有些事,只靠人力就是没法做到。
由此,MSKCC (凯特琳癌症中心)跟 IBM 合作,利用超级计算机IBM Watson 吸收知识的能力,扩展人类的极限:IBM Watson 每秒能够扫描上万亿字节的医疗数据,而且“过目不忘”,再结合强大的机器学习算法,从大量结构化和非结构化数据中得出洞察,进而助力医生做出更加个性化的的治疗方案。
在福布斯的报道中,与IBM Watson 合作的医疗机构Wellpoint的医生表示,试验中IBM Watson 对肺癌诊断正确的几率为 90%,而人类医生只有 50%。使用IBM Watson 参与临床教学的医院 Cleveland Clinic 的医生都经常为IBM Watson 给出的建议治疗方案感到惊叹:“为什么我(们)当初就没有想到那一点?!”
虽然“科学和技术飞速发展”已成了老生常谈,而癌症诊疗还是一个充满迷思的领域。目前,人们经常提及并感到恐惧的癌症包含:“肺癌”“乳腺癌”等。
借助基因检测等生物信息技术,我们知道,所谓的“肺癌”“肾癌”“乳腺癌”,实际上是对成千上万种不同的细胞突变模式或错误排列的总称。根据 2015 年一篇研究肾癌的论文,正如世界上没有两片一模一样的树叶,地球上也没有两个一模一样的肿瘤;还有研究发现,就连同一个人的同一个肿瘤里面,也没有两个细胞在遗传基因上是一样的。
了解这一点,对癌症诊疗十分关键。目前,癌症诊断几乎全都是靠“看”:人类医生在显微镜下观看细胞或组织样本,有时候对细胞DNA、RNA 或者蛋白质的一些测试结果可以帮助医生做出判断——但归根结底,还是靠“看”。据媒体报道,2014 年,美国肺癌、乳腺癌和皮肤癌的死亡率将近 40%,所以对于癌症而言,早发现早治疗非常关键。
靶向药物及疗法的出现,使癌症医疗情形大为改观。所谓“靶向治疗”,就是针对含有某种癌症有关的基因突变的细胞,开发“靶向药物”,要么杀死这些细胞,要么使其不能复制。然而,据统计,目前癌症药物治疗有效——即肿瘤体积显著缩小——比例只有 22%。也就是说,再怎么“靶向”,当靶子的数量太多时,治疗也鞭长莫及。
如何从大量杂乱无章的信息中发现模式并找出规律?
很容易想到的方法是,借助机器的计算力分析并预测医疗数据。1991年,用于医学诊断的简单贝叶斯方法 QMR 模型被提出。1994 年,《美国医学信息学会》(JAMIA)发表了题为《医疗诊断决策支持系统:过去、现在和未来》的调查文章。2005 年,《英国医学杂志》(BMJ)发表了题为《用临床决策支持系统提高临床实践》的论文。
近年来,随着计算能力的提升和相关医疗大数据的发展,越来越多的医生开始使用机器学习帮助癌症诊断。机器学习算法使用各种统计、概率和优化方法让计算机从输入中“学习”,从海量非结构化的数据中识别出人类难以识别的模式。除了癌症诊断,机器学习也可以用于癌症预后及复发的判断。
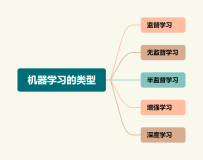
在癌症诊断中使用的机器学习算法主要有三种:监督学习、无监督学习和强化学习。在监督学习的情况下,癌症诊断可以简化为“分类”:模型根据训练结果,将输入的数据分为几类。假设采集了与乳腺癌有关的数据,根据肿瘤的大小判断该肿瘤是良性还是恶性,那么机器学习模型要问答的问题,就成了估计这个肿瘤是良性(或恶性)的概率,如下图。
还一种广泛使用的机器学习方法是半监督学习,也就是监督学习和无监督学习的结合。采用半监督学习时,输入的数据有的打了标签,有的则没有标签,通常没有标签的数据会更多。完善标签的质量后,机器学习算法相比一般的预测模型,正确率会有大幅提升。
