、ResourceManager+HA,并使用zookeeper来管理Hadoop集群。
1.1 写在前面的话
1.2 (一)HDFS概述
1.2.1 基础架构
1、NameNode(Master)
1)命名空间管理:命名空间支持对HDFS中的目录、文件和块做类似文件系统的创建、修改、删除、列表文件和目录等基本操作。
2)块存储管理。
1.2.2 HA架构
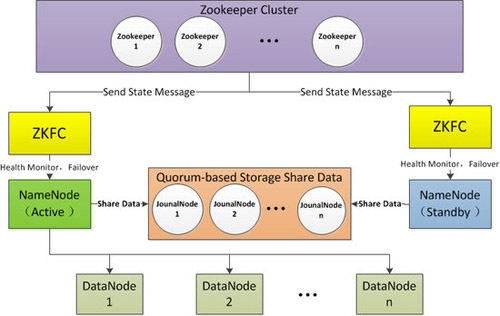
从上面的架构图可以看出,使用Active NameNode,Standby NameNode 两个节点可以解决单点问题,两个节点通过JounalNode共享状态,通过ZKFC 选举Active ,监控状态,自动备份。
1、Active NameNode
接受client的RPC请求并处理,同时写自己的Editlog和共享存储上的Editlog,接收DataNode的Block report, block location updates和heartbeat。
2、Standby NameNode
同样会接到来自DataNode的Block report, block location updates和heartbeat,同时会从共享存储的Editlog上读取并执行这些log操作,保持自己NameNode中的元数据(Namespcae information + Block locations map)和Active NameNode中的元数据是同步的。所以说Standby模式的NameNode是一个热备(Hot Standby NameNode),一旦切换成Active模式,马上就可以提供NameNode服务。
3、JounalNode
用于Active NameNode , Standby NameNode 同步数据,本身由一组JounnalNode节点组成,该组节点奇数个。
4、ZKFC
监控NameNode进程,自动备份。
1.3 (二)YARN概述
1.3.1 基础架构
1、ResourceManager(RM)
接收客户端任务请求,接收和监控NodeManager(NM)的资源情况汇报,负责资源的分配与调度,启动和监控ApplicationMaster(AM)。
2、NodeManager
节点上的资源管理,启动Container运行task计算,上报资源、container情况汇报给RM和任务处理情况汇报给AM。
3、ApplicationMaster
单个Application(Job)的task管理和调度,向RM进行资源的申请,向NM发出launch Container指令,接收NM的task处理状态信息。
4、Web Application Proxy
用于防止Yarn遭受Web攻击,本身是ResourceManager的一部分,可通过配置独立进程。ResourceManager Web的访问基于守信用户,当Application Master运行于一个非受信用户,其提供给ResourceManager的可能是非受信连接,Web Application Proxy可以阻止这种连接提供给RM。
5、Job History Server
NodeManager在启动的时候会初始化LogAggregationService服务, 该服务会在把本机执行的container log (在container结束的时候)收集并存放到hdfs指定的目录下. ApplicationMaster会把jobhistory信息写到hdfs的jobhistory临时目录下, 并在结束的时候把jobhisoty移动到最终目录, 这样就同时支持了job的recovery.History会启动web和RPC服务, 用户可以通过网页或RPC方式获取作业的信息。
1.3.2 HA架构
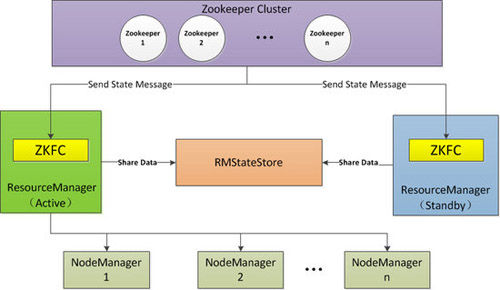
ResourceManager HA 由一对Active,Standby结点构成,通过RMStateStore存储内部数据和主要应用的数据及标记。目前支持的可替代的RMStateStore实现有:基于内存的MemoryRMStateStore,基于文件系统的FileSystemRMStateStore,及基于zookeeper的ZKRMStateStore。 ResourceManager HA的架构模式同NameNode HA的架构模式基本一致,数据共享由RMStateStore,而ZKFC成为 ResourceManager进程的一个服务,非独立存在。
本文作者:佚名
来源:51CTO
