颠覆大数据分析之Mesos:集群调度及管理系统
译者:黄经业 购书
正如前面“Mesos:动机”一节中所述,Mesos的主要目标就是去帮助管理不同框架(或者应用栈)间的集群资源。比如说,有一个业务需要在同一个物理 集群上同时运行Hadoop,Storm及Spark。这种情况下,现有的调度器是无法完成跨框架间的如此细粒度的资源共享的。Hadoop的YARN调度器是一个中央调度器,它可以允许多个框架运行在一个集群里。但是,要使用框架特定的算法或者调度策略的话就变得很难了,因为多个框架间只有一种调度算法。比如说,MPI使用的是组调度算法,而Spark用的是延迟调度。它们两个同时运行在一个集群上会导致供求关系的冲突。还有一个办法就是将集群物理拆分成多个小的集群,然后将不同的框架独立地运行在这些小集群上。再有一个方法就是为每个框架分配一组虚拟机。正如Regola和Ducom所说的,虚拟化被认为是一个性能瓶颈,尤其是在高性能计算(HPC)系统中。这正是Mesos适合的场景——它允许用户跨框架来管理集群资源。
集群上同时运行Hadoop,Storm及Spark。这种情况下,现有的调度器是无法完成跨框架间的如此细粒度的资源共享的。Hadoop的YARN调度器是一个中央调度器,它可以允许多个框架运行在一个集群里。但是,要使用框架特定的算法或者调度策略的话就变得很难了,因为多个框架间只有一种调度算法。比如说,MPI使用的是组调度算法,而Spark用的是延迟调度。它们两个同时运行在一个集群上会导致供求关系的冲突。还有一个办法就是将集群物理拆分成多个小的集群,然后将不同的框架独立地运行在这些小集群上。再有一个方法就是为每个框架分配一组虚拟机。正如Regola和Ducom所说的,虚拟化被认为是一个性能瓶颈,尤其是在高性能计算(HPC)系统中。这正是Mesos适合的场景——它允许用户跨框架来管理集群资源。
Mesos是一个双层调度器。在第一层中,Mesos将一定的资源提供(以容器的形式)给对应的框架。框架在第二层接收到资源后,会运行自己的调度算法来将任务分配到Mesos所提供的这些资源上。和Hadoop YARN的这种中央调度器相比,或许它在集群资源使用方面并不是那么高效。但是它带来了灵活性——比如说,多个框架实例可以运行在一个集群里。这是现有的这些调度器都无法实现的。就算是Hadoop YARN也只是尽量争取在同一个集群上支持类似MPI这样的第三方框架而已。更重要的是,随着新框架的诞生,比如说Samza最近就被LinkedIn开源出来了——有了Mesos这些新框架可以试验性地部署到现有的集群上,和其它的框架和平共处。
Mesos组件
Mesos的关键组件是它的主从守护,正如图2.5所示,它们分别运行在Mesos的主节点和从节点上。框架或者框架部件都会托管在从节点上,框架部件包括两个进程,执行进程和调度进程。从节点会给主节点发布一个可用资源的列表。这是以<2 CPU,8GB内存>列表的形式发布的。主节点会唤起分配模块 ,它会根据配置策略来给框架分配资源。随后主节点将资源分配给框架调度器。框架调度器接收到这个请求后(如果不满足需求的话,也可能会拒绝它),会将需要运行的任务列表以及它们所需的资源发送回去。主节点将任务以及资源需求一并发送给从节点,后者会将这些信息发送给框架调度器,框架调度器会负责启动这些任务。集群中剩余的资源可以自由分配给其它的框架。接下来,只要现有的任务完成了并且集群中的资源又重新变为可用的,分配资源的过程会随着时间不断地重复。需要注意的是,框架不会去说明自己需要多少资源,如果无法满足它所请求的资源的话,它可以拒绝这些请求。为了提高这个过程的效率,Mesos让框架可以自己设置过滤器,主节点在分配资源之前总会首先检查这个条件。在实践中,框架可以使用延迟调度,先等待一段时间,待获取到持有它们所需数据的节点后再进行计算。
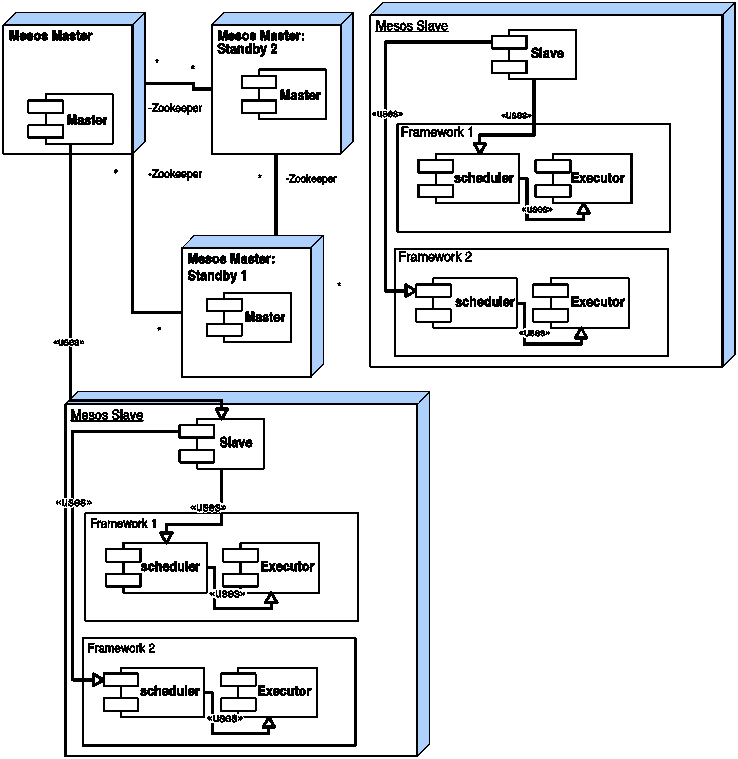
图2.5 Mesos的架构
一旦资源分配好了,Mesos会立即提供给框架。框架响应这次请求可能会需要一定的时间。这得确保资源是加锁的,一旦框架接受了这次分配后资源是立即可用的。如果框架长时间没有响应的话,资源管理器(RM)有权撤销这次分配。
资源分配
