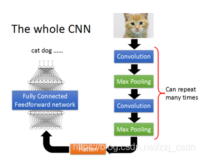
最近基于深度学习的图像分割技术一般依赖于卷积神经网络 CNN 的训练,训练过程中需要非常大量的标记图像,即一般要求训练图像中都要有精确的分割结果。
对于图像分割而言,要得到大量的完整标记过的图像非常困难,比如在 ImageNet 数据集上,有 1400 万张图有类别标记,有 50 万张图给出了 bounding box, 但是只有 4460 张图像有像素级别的分割结果。对训练图像中的每个像素做标记非常耗时,特别是对医学图像而言,完成对一个三维的 CT 或者 MRI 图像中各组织的标记过程需要数小时。
如果学习算法能通过对一些初略标记过的数据集的学习就能完成好的分割结果,那么对训练数据的标记过程就很简单,这可以大大降低花在训练数据标记上的时间。这些初略标记可以是:
1. 只给出一张图像里面包含哪些物体;
2. 给出某个物体的边界框;
3. 对图像中的物体区域做部分像素的标记,例如画一些线条、涂鸦等(scribbles)。
1. ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation (CVPR 2016)

香港中文大学的 Di Lin 提出了一个基于 Scribble 标记的弱监督学习方法。 Scribble 是一个很方便使用的标记方法,因此被用得比较广泛。如下图,只需要画五条线就能完成对一副图像的标记工作。
ScribbleSup 分为两步,第一步将像素的类别信息从 scribbles 传播到其他未标记的像素,自动完成所有的训练图像的标记工作; 第二步使用这些标记图像训练 CNN。在第一步中,该方法先生成 super-pxels, 然后基于 graph cut 的方法对所有的 super-pixel 进行标记。

Graph cut 的能量函数为:

在这个 graph 中,每个 super-pixel 是 graph 中的一个节点,相接壤的 super-pixel 之间有一条连接的边。这个能量函数中的一元项包括两种情况,一个是来自于 scribble 的,一个是来自 CNN 对该 super-pixel 预测的概率。整个最优化过程实际上是求 graph cut 能量函数和 CNN 参数联合最优值的过程:

上式的最优化是通过交替求和的最优值来实现的。文章中发现通过三次迭代就能得到比较好的结果。

2. Constrained Convolutional Neural Networks for Weakly Supervised Segmentation (ICCV 2015)
UC Berkeley 的 Deepak Pathak 使用了一个具有图像级别标记的训练数据来做弱监督学习。训练数据中只给出图像中包含某种物体,但是没有其位置信息和所包含的像素信息。该文章的方法将 image tags 转化为对 CNN 输出的 label 分布的限制条件,因此称为 Constrained convolutional neural network (CCNN).

该方法把训练过程看作是有线性限制条件的最优化过程:

其中是一个隐含的类别分布,是 CNN 预测的类别分布。目标函数是 KL-divergence 最小化。其中的线性限制条件来自于训练数据上的标记,例如一幅图像中前景类别像素个数期望值的上界或者下界(物体大小)、某个类别的像素个数在某图像中为 0,或者至少为 1 等。该目标函数可以转化为为一个 loss function,然后通过 SGD 进行训练。

实验中发现单纯使用 Image tags 作为限制条件得到的分割结果还比较差,在 PASCAL VOC 2012 test 数据集上得到的 mIoU 为 35.6%,加上物体大小的限制条件后能达到 45.1%, 如果再使用 bounding box 做限制,可以达到 54%。FCN-8s 可以达到 62.2%,可见弱监督学习要取得好的结果还是比较难。
3. Weakly- and Semi-Supervised Learning of a DCNN for Semantic Image Segmentation
Google 的 George Papandreou 和 UCLA 的 Liang-Chieh Chen 等在 DeepLab 的基础上进一步研究了使用 bounding box 和 image-level labels 作为标记的训练数据。使用了期望值最大化算法(EM)来估计未标记的像素的类别和 CNN 的参数。

对于 image-level 标记的数据,我们可以观测到图像的像素值和图像级别的标记, 但是不知道每个像素的标号, 因此把 当做隐变量。使用如下的概率图模式:

使用 EM 算法估计和。E 步骤是固定求的期望值,M 步骤是固定使用 SGD 计算θ。

对于给出 bounding box 标记的训练图像,该方法先使用 CRF 对该训练图像做自动分割,然后在分割的基础上做全监督学习。通过实验发现,单纯使用图像级别的标记得到的分割效果较差,但是使用 bounding box 的训练数据可以得到较好的结果,在 VOC2012 test 数据集上得到 mIoU 62.2%。另外如果使用少量的全标记图像和大量的弱标记图像进行结合,可以得到与全监督学习 (70.3%) 接近的分割结果 (69.0%)。
4. Learning to Segment Under Various Forms of Weak Supervision (CVPR 2015)
Wisconsin-Madison 大学的 Jia Xu 提出了一个统一的框架来处理各种不同类型的弱标记:图像级别的标记、bounding box 和部分像素标记如 scribbles。该方法把所有的训练图像分成共计个 super-pixel,对每个 super-pixel 提取一个维特征向量。因为不知道每个 super-pixel 所属的类别,相当于无监督学习,因此该方法对所有的 super-pixel 做聚类,使用的是最大间隔聚类方法 (max-margin clustering, MMC), 该过程的最优化目标函数是:

其中是一个特征矩阵,每列代表了对于的类别的聚类特征。是将第个 super-pixel 划分到第类的代价。在这个目标函数的基础上,根据不同的弱标记方式,可以给出不同的限制条件,因此该方法就是在相应的限制条件下求最大间隔聚类。

该方法在 Siftflow 数据集上得到了比较好的结果,比 state-of-the-art 的结果提高了 10% 以上。
小结:在弱标记的数据集上训练图像分割算法可以减少对大量全标记数据的依赖,在大多数应用中会更加贴合实际情况。弱标记可以是图像级别的标记、边框和部分像素的标记等。训练的方法一般看做是限制条件下的最优化方法。另外 EM 算法可以用于 CNN 参数和像素类别的联合求优。
参考文献
1. Di Lin, Jifeng Dai, Jiaya Jia, Kaiming He, and Jian Sun."ScribbleSup: Scribble-Supervised Convolutional Networks for Semantic Segmentation". IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2. Pathak, Deepak, Philipp Krahenbuhl, and Trevor Darrell. "Constrained convolutional neural networks for weakly supervised segmentation." Proceedings of the IEEE International Conference on Computer Vision. 2015.
3. Papandreou, George, et al. "Weakly-and semi-supervised learning of a DCNN for semantic image segmentation." arXiv preprint arXiv:1502.02734 (2015).
4. Xu, Jia, Alexander G. Schwing, and Raquel Urtasun. "Learning to segment under various forms of weak supervision." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015.