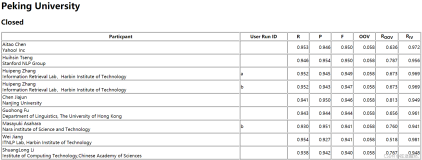
中文分词是中文自然语言处理的一个非常重要的组成部分,在学界和工业界都有比较长时间的研究历史,也有一些比较成熟的解决方案。今天我们邀请了出门问问的两位重磅嘉宾徐博士和Jason,和大家一起来回顾一下中文分词的发展,着重谈一谈现在比较流行的一些基于机器学习的分词方法。
嘉宾简介
徐博士,约翰霍普金斯大学语言和语音实验室博士。2012年毕业后加入微软总部,先后在Bing和微软研究院从事自然语言处理和机器学习相关的研究和产品开发,是cortana语义理解和对话系统团队以及wordflow输入法团队的主要成员。雷锋网雷锋网雷锋网(公众号:雷锋网)
Jason,剑桥大学自然语言处理组毕业。一直从事自然语言处理方面的研究与开发工作。加入出门问问3年多,负责开发出门问问的语义分析系统、对话系统,参与的产品包括出门问问手机版、Ticwear智能语音手表交互系统、魔法小问智能客服对话系统。
Part 1
▎什么是分词,为什么要做分词?
首先我来说说什么是词。“词是最小的能够独立运用的语言单位”,那么什么是独立运用呢?它可以解释为“单独做句法成分或单独起语法作用”。在语言学语义学的角度有很多相关的研究都对词给出了一些定义和判定标注。然很多中文词仅由单个汉字组成,但是更多的单个汉字是无法“单独做句法成分或单独起语法作用”。由于国际上常用的NLP算法,深层次的语法语义分析通常都是以词作为基本单位,很多中文的自然语言处理的任务,也就多了一个预处理的过程来把连续的汉字分隔成更具有语言语义学上意义的词。这个过程就叫做分词。
这里有一个从(Xue 2003) 中拿来的例子:
日文章鱼怎么说 =》 日文 章鱼 怎么 说 ? 日 文章 鱼 怎么 说?
我想强调的一点是,尽管在语言学语义学上,词有着相对清晰的定义,对于计算机处理自然语言来说,分词很多时候没有放之四海皆准的共同标准。由于分词本身更多的时候是作为一个预处理的过程,判断其质量的好坏更多的时候需要结合下游的应用来进行。
比如在语音识别中,语言模型的创建通常需要经过分词,从识别效果来看,越长的词往往准确率越高(声学模型区分度更高)。但是在文本挖掘中,很多时候短词的效果会更好,特别是从召回率的角度来看(Peng et al. 2002, Gao et al. 2005)。在基于phrase的机器翻译中,也有研究发现短词(比中文treebank的标准短)会带来更好的翻译效果(Chang et al. 2008)。所以,如何衡量分词的好坏,如何选择分词的方法,还是要结合自身的应用来进行。
▎分词有哪些常见的传统方法?
词典匹配是分词最传统最常见的一种办法。即便在后面要提到的基于统计学习的方法中,词表匹配也通常是非常重要的信息来源(以特征函数的形式)。匹配方式可以有正向(从左到右),逆向(从右到左)。对于匹配中遇到的多种分段可能性(segmentation ambiguity),通常会选取分隔出来词的数目最小的。
很明显,这种方式对词表的依赖很大,一旦出现词表中不存在的新词,算法是无法做到正确的切分的。但是词表匹配也有它的优势,比如简单易懂,不依赖训练数据,可以做到和下游的应用紧密结合 (机器翻译中的phrase table,TTS中的词典等等),易于纠错等等。
还有一类方法通过语料数据中的一些统计特征(如互信息量)去估计相邻汉字之间的关联性,进而实现词的切分。这类方法不依赖词表,具有很强的灵活性,特别是在对生词的发掘方面,但是也经常会有精度方面的问题。
所以很多系统会结合基于词表的方法和无词表方法,发挥词表方法的准确性以及在与后段应用结合上的优势,同时利用无词表方法在召回方面的能力。
▎机器学习在分词领域有哪些应用?
确实,最近十多年,机器学习的发展非常迅速,新的模型,新的算法层出不穷。中文分词由于其重要性,以及问题的清晰性,成为很多新研究的试验场。因为这方面的内容很多,所以我想尽可能的把主要的模型和方法分为两大类:
一类是基于character tagging的,也就是对每一个字单独进行分段信息的标注;
还有一类就是基于词的,也就是对词进行整体的标注和建模。
基于单个字方法的核心就是对每一个字在其所属词中的位置进行一个标注。对于任何一个字来说,它可以是一个词的开始(Beginning), 一个词的中间(Inside), 一个词的结尾(End),或者本身就是一个单字的词(Singleton),这也就是在序列标注中常用的BIES的分类。这种标注空间(模型状态空间)的划分在其他任务上(如NER)也很常用,也会有一些类似的变种,比如NER中常用的BIO。
说到这类方法,就要说到MEMM (Maximum Entropy Markov Model) 和CRF (Conditional Random Field) 。这两个都是discriminative的模型,和generative的模型(比如naive bayes, HMM)相比,在特征函数的定义方面有很大的灵活性。

