热门
提升团队工程交付能力,从“看见”工程活动和研发模式开始
阿里云实时计算Flink的产品化思考与实践【下】
社区供稿 | FunASR 语音大模型在 Arm Neoverse 平台上的优化实践
更优性能与性价比,从自建 ELK 迁移到 SLS 开始
解放配置之道:Spring引入外部属性文件
公钥密码学:解密加密的魔法世界
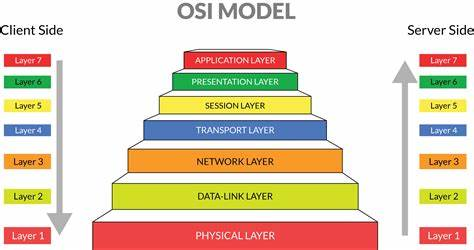
深入剖析:OSI模型解密
TCP IP协议簇:网络通信的基石
数字藏品开发原理丨鲸探幻核数字藏品系统开发功能分析
深入探讨MySQL中Varchar(50)和Varchar(500)的区别
如何实现基于Redis的在线人数统计功能?
MySQL锁解密:读锁与写锁
解锁MySQL的奥秘:探究表级锁、行级锁和页级锁的神秘面纱
MySQL锁之较量:悲观锁与乐观锁的对决
MySQL锁:解析隐式锁与显式锁
MySQL锁之权谋较量:共享锁、排它锁、独占锁的角逐
Spring Boot与Flowable的完美整合
Spring Boot接收参数的多种方式
如何处理大文件上传
数据库之魅:MySQL表设计的艺术与技巧
财务计算中的金额数据类型选择:Long还是BigDecimal?
PXE+Kickstart实现rocky9批量自动装机
sqlserver死锁排查
【java基础】File操作详解
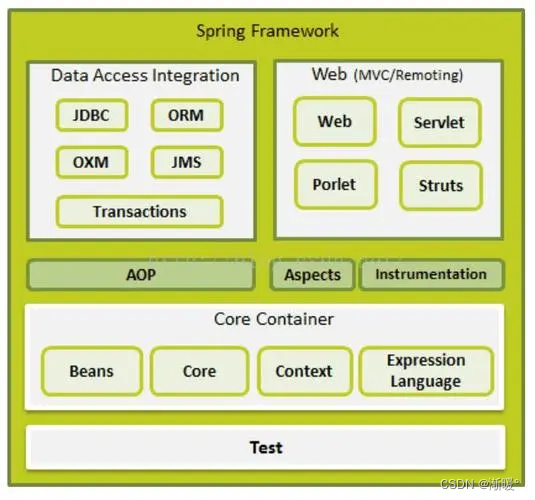