资源分配模块是可插拔的。目前一共有两种实现——一种是Ghodsi等人(2011)提出的主导资源公平(Dominant Resource Fairness, DRF)策略。Hadoop中的公平调度器(https://issues. apache.org/jira/browse/HADOOP-3746)会按照节点的固定大小分区(也被称为槽)的粒度来分配资源。这样做的效率会差,尤其是在现代的多核处理器的异构计算环境中。DRF是最小-最大公平算法在异构资源下的一个泛化。需要注意的是,最大最小算法是一个常见的算法,它拥有许多变种比如循环以及加权公平排队,但它通常都用于同类的资源。DRF算法会确保在用户的主导资源中使用最大最小策略。(CPU密集型作业的主导资源是CPU,而IO密集型作业的主导资源则是带宽)。DRF算法中的一些有趣的特性列举如下:
- 它是公平的,并且吸引用户的一点是,它能保证如果所有资源都是静态平均分布的话,不会偏向任何一个用户。
- 用户谎报资源需求没有任何好处。
- 它具有帕累托效率,从某种意义上来说,系统资源利用率最大化且服从分配约束。
框架可以通过API调用获取到保证分配给它们的资源大小。当Mesos必须要杀掉一些用户任务的时候,这个功能就很有用了。如果框架分配的资源在确保的范围内的话,它的进程就不会被Mesos杀掉,如果超出了阈值,Mesos就会杀掉它的进程。
隔离
Mesos使用Linux或者Solaris容器提供了隔离功能。传统的基于hypervisor的虚拟化技术,比如基于内核的虚拟机(KVM),Xen(Barham等2003),或者VMware,都是由基于宿主操作系统实现的虚拟机监控器组成的,这个监控器提供了虚拟机所有的硬件仿真。如此说来,每个虚拟机都有自己专属的操作系统,这是和其它虚拟机完全隔离开来的。Linux容器的方式是一种被称为操作系统级虚拟化的技术。操作系统级虚拟化会使用隔离用户空间实例的概念来创建一个物理机器资源的分区。本质上而言,这种方法则不再需要基于hypervisor的虚拟化技术中所需的客户操作系统了 。也就是说,hypervisor工作于硬件抽象层,而操作系统级虚拟化工作于系统调用层。然而,给用户提供的抽象是指每个用户空间实体都会运行自己八专属的独立的操作系统。操作系统级虚拟化的不同实现会略有不同,Linux-VServer是工作于chroot之上的,而OpenVZ则是工作于内核命名空间上。Mesos使用的是LXC,它通过cgroups(进程控制组)来进行资源管理,并使用内核命名空间来进行隔离。Xavier等人(2013)对它做了一份详细的性能评估报告,结果如下:[1]
- 从测试CPU性能的LINPACK基准测试(Dongarra 1987)来看,LXC的方式要优于Xen。
- 进行STREAM基准测试的时候,Xen的内存开销要明显大于LXC(接近30%),而后者能提供接近原生的性能表现。
- 进行IOzone基准测试时,LXC的读,重复读,写,重写操作的性能接近于本机的性能,而Xen会产生明显的开销。
- 使用LXC进行NETPIPE基准测试的网络带宽性能接近本机性能,而Xen的开销几乎增加了40%。
- 由于使用了客户机操作系统,在Isolation Benchmark Suite (IBS)测试中,LXC的隔离性与Xen相比要较差。一个称为fork炸弹(fork bomb)的特殊测试(它会不断地重复创建子进程)表明,LXC无法限制当前创建的子进程数。
容错性
Mesos为主节点提供容错的方式是使用zookeeper(Hunt 等2010)的热备用配置来运行多个主节点,一旦主节点崩溃的话,就会选举出新的主节点。主节点的状态由三部分组成——它们分别是,活动从节点,活动框架,以及运行任务列表。新的主节点可以从从节点和框架调度器的信息中重构自身的状态。Mesos还会将框架执行器及任务报告给对应的框架,框架可以根据自身的策略来独立地处理失败。Mesos还允许框架注册多个调度器,一旦主调度器失败了,可以去连接从调度器。然而,框架得确保不同调度器的状态是同步的。
[1] 熟悉UNIX操作系统的读者会记得,chroot是一个改变当前工作进程树根目录的命令,它会创建一个叫”chroot监狱”的环境来提供文件级别的隔离。