(第二个是MEMM,第三个是CRF,X是句子,Y是位置的标注。)
MEMM是一个locally normalized的模型。也就是说在每一个字的位置,其对应的概率分布需要进行归一化,这个模型有一个很有名的label bias的问题,也就是当前的tag完全由前一个tag决定,而完全忽略当前的字本身。
CRF则通过全局归一化(global normalization)的方式很好的解决了这个问题。这两个模型都被拿来在分词上试验过(Xue et al. 2003, Peng et al. 2004, Tseng et al. 2005, etc), 取得了不错的效果。

这类基于单个字的模型,正如它的名字所暗示,无法直接的去model相邻词之间的相关性,也无法直接看到当前整个词所对应的字符串。具体到MEMM和CRF中特征函数的定义,在当前位置,模型无法抓去到“当前的词”,“两边的词”这样重要的特征,而只能通过基于字的特征去代替。这个往往会造成建模效果与效率的损失。
基于词的模型就很好的解决了这个问题。
这一块的很多工作会去用类似transition based parsing的办法去解决分词的问题。Transition based parsing是一种渐进式的(incremental),自下而上(bottom-up)的语法分析办法。它一般以从左向右的方式处理逐字处理文本的输入,并在运行过程中通过一个堆栈去保存到当前为止得到的不完整的分词结果,并且通过机器学习的方法去决定如何整合当前的分析结果,或是接收下一个输入去拓展当前的分析结果。
具体到分词这个任务上,每一个字输入进来,算法会去决定这个字是去拓展堆栈上已经保存的词,还是开始一个新词。这个算法的一个问题就是堆栈上的保存的到当前位置的分析结果的数量会非常大(到当前为止所有可能的分词结果),所以必须要做pruning保证搜索空间在可控范围内。

基于词的模型还有一个方法这里简单提一下(Andrew, 2006),它和刚才说的transition parsing的方法还是很类似的,这个模型就是Semi CRF (Sarawagi & Cohen 2004)。这个模型运用也很多,微软内部很多NER就是用这个模型。它在本质上是一个高阶的CRF,通过扩展state space的方法去模拟segment level的关联性,用到分词上也就是相邻词之间的关联性。和之前的方法要做pruning一样,Semi-CRF在实际应用中也需要限制segment的长度,以控制搜寻最优解的复杂度。
▎深度学习在分词中的应用?
当然。最近几年深度学习发展非常快,影响力很大,所以这一块要专门拿出来说一说。
和大多数自然语言处理中的任务一样,深度学习也不出意外地被用在了分词上,最近几年也有非常多的相关的论文。和之前说过方法相比,深度学习带来的变化主要是特征的定义与抽取。无论是基于单字的,还是基于词的,最近几年都有这方面的工作。
基于单字的,运用deep learning的方法进行NLP领域的序列的标注,其实早在2008年就有人做过(Collobert & Weston 2008)主要的方法是通过神经网络在每一个位置去自动提取特征,并且预测当前位置的标注,最后也可以加一个tag transition模型与神经网络输出的emission模型合并,通过viterbi抽取最佳标注序列。最近几年的进展主要是通过更强大的神经网络去提取更有效的信息,从而实现分词准确率的提高 (Zheng et al. 2013, Pei et al. 2014, Chen et al. 2015, Yao et al.2016, etc)。