spring学习笔记之核心理念(一)
eclipse安装教程
【POI】常用excel操作方法
【java】树形结构分页(真分页)
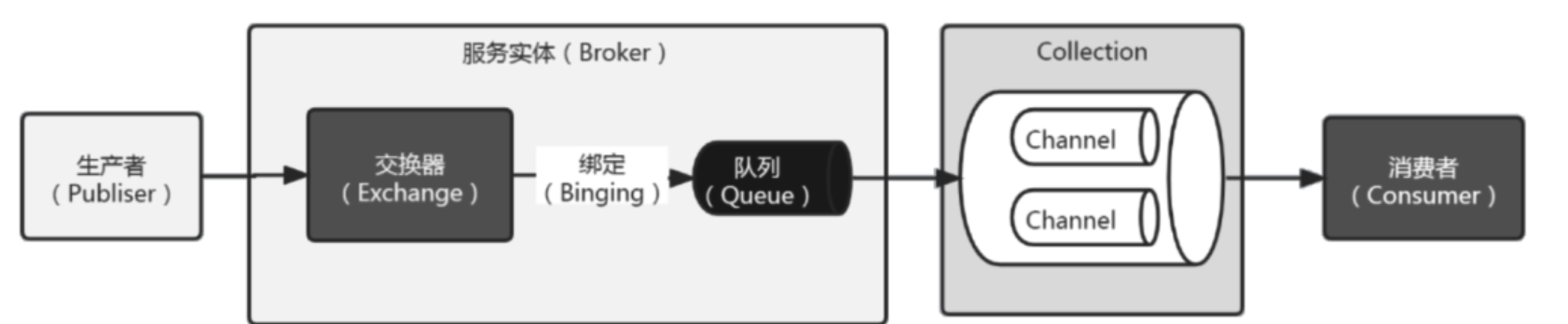
RabbitMQ组件介绍
【java常用】数据类型转换
IDEA必备快捷键
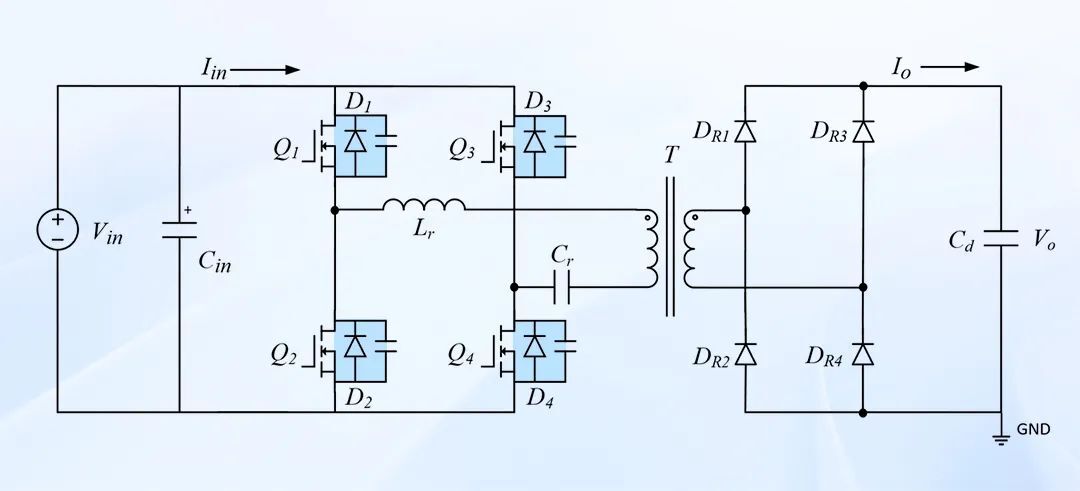
LC串联谐振拓扑仿真建模
支持私有部署的云端存储双链笔记软件
项目常见错误速查
探索现代微服务架构的最佳实践
如何指定域名写入token
如何将一个linux服务器挂载到另外一个linux服务器上
探索深度学习在图像识别中的应用与挑战
字符串和list互转
【docker】记录一次nginx启动失败的检测
深入理解操作系统中的进程调度策略
【java】RTF转HTML或者TEXT
docker部署kafka
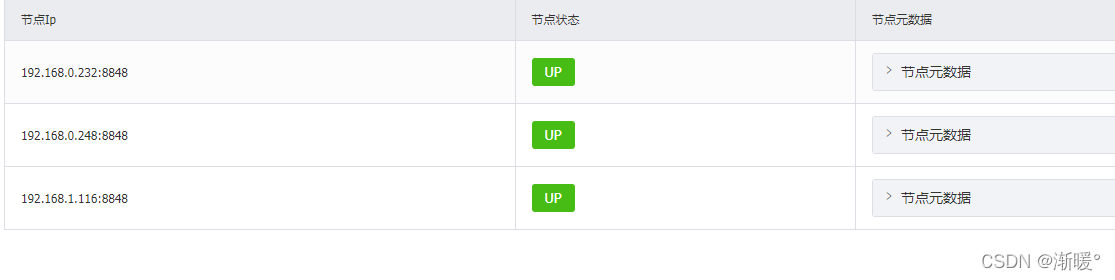
【微服务】生产部署nacos集群(三个节点)
docker常用命令docker常用命令
docker部署nacos集群
【消息中心】docker部署kafka
效率工具RunFlow完全手册之Java开发者篇
常用sql记录
除非另外还指定了 TOP、OFFSET 或 FOR XML,否则,ORDER BY 子句在视图、内联函数、派生表、子查询和公用表表达式中无效