| 机器学习算法 |
优势 |
局限 |
| 决策树 |
简单好用、可以通过pruning处理过度拟合问题 |
各项必须互斥、最终决策树取决于选项输入的顺序,训练集错误会影响整个决策树 |
| Naïve Bayes |
广泛适用、效率高,输入不分前后 |
假设各项独立,假定各属性正态分布,选项和分类频率影响精度 |
| k临近分类 |
分类快、非线性问题,可接受非结构化输入 |
假设各项同样重要,输入项增加计算量剧增 |
| 神经网络 |
可用于分类和回归,可接受非结构化输入及无标签输入 |
算法黑箱,难以评估 |
| SVM |
非线性问题,复杂度可控 |
训练数据不是线性可分时很难确定最佳参数,比贝叶斯和决策树的训练速度慢 |
| 遗传算法 |
可用于特征归类和特征选择,主要用于优化,能得出一个“好”的答案,但并不一定是“最优解” |
最优方法不一定全局性,输入/输出复杂性与选项表征有关 |
2016 年1月,罗氏制药收购了名不见经传的Foundation Medicine,获得了 3.5 万份癌症基因测序及其推荐治疗方案。2016 年 4 月,由原华大基因CEO王俊创办的碳云智能对外公布 A 轮接受融资,估值 10 亿美元,要构建健康大数据平台,整合遗传、医疗、营养乃至美容健身等各类健康数据资源。像这样的例子还有很多很多,奥巴马政府去年初提出的“精准医疗计划”、“Cancer Moonshot”,也都是想利用大数据和人工智能帮助人类医生,提升癌症的治愈率。
目前,对于某些疾病,算法的准确度已经足够高,远远超过人类医生。越来越多的人类医生开始意识到,借助机器学习,他们能够快速精准地获得临床有用的医疗信息。
医药步入“智能化”
目前,每年花费在抗癌药物研发的大量资源中,有很多都浪费在了所谓的“试错”上面。近年来计算机科学的发展,让很多医疗机构都将认知计算和大数据用于癌症诊疗,IBM 算是较早就开始尝试这一点;截止 2015 年底,IBM Watson 阅读了 1967 年到 2000 年的 470 万份专利和 1100 万份医药期刊,并从中生成了 250 多万种新的化合物,构建了一个强大的数据库(Strategic IP Insight Platform)——就像计算材料科学家使用机器学习算法加速新材料的发现,此举也将有望大举加速抗癌新药的研发。
不仅如此,机器算法还能提升现有癌症药物的使用率。UCSF 研究人员开发了一种能够系统性筛选现有癌症药物的程序,并检测了 90 种现有抗癌药各自针对 51 种基因突变的治疗效果。根据去年在 Cancer Discovery 发表的论文,该团队已经发现了超过 10 种有望进入临床试验的药物,其中包括一些此前根本没人想到的方案,比如原本为了 AA 基因突变研发的 aa 药,实际上对 BB 基因突的治疗结果更好,乃至可以进入临床试验。
不单药物研发理论,人工智能在实际药物生产过程中也起到了很大的加速作用。前不久,MIT的 3 名教授在 Science 发表论文,宣布团队成功将制药工厂装进了“电冰箱”。研究人员在论文中描述了一款电冰箱大小的一体化制药机原型。
据介绍,这台制药机一天之内可以生产 1000 剂量的药片,将制药速度提升了 10 倍,目前已经可以生产Benadryl、lidocaine、Valium和Prozac 这 4 种常用药。这款制药机独特的地方在于,它将传统制药过程中的电路、加热器、混合器、反应器等设备,集成为一个电冰箱大小的封闭工作站。一般而言,合成药物所需要的温度、压强等参数都可以事先设置好,只有个别步骤需要技术人员控制或者加入原料。这台机器可以根据药物的特点,调整参数和配件,以往需要多个工厂联合生产的药物,只用这一台机器就能够完成。