这个是collobert 2008年的基本版本,最近的工作结构上没有太大偏差。全局归一化的CRF模型也可以通过神经网络去自动提取特征(DNN,CNN,RNN,LSTM,etc),这个在NER上已经有了广泛的应用,也完全可以用在分词这个任务上,这里就不赘述了。
之前提到的基于词的transition based的分词最近也有了deep learning领域的拓展,原有的基于线性模型的action模型(延续当前词还是开始新词)也可以通过神经网络去实现,简化了特征的定义,提高了准确率。
▎除了深度学习之外,分词领域还有那些新的发展方向?
Deep learning当然是最近几年最新的,非常重要的发展方向。除此之外,Joint modeling(联合建模)的方法也值得一提。
传统的中文自然语言处理通常会把分词作为一个预处理的过程,所以系统是pipeline形式的,这样带来的一个问题就是error propagation。也就是分词的错误会影响到后面更深层次的语言语义分析,比如POS tagging, chunking, parsing等等。所以在学术界也有很多joint modeling(联合建模)方面的工作,主要目的就是把分词和其他更复杂的分析任务一起进行(Zhang & Clark 2010, Hatori et al. 2012, Qian & Liu 2012, Zhang et al. 2014, Lyu et al. 2016, etc)。
最近几年由于神经网络的迅速发展,其强大的特征学习能力也大大简化了对多个任务进行联合建模时在特征选取方面所要做的工作。联合建模的一大好处是分词与其他任务可以共享有用的信息,分词的时候也会考虑到其他任务的要求,其他任务也会考虑各种分词的可能性,全局上可以取得最优解。
但是随之而来问题是搜索的复杂度往往会显著提高:需要更有效的pruning机制在控制复杂度的同时,不对搜索的结果产生显著影响。
Part 2
▎中文分词在语义分析中的应用?
好的!谢谢徐博士这么详尽的介绍了中文分词的各种算法。因为,就像徐博士说了,中文分词是大部分下游应用的基础,这些下游应用小到POS词性标注、NER命名实体识别,大到文本分类、语言模型、机器翻译。所以我举几个基本的例子来回答在中文分词的基础上,怎么进行之后的语义分析应用。当然,需要事先强调的一点是,这里谈的一些算法(包括学术界很多主流的算法)都是语言无关的,并且都是以词作为最小单位的。
那么对于中文来说,只要做好分词(并且现在的分词准确率还相当不错,能达到96%左右的F-score Zhang et.al 2016),就可以跟对接现在比较主流的英文NLP算法。
先来谈谈词性标注。

所谓词性标注,简单来说,就是在分词的结果上,判断某个词是名词、动词、形容词等等。这一般是被当做一个序列标注问题来做,因为 : 判断的依据可以是词本身给出(比如“打开”这个词大部分情况不用看上下文都可以猜测是一个动词)也可以由上一个词的词性来给出(比如“打开 XX”,虽然不知道XX是什么词,但是跟在动词“打开”后面,很可能是名词)。
又比如,命名实体识别。

在得到分词结果,并且知道了每个词的词性之后,我们可以在此基础上做命名实体识别(Named Entity Recoginition)。学术上,所谓的命名实体一般指的是人名(PERSON)、地名(LOCATION)、机构名(ORGANIZATION) 等等。当然,在实际商业产品中,根据不同的业务场景需求,命名实体的类别会更加细分得多。比如地名可能会区分省、市、县,或者餐馆、酒店、电影院等等。
在得到分词结果和词性之后,我们还可以建立一棵语法树。

输出的结果,包含了整句句子的语法结构信息,比如名词短语、介词结构等等。如上图所示。最后,推荐大家可以去Stanford NLP网站亲自试试:http://nlp.stanford.edu:8080/parser/index.jsp 里面。

这个Demo,演示了从一句句子开始,如何做分词、POS tagging、Syntactic Parsing,以及依存分析、指代消解等等各种基本NLP应用。自己亲手试试可以对分词等一系列基础NLP方法有比较直观的了解哦。
▎在实际的应用中遇的一些困难?
很多学术界的NLP算法,放到真实应用场景里面来,面对千变万化的人类自然语言,都会遇到各种各样的困难。我就分享一下我们出门问问这几年来做中文分词的一些经验和遇到的困难吧。先做个小广告,群内可能有朋友不是很熟悉我们出门问问。出门问问成立于2012年,是一家以语音搜索为核心的人工智能创业公司。我们做了4年语音搜索,从手机版App、做到手表、车载,载体可能不同,但是核心都是我们的语音+语义的这一套语音搜索系统。

