0、导读
饱受诟病的InnoDB表COUNT(*)性能问题在5.7下做了优化,果真如此吗?
1、经典需求:InnoDB表COUNT(*)
InnoDB引擎表经常被抱怨执行COUNT(*)的效率太差,因此此类需求通常会被建议用其他方法来满足,比如另外加一个计数器表,或者用SHOW TABLE STATUS查看大概数量。
不过,从MySQL 5.7.2起,这个问题得到了解决,我们来看看。
2、MySQL 5.7版本InnoDB对COUNT(*)的优化
MySQL每发布一个新版本,都会放出相应的Release Notes,我们注意到5.7.2版本的发布说明中提到:
InnoDB:
SELECT COUNT(*) FROM tstatements now invoke a single handler call to the storage engine to scan the clustered index and return the row count to the Optimizer. Previously, a row count was typically performed by traversing a smaller secondary index and invoking a handler call for each record. A single handler call to the storage engine to count rows in the clustered index generally improvesSELECT COUNT(*) FROM tperformance. However, in the case of a large clustered index and a significantly smaller secondary index, performance degradation is possible compared to performance using the previous, non-optimized implementation. For more information, see Limits on InnoDB Tables.
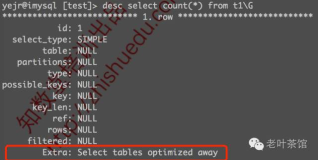
简单地说就是:COUNT(*)会选择聚集索引,进行一次内部handler函数调用,即可快速获得该表总数。我们可以通过执行计划看到这个变化,例如:
很明显,在查询优化器阶段就已经得到优化了,相比效率应该杠杠的吧,我们稍后再来对比看看。
补充说下,5.7以前的版本中,COUNT(*)请求通常是:扫描普通索引来获得这个总数。也来看看5.6下的执行计划是怎样的:
可以看到,可以利用覆盖索引来完成COUNT(*)请求。
3、对比测试
先看一组测试数据:
| count(*)对比测试 |
MySQL 5.6.33 |
MySQL 5.7.15 |
相差 |
| 表数据量 |
8976914 |
9000270 |
100.26% |
| 耗时(秒) |
5.459952 |
1.142340 |
20.92% |
可以看到,两次数据量相当,但SQL耗时5.7约只有5.6的1/5,这个效率还是不错的吧。
我们来看看5.6和5.7版本下的status和profiling对比情况:
4、别高兴得太早
看完上面的对比测试,相信您已经心动了吧,但还别高兴得太早哦,官方文档里其实埋了一个伏笔:
InnoDB:
SELECT COUNT(*) FROM tstatements now invoke a single handler call to the storage engine to scan the clustered index and return the row count to the Optimizer. Previously, a row count was typically performed by traversing a smaller secondary index and invoking a handler call for each record. A single handler call to the storage engine to count rows in the clustered index generally improvesSELECT COUNT(*) FROM tperformance. However, in the case of a large clustered index and a significantly smaller secondary index, performance degradation is possible compared to performance using the previous, non-optimized implementation. For more information, see Limits on InnoDB Tables.
简言之,就是说如果聚集索引较大(或者说表数据量较大),没有完全加载到buffer pool中的话,有可能反而会更慢,还不如用原先的方式。
下面我们来测试下,读取tpcc测试表stock,该表有1亿行记录,表空间文件约65GB,而innodb buffer pool只分配了12G,这时候再看下对比数据:
| count(*)对比测试 |
MySQL 5.6.33 |
MySQL 5.7.15 |
相差 |
| 表数据量 |
1亿 |
1亿 |
0.00% |
| 耗时(秒) |
693.66 |
5331.69 |
768.63% |
在这种情况下,5.7版本反而慢的夸张,悲剧啊~
那么在5.7下的大表,有没有办法仍旧采用以前的方法来做COUNT(*)统计呢。当然可以了,我们可以强制指定普通索引,不过还需要加上WHERE条件,否则还是不行。后来搜了下,发现这是个bug,印风(zhaiwx)已经报告给官方了,bug id:81854。
这次的SQL执行耗时和在5.6下的就基本一样了。
4、后记
5.7版本整体挺赞的,不过还是有不少地方需要完善,期待能更成熟起来。
参考
1. MySQL 5.7.2 Release Notes:http://dev.mysql.com/doc/relnotes/mysql/5.7/en/news-5-7-2.html
2. Limits on InnoDB Tables:http://dev.mysql.com/doc/refman/5.7/en/innodb-restrictions.html
文章转自老叶茶馆公众号,原文链接: https://mp.weixin.qq.com/s/x74ix7k6eT583pR6iGyO6Q