最后,从药物研发出来到经过批准上市,一般也需要长达几年甚至几十年的时间,这对癌症患者而言,恐怕比金钱更加难以承受。新智元智库专家王飞跃教授在《虚拟现实:平行也可以相交》一文中指出:“现在制定和实施一项社会政策,往往需要多年才能检验到实际效果。如果有虚拟现实构造的人工社会模型,政策制定后,拿虚拟人做试验品,在‘计算’试验中发现政策中的可能漏洞,推理中的可能局限甚至偏见,再通过虚拟现实把逻辑上的错误和个人的私利尽可能剔除出来加以修正。通过智能系统选择最优化的方案,而不是拿实际的人力、资源、财政来试错。
此外,还可以在虚拟和物理社会中同时实施政策,比较两者的结果,如果两者不一样,之间的差别就变成了修正政策的反馈信号。是不是当时的假设错了?如果假设没错是不是现实社会中有人搞了鬼?通过虚拟现实,形成闭环的、有反馈的虚实互动,最后走向虚实一体、知行合一。不单是社会政策,未来甚至每个人每做一件事之前都应该先虚拟化,模拟每一步有什么目标,怎样实现,这就是知识自动化的第一步,由于效率提高节省出来的时间将被用到事前虚拟中去,不难设想,事前虚拟将减少许多社会矛盾和资源浪费。”同样,我们也能畅想,未来将虚拟现实应用于药物临床试验,必将极大缩短药物从研发到上市的时间,此外还能解决样本少、减轻临床试验者痛苦等其他问题。
目前,有几百个基因疗法正在研发之中,对于大约5000种由单一基因错误导致的罕见疾病来说,很多疗法都将是百分百治愈的。
没有理由不充满信心——AI将真正成为医护人员助手
或许上面说的这些看起来都很遥远,实际上机器学习已经投入实用,在美国有很多医生和护士都会利用机器进行决策。
医疗公司辉瑞和IBM合作,利用认知计算解析复杂数据的能力,整合可扩展的测量和分析系统,预计推行 24 小时全天候的病患监测,为患者提供更好的治疗。
在中国,以房颤病人需接受干预为例,借助IBM认知医疗数据模型的确认和精准化分析,某些城市的医院已经实现了卒中(中风)风险预测精度提高,在高风险病人中精确地找到真正需要干预的病人,极大降低病人不必要的医疗花费。
就在常用的社交网络中,也埋藏着大量有助于癌症诊疗及预防的信息。由于患者经常使用社交网络分享就医经验和治疗感想,因此,收集并分析社交网络上的有关信息,有望提供能用于癌症预防和治疗以及完善医医疗体系和政策的辅助信息。
而确实也有研究人员使用机器学习算法和自然语言处理,分析 Twitter 中什么样的关键词会触发关注,哪些医疗信息更容易得到传播,这些信息都有助于健康政策以及疾病预防。不仅如此,去年 BMJ 一篇论文描述了一个由美英科学家组成的团队,搜集人们在 Twitter 上发送的消息,评估患者就医体验,对于改善医疗体系也有帮助。
人工智能能够改善就医体验,提高癌症诊断正确率,加速新药研发。随着时间推移,越来越多的医药研究者与计算机科学家合作,共同完善机器学习等人工智能在医药领域中的应用。不仅如此,还可以看到一大批综合性人才的崛起。既拥有医药学知识,又具备人工智能洞见的研究者,将是未来医药界的发展基础。
而且,我们没有理由不充满信心——当奥巴马提出精准医疗计划,宣称要“治愈”癌症时,很多美国医药界人士的反应都比较积极,没有人会天真地以为癌症能被简单“治愈”,但他们很高兴奥巴马用了“治愈”这个词,这是人类一直努力的目标,有了人工智能,只会让我们更快达到那里。
文章转自新智元公众号,原文链接