比如上图中所示,用户通过语音输入一句语音:“交大附近的南京大排档”。这段语音经过语音识别转换成一句自然语言文本,然后交由我们的语义分析系统进行处理。我们的语义分析系统会经过一系列的分词、词性标注、命名实体识别,然后能够判断出来这句query的询问主题是什么(订餐厅、导航、天气 etc.),并把相应关键字提取出来,交给后面的搜索团队进行结果搜索和展示。
因为出门问问是专注于生活信息类查询,因此正确识别出query中的实体名(POI、电影名、人名、音乐名 etc.)非常重要。出门问问的NLP系统也是以分词作为整个NLP系统的基础的:正确识别实体名的前提是整个实体名称正确并且完整地被分词开来。
因此,我们的分词是需要偏向于实体名的。就像徐博士之前提到的,分词没有一个“放之四海而皆准”的标准;那么在出门问问NLP里面,我们应用分词的一个很重要标准就是能够正确切出这些实体名称。
我们的分词相当依赖实体词表,但在实际中遇到了非常大的困难。
一是实体词表数据量大。比如光是POI点(信息点)就是千万级别,而且总有新开的餐馆、酒店无法覆盖到。
二是噪音很大。什么“我爱你”、“天气不错”,都是我们在真实词表中发现的餐馆名,更别说千奇百怪的歌名了。
这些真实世界的问题对统计系统的分词造成了很大的困难。所以我们针对这些问题,做过一些努力。
1) 建立完善的新词发现机制,定期补充我们的POI词,尽可能建立更多更全的实体词表库。但是更多的实体词表也带来了更多的噪音,会对分词和后续语义识别造成问题。
2)我们会利用机器学习的方法,来剔除实体词表中的噪音词。所谓的噪音词,就是餐馆词表里面那些一般人看起来不是“餐馆”的词(比如“我爱你”“天气不错”),或者歌曲名里面一般来说不会被认为是歌曲的词(比如“附近”),等等。我们的算法会自动筛选出这种低置信度的实体词,避免造成噪音。
3)我们还尝试过连接Knowledge Graph,用更丰富的信息来帮助正确分词。举一个真实的例子,“高第街56号”,一般的分词程序都会分为“高第街/56/号”,但是群里面如果有济南的朋友可能会一眼认出来,这是济南一家非常著名的连锁餐馆的名称。结合我们的Knowledge Grahp (KG),如果用户的当前地址在济南,那么即使我们的除噪音的算法认为“高第街56号”不太可能是一家餐馆,但是我们会综合考虑KG给出的信息,将其正确识别成为一家餐馆。
同时,我们也在积极的尝试一些新的方法,比如接受多种存在歧义的分词,但是采用对最终搜索结果的评估来排序选出最佳答案。当然啦,整体的中文分词的效果还是可以接受的。经过我们抽样错误分析,分词造成的语义分析错,占得比例还是比较低的,长期来讲我们仍然会一直信任当前的分词系统提供的结果。
小结:
中文分词是NLP难题中的一道必然工序,最近因为深度学习的到来,很多人开始希冀这个新的机器学习算法可以为它带来一些全新的东西。本文出门问问的两个资深研究人员从什么是中文分词、中文分词的传统方法、中文分词结合深度学习以及中文分词在语义分析中的应用,在他们产品实际应用中遇到的问题,为我们由浅入深、从理论到应用做了一堂生动地科普,向我们展示了中文分词和商业产品真正结合时的美妙碰撞。
附:徐博士参考文献。
Peng et al. 2002, Investigating the relationship between word segmentation performance and retrieval performance in Chinese IR
Gao et al. 2005, Chinese word segmentation and named entity recognition: A pragmatic approach
Chang et al. 2008, Optimizing Chinese Word Segmentation for Machine Translation Performance
Zhang & Clark 2007, Chinese Segmentation with a Word-Based Perceptron Algorithm
Sarawagi & Cohen 2004, Semi-Markov Conditional Random Fields for Information Extraction
Andrew 2006, A hybrid markov/semi-markov conditional random field for sequence segmentation
Collobert & Weston 2008, A Unified Architecture for Natural Language Processing: Deep Neural Networks with Multitask Learning
Zheng et al. 2013, Deep learning for Chinese word segmentation and POS tagging
Pei et al 2014, Maxmargin tensor neural network for chinese word segmentation
Chen et al. 2015, Gated recursive neural network for chinese word segmentation
Chen et al. 2015, Long short-term memory neural networks for chinese word segmentation
Yao et al. 2016, Bi-directional LSTM Recurrent Neural Network for Chinese Word Segmentation
Zhang et al. 2016, Transition-Based Neural Word Segmentation
Zhang & Clark 2010, A fast decoder for joint word segmentation and pos-tagging using a single discriminative model
Hatori et al. 2012, Incremental joint approach to word segmentation, pos tagging, and dependency parsing in chinese
Qian & Liu 2012, Joint Chinese Word Segmentation, POS Tagging and Parsing
Zhang et al. 2014, Character-Level Chinese Dependency Parsing
Lyu et al. 2016, Joint Word Segmentation, POS-Tagging and Syntactic Chunking
本文作者:宗仁
本文转自雷锋网禁止二次转载,原文链接