随着对spark的业务更深入,对spark的了解也越多,然而目前还处于知道的越多,不知道的更多阶段,当然这也是成长最快的阶段。这篇文章用作总结最近收集及理解的spark相关概念及其关系。
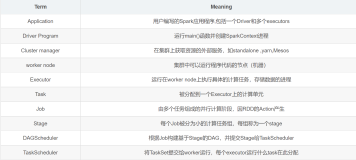
名词
driver
driver物理层面是指输入提交spark命令的启动程序,逻辑层面是负责调度spark运行流程包括向master申请资源,拆解任务,代码层面就是sparkcontext。
worker
worker指可以运行的物理节点。
executor
executor指执行spark任务的处理程序,对java而言就是拥有一个jvm的进程。一个worker节点可以运行多个executor,只要有足够的资源。
job
job是指一次action,rdd(rdd在这里就不解释了)操作分成两大类型,一类是transform,一类是action,当涉及到action的时候,spark就会把上次action之后到本次action的所有rdd操作用一个job完成。
stage
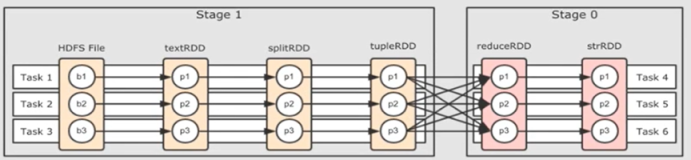
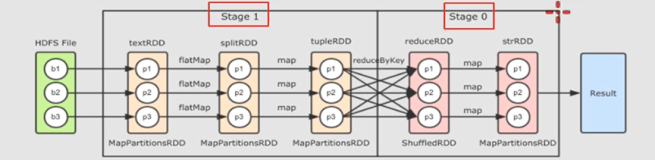
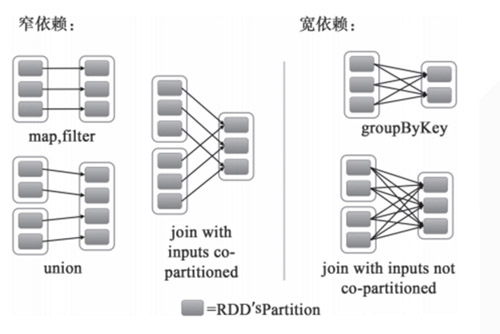
stage是指一次shuffle,rdd在操作的时候分为宽依赖(shuffle dependency)和窄依赖(narraw dependency),如下图所示。而宽依赖就是指shuffle。
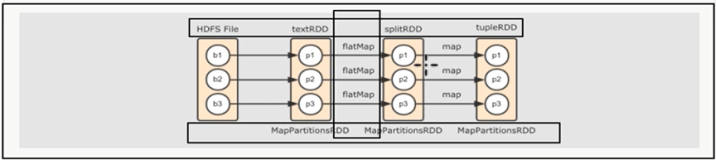
应某人要求再解释一下什么是窄依赖,就是父rdd的每个分区都只作用在一个子rdd的分区中,原话是这么说的 each partition of the parent RDD is used by at most one partition of the child RDD。
task
task是spark的最小执行单位,一般而言执行一个partition的操作就是一个task,关于partition的概念,这里稍微解释一下。
spark的默认分区数是2,并且最小分区也是2,改变分区数的方式有很多,大概有三个阶段
1.启动阶段,通过 spark.default.parallelism 来初始化默认分区数
2.生成rdd阶段,可通过参数配置
3.rdd操作阶段,默认继承父rdd的partition数,最终结果受shuffle操作和非shuffle操作的影响,不同操作的结果partition数不同
名词关系
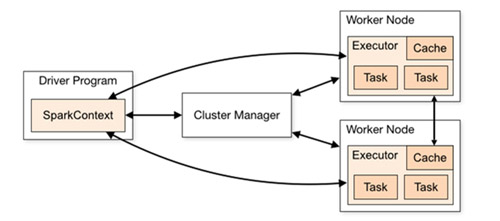
物理关系
官网给出的spark运行架构图
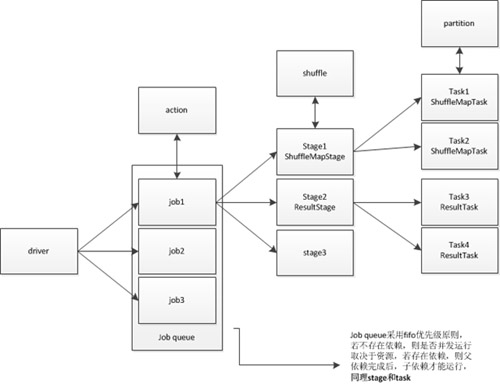
逻辑关系
下图是总结的逻辑关系图,如果有不对之处,还望提醒。
本文作者:小数点
来源:51CTO