本文是机器阅读理解系列的第六篇文章,paper的题目是Dynamic Entity Representation with Max-pooling Improves Machine Reading,作者是来自日本东北大学的老师Sosuke Kobayashi,文章发表在NAACL HLT 2016。本文的代码开源在Github。
本文模型之前的模型都是用一个静态的向量来表示一个entity,与上下文没有关系。而本文最大的贡献在于提出了一种动态表示entity(Dynamic Entity Representation)的模型,根据不同的上下文对同样的entity有不同的表示。
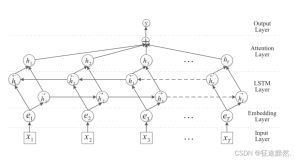
模型还是采用双向LSTM来构建,这时动态entity表示由四部分构成,包括两个方向上的hidden state,以及表示该entity所在句子的last hidden state,也就是该entity所在的上下文表示。如下图所示:
计算出entity的动态表示之后,通过attention mechanism计算得到query与每个entity之间的权重,然后计算每个entity在document和query条件下的概率,找到最终的answer。
query向量的计算与动态entity计算过程类似,这里需要填空的地方记作placeholder,也是包括四个部分,其中两个是表示placeholder上下文的last hidden state,另外两个是表示placeholder的hidden state。
模型的整个计算过程就是这样。如果遇到一个entity在document中出现多次的情况,该entity就会会有不同的表示,本文采用CNN中常用的max-pooling从各个表示中的每个维度获取最大的那一个组成该entity最终的表示,这个表示包括了该entity在document中各种context下的信息,具有最全面的信息,即原文中所说的accumulate information。如下图:
本文的实验在CNN数据上对模型进行了对比,效果比之前的Attentive Reader好很多,验证了本文的有效性。(当然结果没法和GA Reader比)
最后,作者给出了一个example,来说明用max-pooling的作用,见下图:
由于用了max-pooling模型比起不用它的话,可以关注到第二句和第三句话,因为本文模型可以捕捉到entity0(Downey)和entity2(Iron Man)是关联的(Robert Downey Jr.是Iron Man的扮演者),然后就会注意到entity2出现过的几个句子,而不仅仅是query中entity0出现过的几个句子,这一点帮助了模型找到了最终的正确答案entity26(在第二句中)。
本文模型的一个好玩之处在于用了一种变化的眼光和态度来审视每一个entity,不同的context会给同样的entity带来不同的意义,因此用一种动态的表示方法来捕捉原文中entity最准确的意思,才能更好地理解原文,找出正确答案。实际体会中,我们做阅读理解的时候,最简单的方法是从问题中找到关键词,然后从原文中找到同样的词所在的句子,然后仔细理解这个句子最终得到答案,这种难度的阅读理解可能是四、六级的水平,再往高一个level的题目,就需要你联系上下文,联系关键词相关联的词或者句子来理解原文,而不是简单地只找到一个句子就可以答对题目。本文的动态表示正是有意在更加复杂的阅读理解题目上做文章,是一个非常好的探索。
另外,如何衡量阅读理解语料中题目的难度?是否可以按难度分类进行对比测试?如果说现在最好的系统可以做到75%左右的正确率,是否可以给出一些更加有难度的题目来做?比如英语考试中真正的阅读理解或者完形填空。不同的模型具有不同的特点,可以考虑用不同难度的题目来验证模型的适用性。
本文是这个系列文章在本周的最后一篇单文,周末的时间会整理出本周分享的模型的思路、研究动机和实验结果等各个方面来写一篇综述文章,对机器阅读理解这个点进行一个较系统地总结,敬请期待!(后续还会继续关注这个方向,读更多的paper来分享)
来源:paperweekly